 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniform-in-Phase-Space Data Selection with Iterative Normalizing Flows
Dec 28, 2021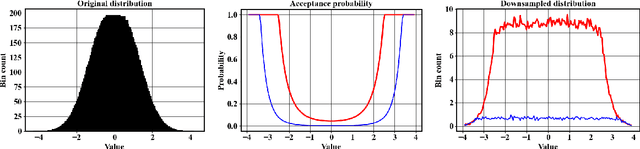

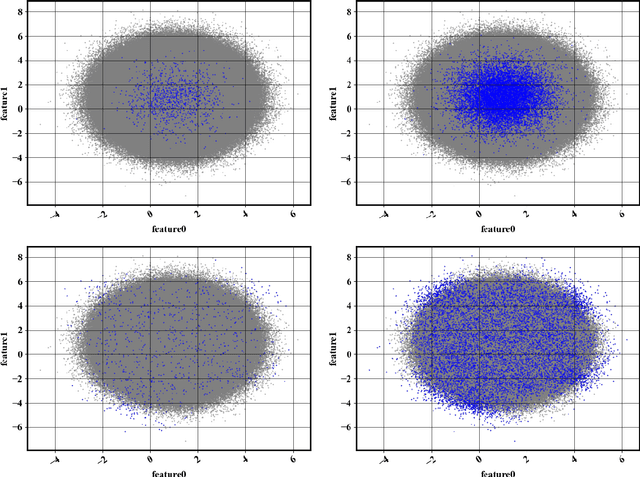

Improvements in computational and experimental capabilities are rapidly increasing the amount of scientific data that is routinely generated. In applications that are constrained by memory and computational intensity, excessively large datasets may hinder scientific discovery, making data reduction a critical component of data-driven methods. Datasets are growing in two directions: the number of data points and their dimensionality. Whereas data compression techniques are concerned with reducing dimensionality, the focus here is on reducing the number of data points. A strategy is proposed to select data points such that they uniformly span the phase-space of the data. The algorithm proposed relies on estimating the probability map of the data and using it to construct an acceptance probability. An iterative method is used to accurately estimate the probability of the rare data points when only a small subset of the dataset is used to construct the probability map. Instead of binning the phase-space to estimate the probability map, its functional form is approximated with a normalizing flow. Therefore, the method naturally extends to high-dimensional datasets. The proposed framework is demonstrated as a viable pathway to enable data-efficient machine learning when abundant data is available. An implementation of the method is available in a companion repository (https://github.com/NREL/Phase-space-sampling).