 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Polar Code Construction for Successive Cancellation List Decoding: A Graph Neural Network-Based Approach
Jul 03, 2022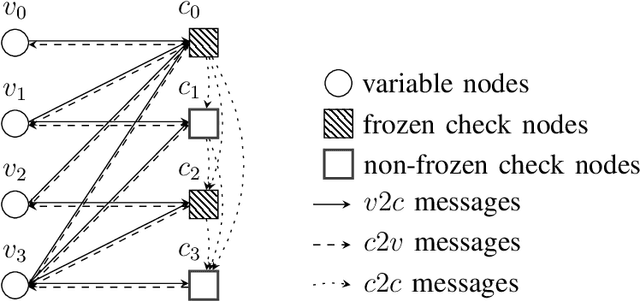
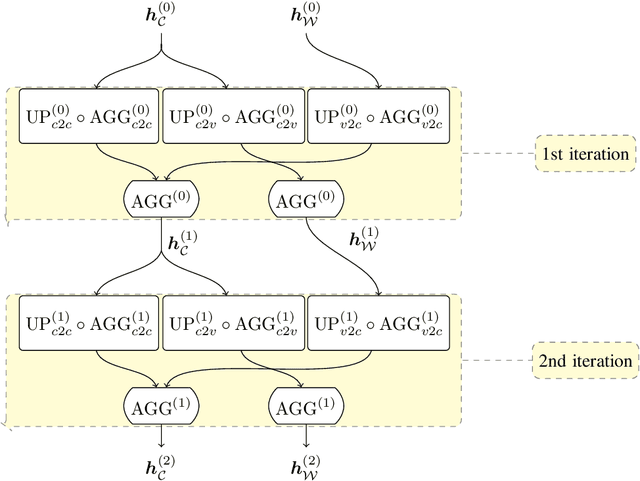
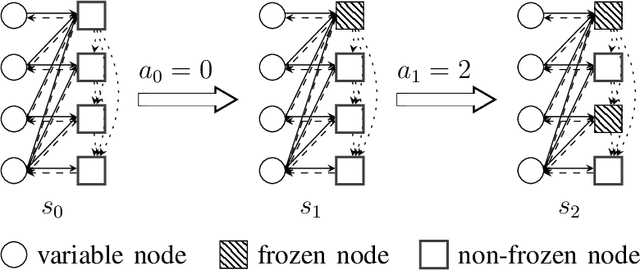
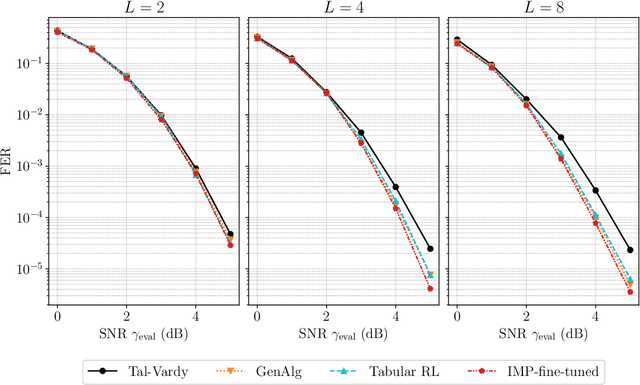
While constructing polar codes for successive-cancellation decoding can be implemented efficiently by sorting the bit-channels, finding optimal polar-code constructions for the successive-cancellation list (SCL) decoding in an efficient and scalable manner still awaits investigation. This paper proposes a graph neural network (GNN)-based reinforcement learning algorithm, named the iterative message-passing (IMP) algorithm, to solve the polar-code construction problem for SCL decoding. The algorithm operates only on the local structure of the graph induced by polar-code's generator matrix. The size of the IMP model is independent of the blocklength and the code rate, making it scalable to construct polar codes with long blocklengths. Moreover, a single trained IMP model can be directly applied to a wide range of target blocklengths, code rates, and channel conditions, and corresponding polar codes can be generated without separate training. Numerical experiments show that the IMP algorithm finds polar-code constructions that significantly outperform the classical constructions under cyclic-redundancy-check-aided SCL (CA-SCL) decoding. Compared to other learning-based construction methods tailored to SCL/CA-SCL decoding, the IMP algorithm constructs polar codes with comparable or lower frame error rates, while reducing the training complexity significantly by eliminating the need of separate training at each target blocklength, code rate, and channel condition.
