 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain adaptation in small-scale and heterogeneous biological datasets
May 29, 2024Machine learning techniques are steadily becoming more important in modern biology, and are used to build predictive models, discover patterns, and investigate biological problems. However, models trained on one dataset are often not generalizable to other datasets from different cohorts or laboratories, due to differences in the statistical properties of these datasets. These could stem from technical differences, such as the measurement technique used, or from relevant biological differences between the populations studied. Domain adaptation, a type of transfer learning, can alleviate this problem by aligning the statistical distributions of features and samples among different datasets so that similar models can be applied across them. However, a majority of state-of-the-art domain adaptation methods are designed to work with large-scale data, mostly text and images, while biological datasets often suffer from small sample sizes, and possess complexities such as heterogeneity of the feature space. This Review aims to synthetically discuss domain adaptation methods in the context of small-scale and highly heterogeneous biological data. We describe the benefits and challenges of domain adaptation in biological research and critically discuss some of its objectives, strengths, and weaknesses through key representative methodologies. We argue for the incorporation of domain adaptation techniques to the computational biologist's toolkit, with further development of customized approaches.
"Task-relevant autoencoding" enhances machine learning for human neuroscience
Aug 17, 2022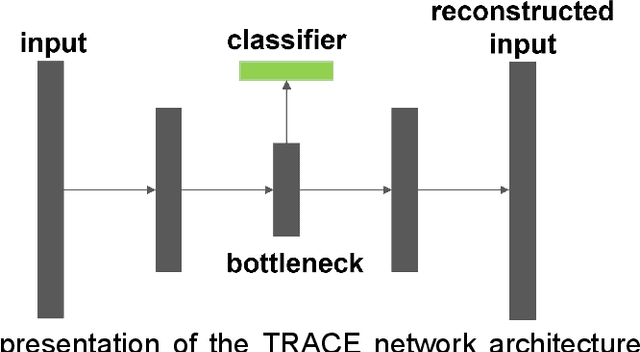
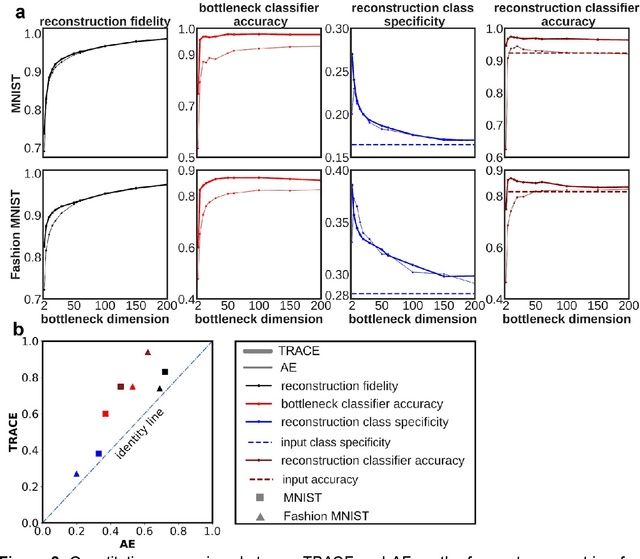
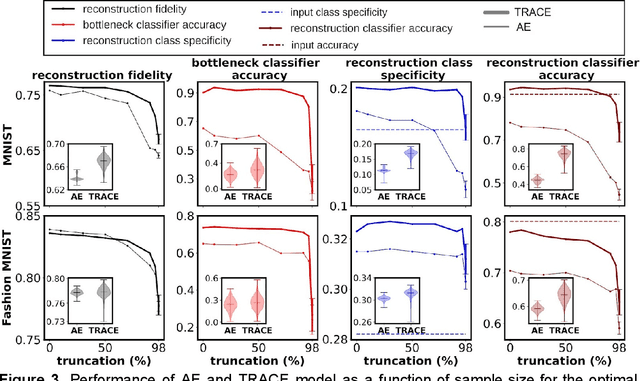

In human neuroscience, machine learning can help reveal lower-dimensional neural representations relevant to subjects' behavior. However, state-of-the-art models typically require large datasets to train, so are prone to overfitting on human neuroimaging data that often possess few samples but many input dimensions. Here, we capitalized on the fact that the features we seek in human neuroscience are precisely those relevant to subjects' behavior. We thus developed a Task-Relevant Autoencoder via Classifier Enhancement (TRACE), and tested its ability to extract behaviorally-relevant, separable representations compared to a standard autoencoder for two severely truncated machine learning datasets. We then evaluated both models on fMRI data where subjects observed animals and objects. TRACE outperformed both the autoencoder and raw inputs nearly unilaterally, showing up to 30% increased classification accuracy and up to threefold improvement in discovering "cleaner", task-relevant representations. These results showcase TRACE's potential for a wide variety of data related to human behavior.