 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Backward Aggregation in GCN Training with Execution Path Preparing on GPUs
Apr 06, 2022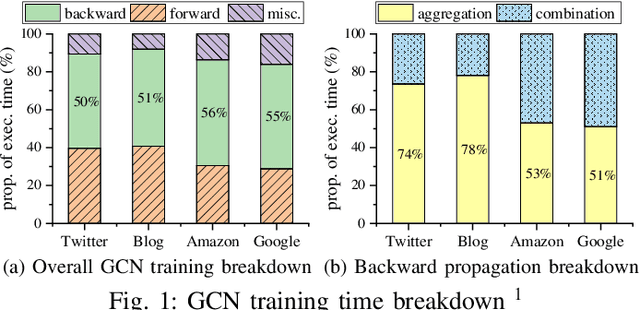
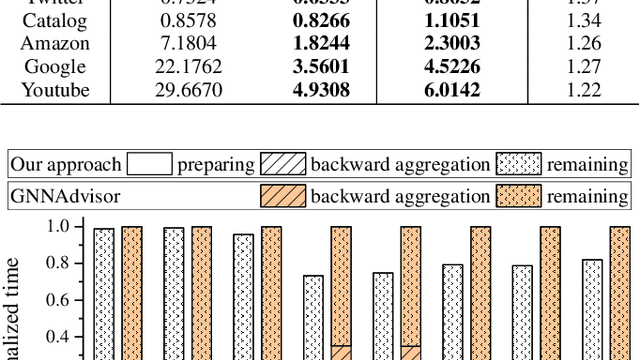


The emerging Graph Convolutional Network (GCN) has now been widely used in many domains, and it is challenging to improve the efficiencies of applications by accelerating the GCN trainings. For the sparsity nature and exploding scales of input real-world graphs, state-of-the-art GCN training systems (e.g., GNNAdvisor) employ graph processing techniques to accelerate the message exchanging (i.e. aggregations) among the graph vertices. Nevertheless, these systems treat both the aggregation stages of forward and backward propagation phases as all-active graph processing procedures that indiscriminately conduct computation on all vertices of an input graph. In this paper, we first point out that in a GCN training problem with a given training set, the aggregation stages of its backward propagation phase (called as backward aggregations in this paper) can be converted to partially-active graph processing procedures, which conduct computation on only partial vertices of the input graph. By leveraging such a finding, we propose an execution path preparing method that collects and coalesces the data used during backward propagations of GCN training conducted on GPUs. The experimental results show that compared with GNNAdvisor, our approach improves the performance of the backward aggregation of GCN trainings on typical real-world graphs by 1.48x~5.65x. Moreover, the execution path preparing can be conducted either before the training (during preprocessing) or on-the-fly with the training. When used during preprocessing, our approach improves the overall GCN training by 1.05x~1.37x. And when used on-the-fly, our approach improves the overall GCN training by 1.03x~1.35x.