 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Performance of Fine-Grain Image Classifiers via Generative Data Augmentation
Aug 12, 2020

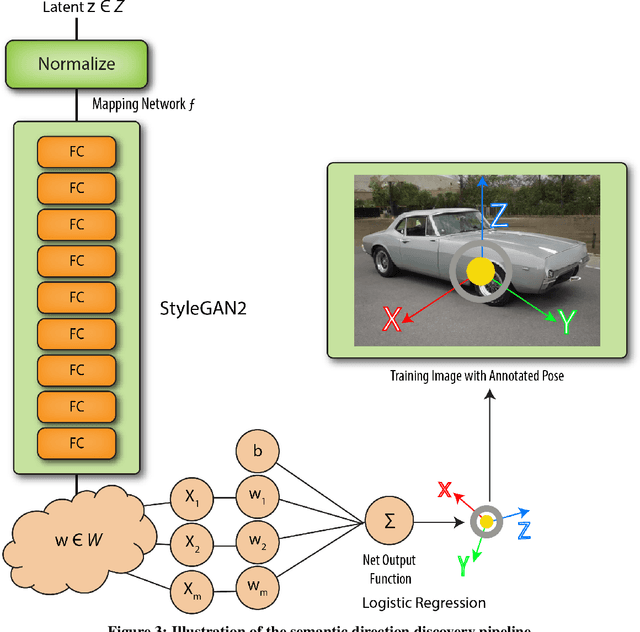

Recent advances in machine learning (ML) and computer vision tools have enabled applications in a wide variety of arenas such as financial analytics, medical diagnostics, and even within the Department of Defense. However, their widespread implementation in real-world use cases poses several challenges: (1) many applications are highly specialized, and hence operate in a \emph{sparse data} domain; (2) ML tools are sensitive to their training sets and typically require cumbersome, labor-intensive data collection and data labelling processes; and (3) ML tools can be extremely "black box," offering users little to no insight into the decision-making process or how new data might affect prediction performance. To address these challenges, we have designed and developed Data Augmentation from Proficient Pre-Training of Robust Generative Adversarial Networks (DAPPER GAN), an ML analytics support tool that automatically generates novel views of training images in order to improve downstream classifier performance. DAPPER GAN leverages high-fidelity embeddings generated by a StyleGAN2 model (trained on the LSUN cars dataset) to create novel imagery for previously unseen classes. We experimentally evaluate this technique on the Stanford Cars dataset, demonstrating improved vehicle make and model classification accuracy and reduced requirements for real data using our GAN based data augmentation framework. The method's validity was supported through an analysis of classifier performance on both augmented and non-augmented datasets, achieving comparable or better accuracy with up to 30\% less real data across visually similar classes. To support this method, we developed a novel augmentation method that can manipulate semantically meaningful dimensions (e.g., orientation) of the target object in the embedding space.