 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeacher-Class Network: A Neural Network Compression Mechanism
Apr 07, 2020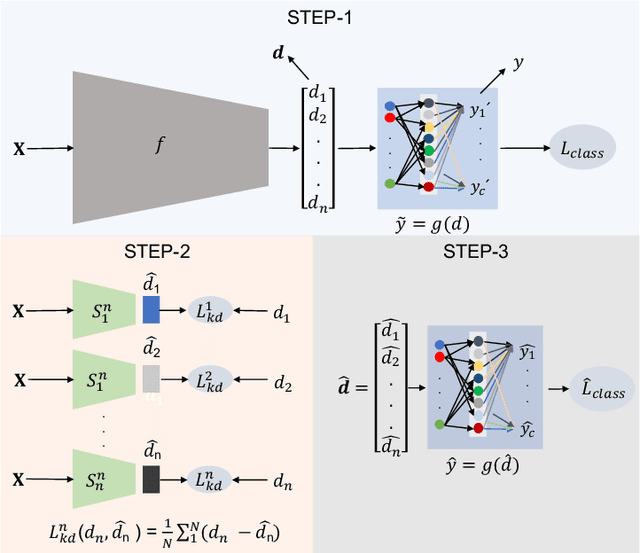
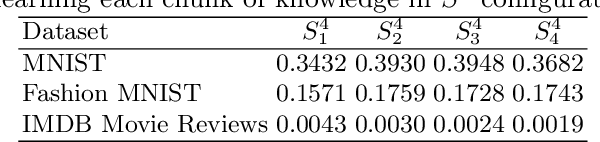
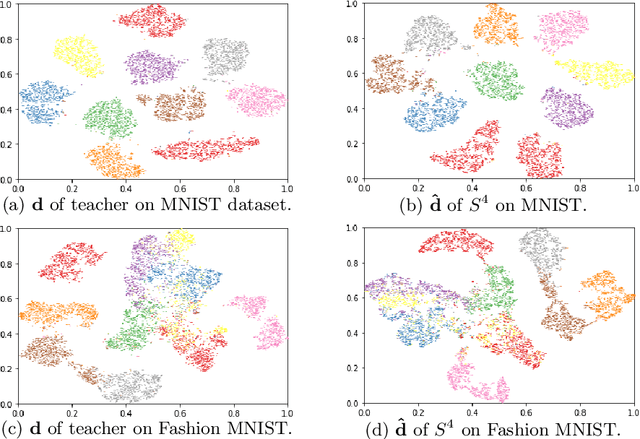
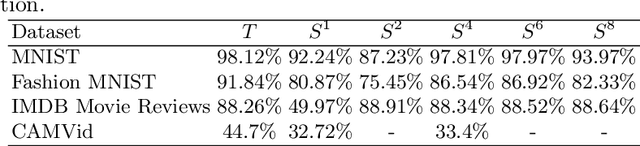
To solve the problem of the overwhelming size of Deep Neural Networks (DNN) several compression schemes have been proposed, one of them is teacher-student. Teacher-student tries to transfer knowledge from a complex teacher network to a simple student network. In this paper, we propose a novel method called a teacher-class network consisting of a single teacher and multiple student networks (i.e. class of students). Instead of transferring knowledge to one student only, the proposed method transfers a chunk of knowledge about the entire solution to each student. Our students are not trained for problem-specific logits, they are trained to mimic knowledge (dense representation) learned by the teacher network. Thus unlike the logits-based single student approach, the combined knowledge learned by the class of students can be used to solve other problems as well. These students can be designed to satisfy a given budget, e.g. for comparative purposes we kept the collective parameters of all the students less than or equivalent to that of a single student in the teacher-student approach . These small student networks are trained independently, making it possible to train and deploy models on memory deficient devices as well as on parallel processing systems such as data centers. The proposed teacher-class architecture is evaluated on several benchmark datasets including MNIST, FashionMNIST, IMDB Movie Reviews and CAMVid on multiple tasks including classification, sentiment classification and segmentation. Our approach outperforms the state-of-the-art single student approach in terms of accuracy as well as computational cost and in many cases it achieves an accuracy equivalent to the teacher network while having 10-30 times fewer parameters.