 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Priori Uncertainty Quantification of Reacting Turbulence Closure Models using Bayesian Neural Networks
Feb 28, 2024While many physics-based closure model forms have been posited for the sub-filter scale (SFS) in large eddy simulation (LES), vast amounts of data available from direct numerical simulation (DNS) create opportunities to leverage data-driven modeling techniques. Albeit flexible, data-driven models still depend on the dataset and the functional form of the model chosen. Increased adoption of such models requires reliable uncertainty estimates both in the data-informed and out-of-distribution regimes. In this work, we employ Bayesian neural networks (BNNs) to capture both epistemic and aleatoric uncertainties in a reacting flow model. In particular, we model the filtered progress variable scalar dissipation rate which plays a key role in the dynamics of turbulent premixed flames. We demonstrate that BNN models can provide unique insights about the structure of uncertainty of the data-driven closure models. We also propose a method for the incorporation of out-of-distribution information in a BNN. The efficacy of the model is demonstrated by a priori evaluation on a dataset consisting of a variety of flame conditions and fuels.
Variational Auto-Encoder Based Deep Learning Technique For Filling Gaps in Reacting PIV Data
Dec 11, 2023In this study, a deep learning based conditional density estimation technique known as conditional variational auto-encoder (CVAE) is used to fill gaps typically observed in particle image velocimetry (PIV) measurements in combustion systems. The proposed CVAE technique is trained using time resolved gappy PIV fields, typically observed in industrially relevant combustors. Stereo-PIV (SPIV) data from a swirl combustor with very a high vector yield is used to showcase the accuracy of the proposed CVAE technique. Various error metrics evaluated on the reconstructed velocity field in the gaps are presented from data sets corresponding to three sets of combustor operating conditions. In addition to accurate data reproduction, the proposed CVAE technique offers data compression by reducing the latent space dimension, enabling the efficient processing of large-scale PIV data.
Uniform-in-Phase-Space Data Selection with Iterative Normalizing Flows
Dec 28, 2021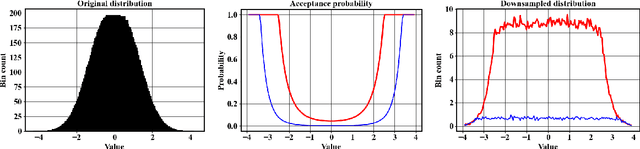

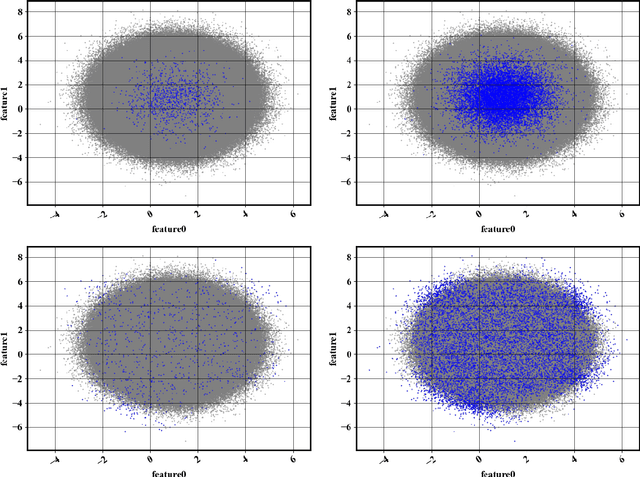

Improvements in computational and experimental capabilities are rapidly increasing the amount of scientific data that is routinely generated. In applications that are constrained by memory and computational intensity, excessively large datasets may hinder scientific discovery, making data reduction a critical component of data-driven methods. Datasets are growing in two directions: the number of data points and their dimensionality. Whereas data compression techniques are concerned with reducing dimensionality, the focus here is on reducing the number of data points. A strategy is proposed to select data points such that they uniformly span the phase-space of the data. The algorithm proposed relies on estimating the probability map of the data and using it to construct an acceptance probability. An iterative method is used to accurately estimate the probability of the rare data points when only a small subset of the dataset is used to construct the probability map. Instead of binning the phase-space to estimate the probability map, its functional form is approximated with a normalizing flow. Therefore, the method naturally extends to high-dimensional datasets. The proposed framework is demonstrated as a viable pathway to enable data-efficient machine learning when abundant data is available. An implementation of the method is available in a companion repository (https://github.com/NREL/Phase-space-sampling).