 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSleep Staging from Airflow Signals Using Fourier Approximations of Persistence Curves
Nov 12, 2024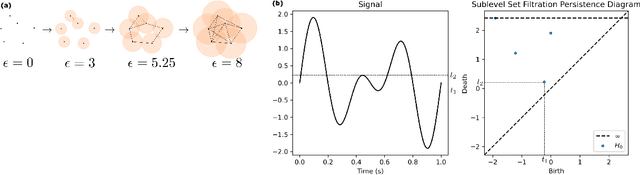
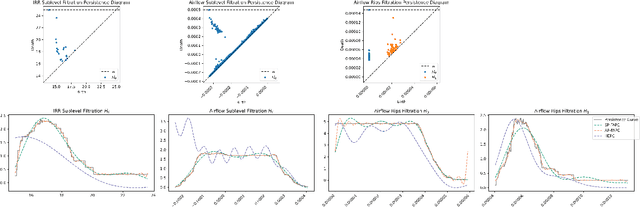
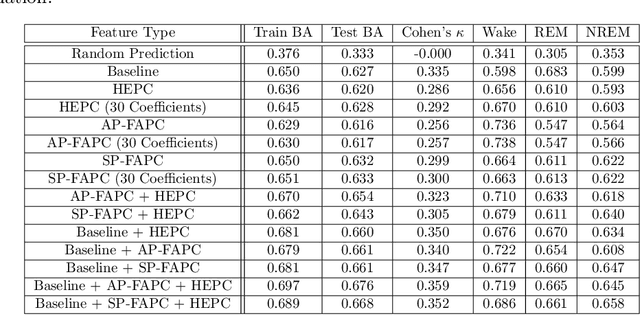
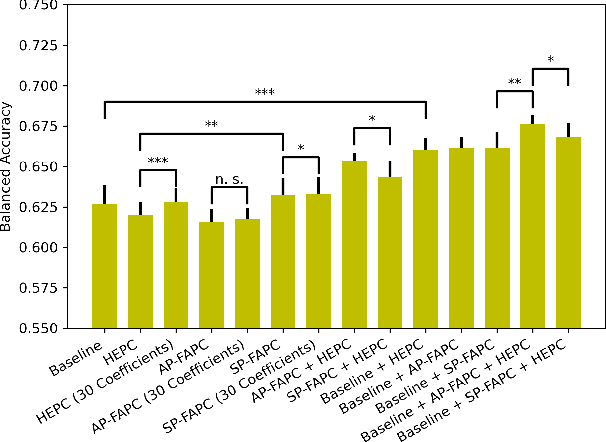
Sleep staging is a challenging task, typically manually performed by sleep technologists based on electroencephalogram and other biosignals of patients taken during overnight sleep studies. Recent work aims to leverage automated algorithms to perform sleep staging not based on electroencephalogram signals, but rather based on the airflow signals of subjects. Prior work uses ideas from topological data analysis (TDA), specifically Hermite function expansions of persistence curves (HEPC) to featurize airflow signals. However, finite order HEPC captures only partial information. In this work, we propose Fourier approximations of persistence curves (FAPC), and use this technique to perform sleep staging based on airflow signals. We analyze performance using an XGBoost model on 1155 pediatric sleep studies taken from the Nationwide Children's Hospital Sleep DataBank (NCHSDB), and find that FAPC methods provide complimentary information to HEPC methods alone, leading to a 4.9% increase in performance over baseline methods.
Detection of Sleep Oxygen Desaturations from Electroencephalogram Signals
May 08, 2024
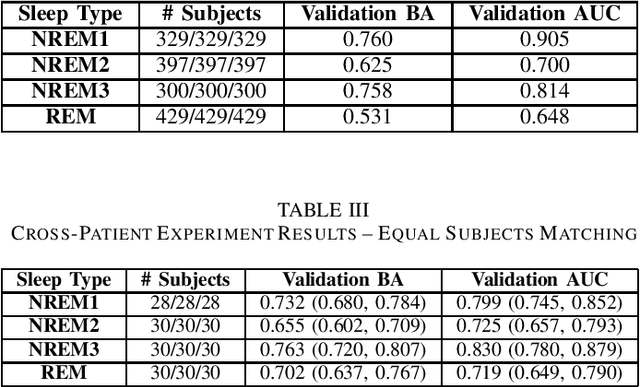
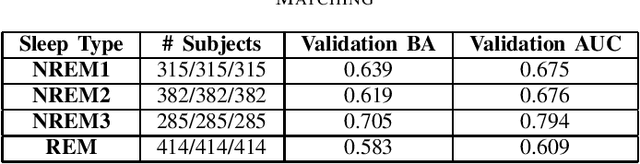

