 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Multi-Output Regression Ranking
Sep 27, 2021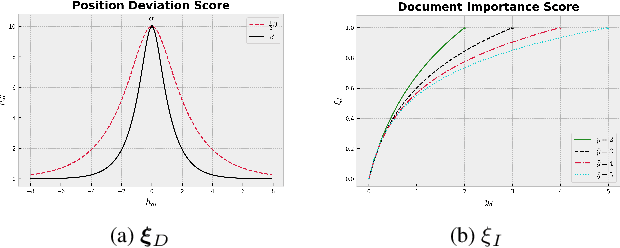
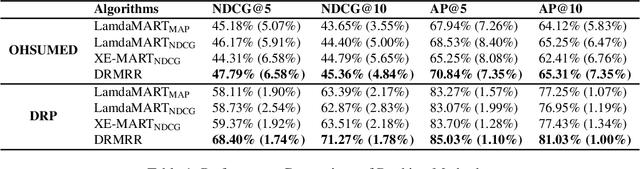

Despite their empirical success, most existing listwiselearning-to-rank (LTR) models are not built to be robust to errors in labeling or annotation, distributional data shift, or adversarial data perturbations. To fill this gap, we introduce a new listwise LTR model called Distributionally Robust Multi-output Regression Ranking (DRMRR). Different from existing methods, the scoring function of DRMRR was designed as a multivariate mapping from a feature vector to a vector of deviation scores, which captures local context information and cross-document interactions. DRMRR uses a Distributionally Robust Optimization (DRO) framework to minimize a multi-output loss function under the most adverse distributions in the neighborhood of the empirical data distribution defined by a Wasserstein ball. We show that this is equivalent to a regularized regression problem with a matrix norm regularizer. Our experiments were conducted on two real-world applications, medical document retrieval, and drug response prediction, showing that DRMRR notably outperforms state-of-the-art LTR models. We also conducted a comprehensive analysis to assess the resilience of DRMRR against various types of noise: Gaussian noise, adversarial perturbations, and label poisoning. We show that DRMRR is not only able to achieve significantly better performance than other baselines, but it can maintain a relatively stable performance as more noise is added to the data.
Fuzzy Expert Systems for Prediction of ICU Admission in Patients with COVID-19
Apr 22, 2021



The pandemic COVID-19 disease has had a dramatic impact on almost all countries around the world so that many hospitals have been overwhelmed with Covid-19 cases. As medical resources are limited, deciding on the proper allocation of these resources is a very crucial issue. Besides, uncertainty is a major factor that can affect decisions, especially in medical fields. To cope with this issue, we use fuzzy logic (FL) as one of the most suitable methods in modeling systems with high uncertainty and complexity. We intend to make use of the advantages of FL in decisions on cases that need to treat in ICU. In this study, an interval type-2 fuzzy expert system is proposed for prediction of ICU admission in COVID-19 patients. For this prediction task, we also developed an adaptive neuro-fuzzy inference system (ANFIS). Finally, the results of these fuzzy systems are compared to some well-known classification methods such as Naive Bayes (NB), Case-Based Reasoning (CBR), Decision Tree (DT), and K Nearest Neighbor (KNN). The results show that the type-2 fuzzy expert system and ANFIS models perform competitively in terms of accuracy and F-measure compared to the other system modeling techniques.
Interval Type-2 Enhanced Possibilistic Fuzzy C-Means Clustering for Gene Expression Data Analysis
Jan 01, 2021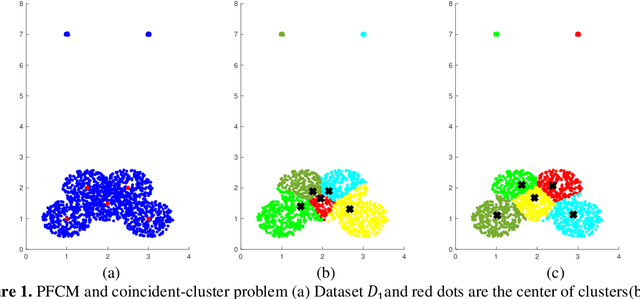

