 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructing an Interpretable Deep Denoiser by Unrolling Graph Laplacian Regularizer
Sep 10, 2024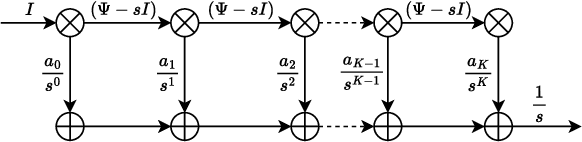
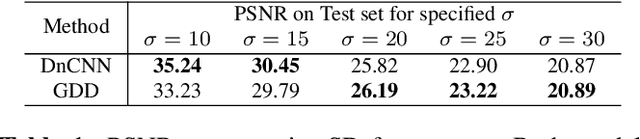

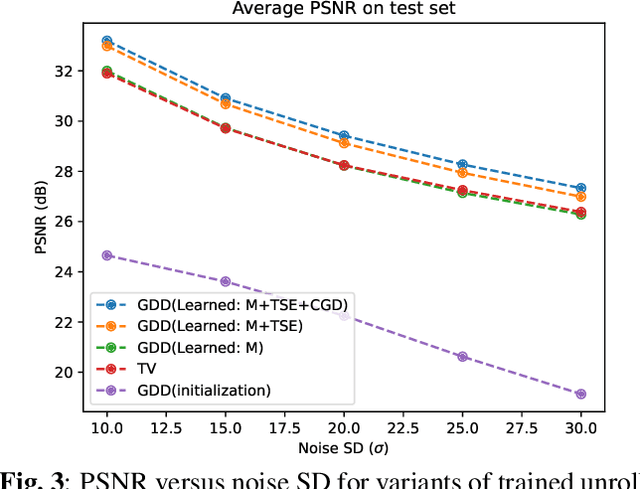
An image denoiser can be used for a wide range of restoration problems via the Plug-and-Play (PnP) architecture. In this paper, we propose a general framework to build an interpretable graph-based deep denoiser (GDD) by unrolling a solution to a maximum a posteriori (MAP) problem equipped with a graph Laplacian regularizer (GLR) as signal prior. Leveraging a recent theorem showing that any (pseudo-)linear denoiser $\boldsymbol \Psi$, under mild conditions, can be mapped to a solution of a MAP denoising problem regularized using GLR, we first initialize a graph Laplacian matrix $\mathbf L$ via truncated Taylor Series Expansion (TSE) of $\boldsymbol \Psi^{-1}$. Then, we compute the MAP linear system solution by unrolling iterations of the conjugate gradient (CG) algorithm into a sequence of neural layers as a feed-forward network -- one that is amenable to parameter tuning. The resulting GDD network is "graph-interpretable", low in parameter count, and easy to initialize thanks to $\mathbf L$ derived from a known well-performing denoiser $\boldsymbol \Psi$. Experimental results show that GDD achieves competitive image denoising performance compared to competitors, but employing far fewer parameters, and is more robust to covariate shift.
Interpretable Lightweight Transformer via Unrolling of Learned Graph Smoothness Priors
Jun 06, 2024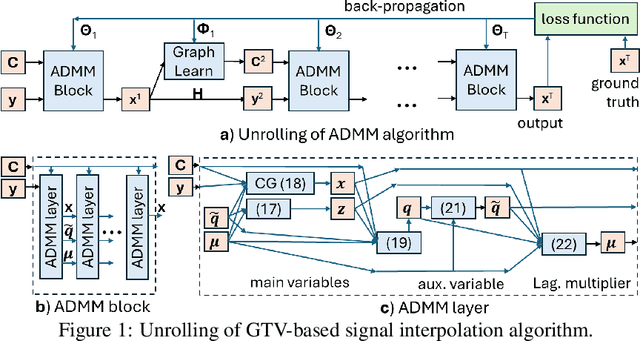
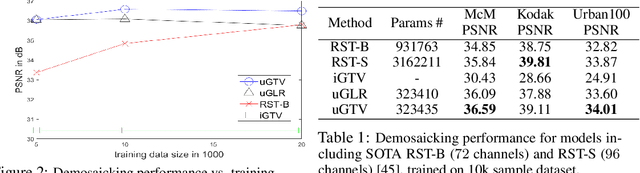


We build interpretable and lightweight transformer-like neural networks by unrolling iterative optimization algorithms that minimize graph smoothness priors -- the quadratic graph Laplacian regularizer (GLR) and the $\ell_1$-norm graph total variation (GTV) -- subject to an interpolation constraint. The crucial insight is that a normalized signal-dependent graph learning module amounts to a variant of the basic self-attention mechanism in conventional transformers. Unlike "black-box" transformers that require learning of large key, query and value matrices to compute scaled dot products as affinities and subsequent output embeddings, resulting in huge parameter sets, our unrolled networks employ shallow CNNs to learn low-dimensional features per node to establish pairwise Mahalanobis distances and construct sparse similarity graphs. At each layer, given a learned graph, the target interpolated signal is simply a low-pass filtered output derived from the minimization of an assumed graph smoothness prior, leading to a dramatic reduction in parameter count. Experiments for two image interpolation applications verify the restoration performance, parameter efficiency and robustness to covariate shift of our graph-based unrolled networks compared to conventional transformers.