Fast Successive-Cancellation List Flip Decoding of Polar Codes
Sep 25, 2021
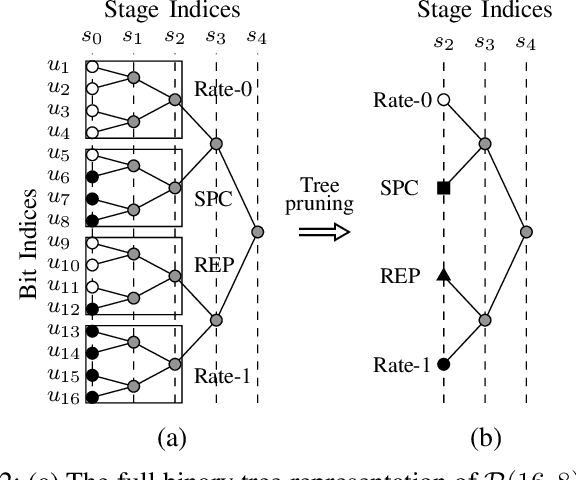


This work presents a fast successive-cancellation list flip (Fast-SCLF) decoding algorithm for polar codes that addresses the high latency issue associated with the successive-cancellation list flip (SCLF) decoding algorithm. We first propose a bit-flipping strategy tailored to the state-of-the-art fast successive-cancellation list (FSCL) decoding that avoids tree-traversal in the binary tree representation of SCLF, thus reducing the latency of the decoding process. We then derive a parameterized path-selection error model to accurately estimate the bit index at which the correct decoding path is eliminated from the initial FSCL decoding. The trainable parameter is optimized online based on an efficient supervised learning framework. Simulation results show that for a polar code of length 512 with 256 information bits, with similar error-correction performance and memory consumption, the proposed Fast-SCLF decoder reduces up to $73.4\%$ of the average decoding latency of the SCLF decoder with the same list size at the frame error rate of $10^{-4}$, while incurring a maximum computational overhead of $36.2\%$. For the same polar code of length 512 with 256 information bits and at practical signal-to-noise ratios, the proposed decoder with list size 4 reduces $89.1\%$ and $43.7\%$ of the average complexity and decoding latency of the FSCL decoder with list size 32 (FSCL-32), respectively, while also reducing $83.3\%$ of the memory consumption of FSCL-32. The significant improvements of the proposed decoder come at the cost of only $0.07$ dB error-correction performance degradation compared with FSCL-32.
Construction of Polar Codes with Reinforcement Learning
Sep 19, 2020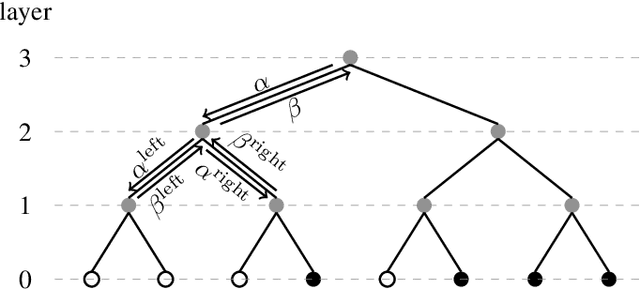
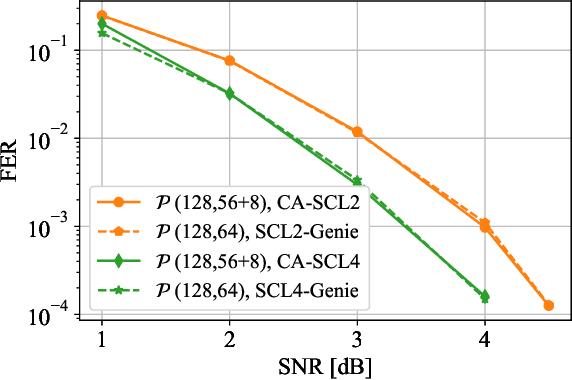
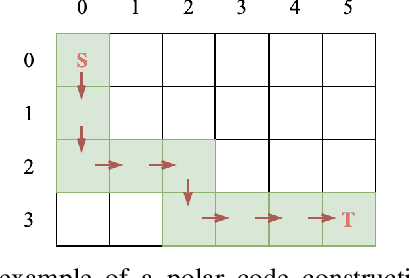
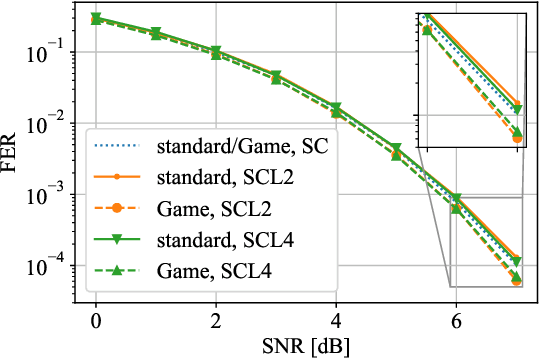