In this work, we leverage machine learning techniques to identify potential biomarkers of oxygen desaturation during sleep exclusively from electroencephalogram (EEG) signals in pediatric patients with sleep apnea. Development of a machine learning technique which can successfully identify EEG signals from patients with sleep apnea as well as identify latent EEG signals which come from subjects who experience oxygen desaturations but do not themselves occur during oxygen desaturation events would provide a strong step towards developing a brain-based biomarker for sleep apnea in order to aid with easier diagnosis of this disease. We leverage a large corpus of data, and show that machine learning enables us to classify EEG signals as occurring during oxygen desaturations or not occurring during oxygen desaturations with an average 66.8% balanced accuracy. We furthermore investigate the ability of machine learning models to identify subjects who experience oxygen desaturations from EEG data that does not occur during oxygen desaturations. We conclude that there is a potential biomarker for oxygen desaturation in EEG data.
Improving the Performance of Fine-Grain Image Classifiers via Generative Data Augmentation
Aug 12, 2020

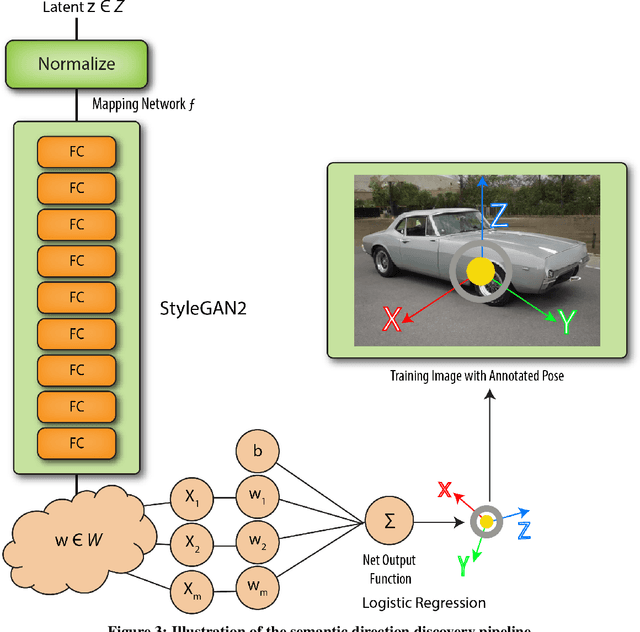

Recent advances in machine learning (ML) and computer vision tools have enabled applications in a wide variety of arenas such as financial analytics, medical diagnostics, and even within the Department of Defense. However, their widespread implementation in real-world use cases poses several challenges: (1) many applications are highly specialized, and hence operate in a \emph{sparse data} domain; (2) ML tools are sensitive to their training sets and typically require cumbersome, labor-intensive data collection and data labelling processes; and (3) ML tools can be extremely "black box," offering users little to no insight into the decision-making process or how new data might affect prediction performance. To address these challenges, we have designed and developed Data Augmentation from Proficient Pre-Training of Robust Generative Adversarial Networks (DAPPER GAN), an ML analytics support tool that automatically generates novel views of training images in order to improve downstream classifier performance. DAPPER GAN leverages high-fidelity embeddings generated by a StyleGAN2 model (trained on the LSUN cars dataset) to create novel imagery for previously unseen classes. We experimentally evaluate this technique on the Stanford Cars dataset, demonstrating improved vehicle make and model classification accuracy and reduced requirements for real data using our GAN based data augmentation framework. The method's validity was supported through an analysis of classifier performance on both augmented and non-augmented datasets, achieving comparable or better accuracy with up to 30\% less real data across visually similar classes. To support this method, we developed a novel augmentation method that can manipulate semantically meaningful dimensions (e.g., orientation) of the target object in the embedding space.