 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePySS3: A Python package implementing a novel text classifier with visualization tools for Explainable AI
Dec 19, 2019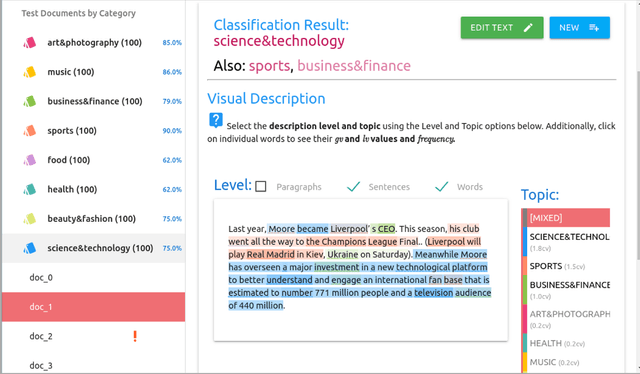

A recently introduced text classifier, called SS3, has obtained state-of-the-art performance on the CLEF's eRisk tasks. SS3 was created to deal with risk detection over text streams and therefore not only supports incremental training and classification but also can visually explain its rationale. However, little attention has been paid to the potential use of SS3 as a general classifier. We believe this could be due to the unavailability of an open-source implementation of SS3. In this work, we introduce PySS3, a package that not only implements SS3 but also comes with visualization tools that allow researchers deploying robust, explainable and trusty machine learning models for text classification.
t-SS3: a text classifier with dynamic n-grams for early risk detection over text streams
Nov 11, 2019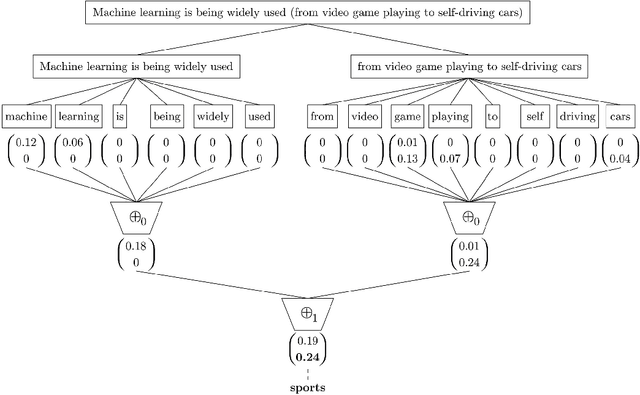
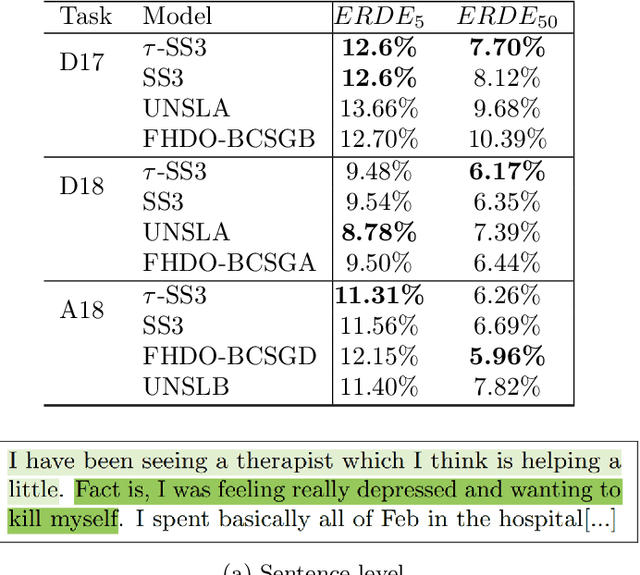
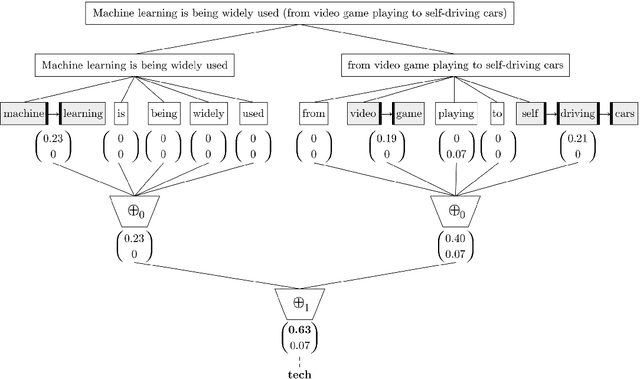
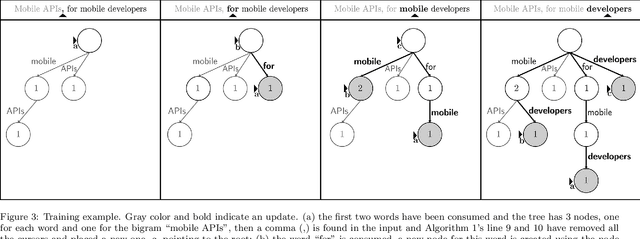
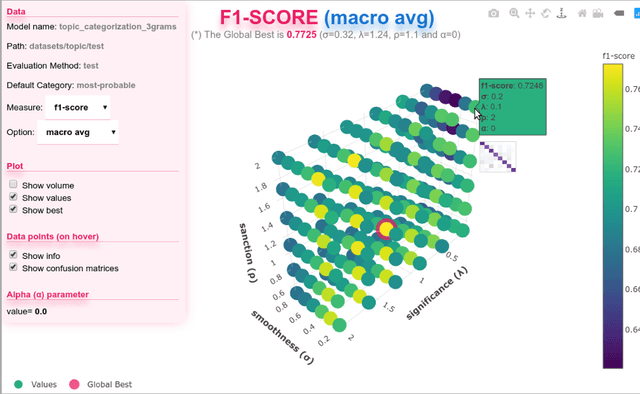
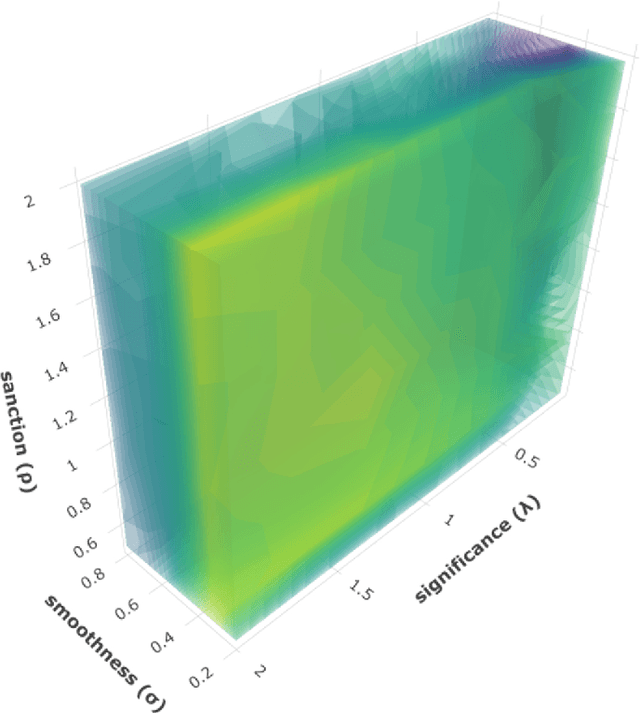
A recently introduced classifier, called SS3, has shown to be well suited to deal with early risk detection (ERD) problems on text streams. It obtained state-of-the-art performance on early depression and anorexia detection on Reddit in the CLEF's eRisk open tasks. SS3 was created to naturally deal with ERD problems since: it supports incremental training and classification over text streams and it can visually explain its rationale. However, SS3 processes the input using