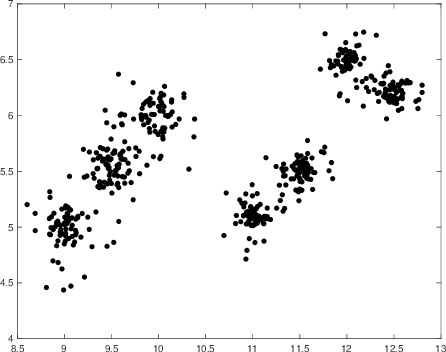
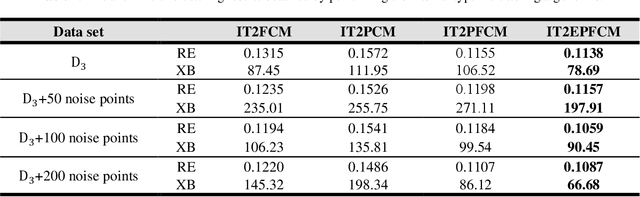
Both FCM and PCM clustering methods have been widely applied to pattern recognition and data clustering. Nevertheless, FCM is sensitive to noise and PCM occasionally generates coincident clusters. PFCM is an extension of the PCM model by combining FCM and PCM, but this method still suffers from the weaknesses of PCM and FCM. In the current paper, the weaknesses of the PFCM algorithm are corrected and the enhanced possibilistic fuzzy c-means (EPFCM) clustering algorithm is presented. EPFCM can still be sensitive to noise. Therefore, we propose an interval type-2 enhanced possibilistic fuzzy c-means (IT2EPFCM) clustering method by utilizing two fuzzifiers $(m_1, m_2)$ for fuzzy memberships and two fuzzifiers $({\theta}_1, {\theta}_2)$ for possibilistic typicalities. Our computational results show the superiority of the proposed approaches compared with several state-of-the-art techniques in the literature. Finally, the proposed methods are implemented for analyzing microarray gene expression data.
A New Validity Index for Fuzzy-Possibilistic C-Means Clustering
May 19, 2020
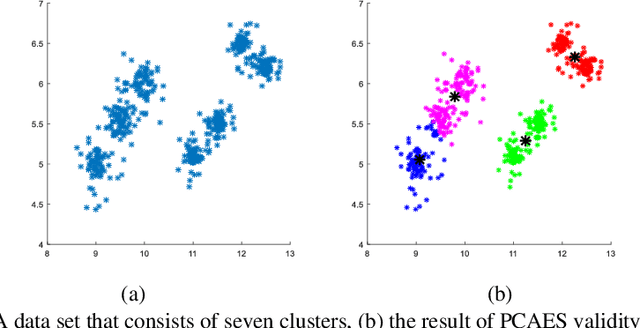
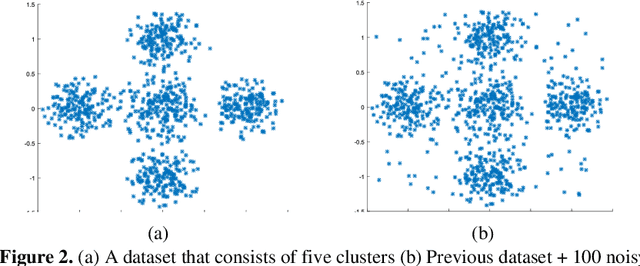
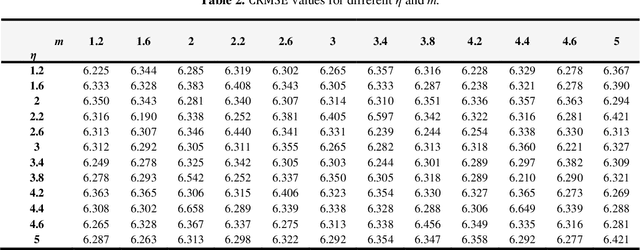
In some complicated datasets, due to the presence of noisy data points and outliers, cluster validity indices can give conflicting results in determining the optimal number of clusters. This paper presents a new validity index for fuzzy-possibilistic c-means clustering called Fuzzy-Possibilistic (FP) index, which works well in the presence of clusters that vary in shape and density. Moreover, FPCM like most of the clustering algorithms is susceptible to some initial parameters. In this regard, in addition to the number of clusters, FPCM requires a priori selection of the degree of fuzziness and the degree of typicality. Therefore, we presented an efficient procedure for determining their optimal values. The proposed approach has been evaluated using several synthetic and real-world datasets. Final computational results demonstrate the capabilities and reliability of the proposed approach compared with several well-known fuzzy validity indices in the literature. Furthermore, to clarify the ability of the proposed method in real applications, the proposed method is implemented in microarray gene expression data clustering and medical image segmentation.