This paper formulates the polar-code construction problem for the successive-cancellation list (SCL) decoder as a maze-traversing game, which can be solved by reinforcement learning techniques. The proposed method provides a novel technique for polar-code construction that no longer depends on sorting and selecting bit-channels by reliability. Instead, this technique decides whether the input bits should be frozen in a purely sequential manner. The equivalence of optimizing the polar-code construction for the SCL decoder under this technique and maximizing the expected reward of traversing a maze is drawn. Simulation results show that the standard polar-code constructions that are designed for the successive-cancellation decoder are no longer optimal for the SCL decoder with respect to the frame error rate. In contrast, the simulations show that, with a reasonable amount of training, the game-based construction method finds code constructions that have lower frame-error rate for various code lengths and decoders compared to standard constructions.
Decoding Polar Codes with Reinforcement Learning
Sep 15, 2020
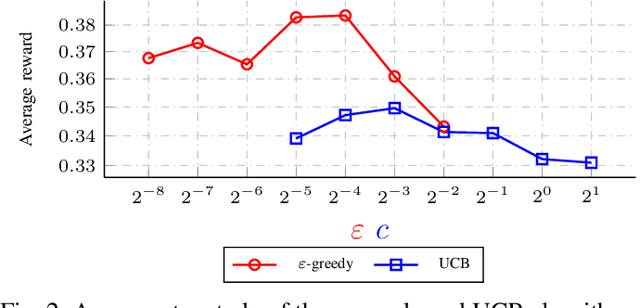
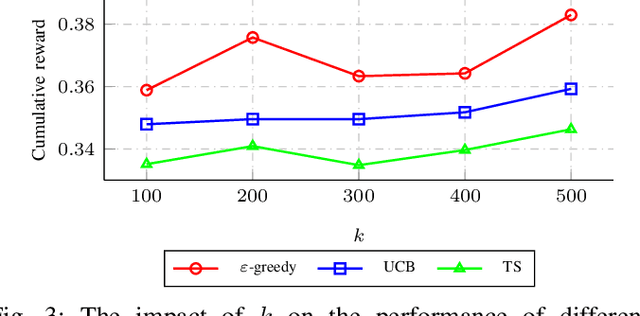
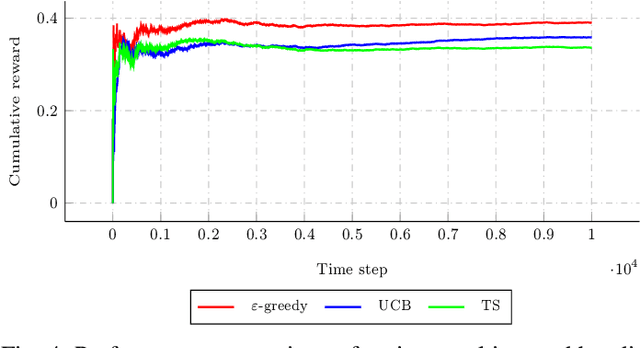
In this paper we address the problem of selecting factor-graph permutations of polar codes under belief propagation (BP) decoding to significantly improve the error-correction performance of the code. In particular, we formalize the factor-graph permutation selection as the multi-armed bandit problem in reinforcement learning and propose a decoder that acts like an online-learning agent that learns to select the good factor-graph permutations during the course of decoding. We use state-of-the-art algorithms for the multi-armed bandit problem and show that for a 5G polar codes of length 128 with 64 information bits, the proposed decoder has an error-correction performance gain of around 0.125 dB at the target frame error rate of 10^{-4}, when compared to the approach that randomly selects the factor-graph permutations.