a bag-of-word model lacking the ability to recognize important word sequences. This could negatively affect the classification performance and also reduces the descriptiveness of visual explanations. In the standard document classification field, it is very common to use word n-grams to try to overcome some of these limitations. Unfortunately, when working with text streams, using n-grams is not trivial since the system must learn and recognize which n-grams are important ``on the fly''. This paper introduces t-SS3, a variation of SS3 which expands the model to dynamically recognize useful patterns over text streams. We evaluated our model on the eRisk 2017 and 2018 tasks on early depression and anorexia detection. Experimental results show that t-SS3 is able to improve both, existing results and the richness of visual explanations.
A Text Classification Framework for Simple and Effective Early Depression Detection Over Social Media Streams
May 18, 2019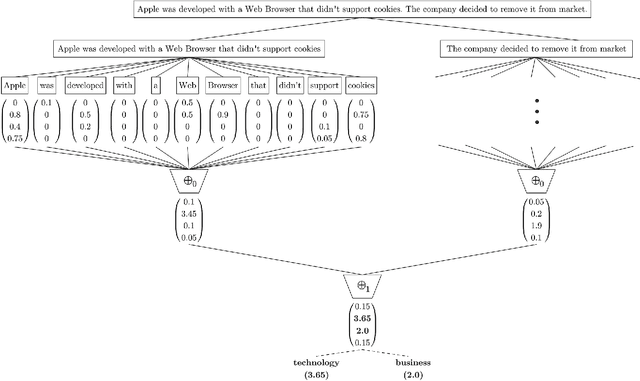
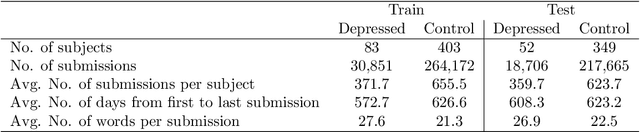
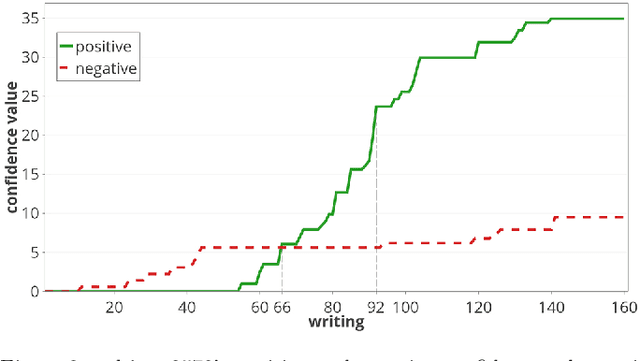
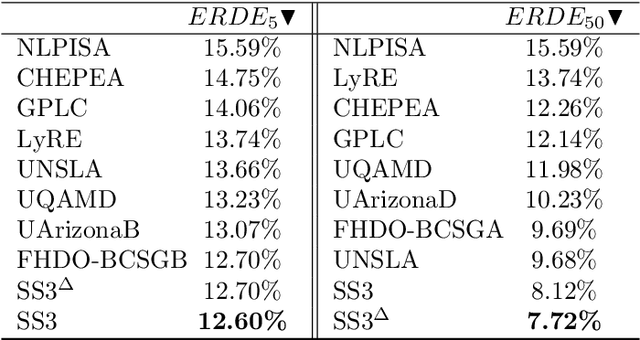
With the rise of the Internet, there is a growing need to build intelligent systems that are capable of efficiently dealing with early risk detection (ERD) problems on social media, such as early depression detection, early rumor detection or identification of sexual predators. These systems, nowadays mostly based on machine learning techniques, must be able to deal with data streams since users provide their data over time. In addition, these systems must be able to decide when the processed data is sufficient to actually classify users. Moreover, since ERD tasks involve risky decisions by which people's lives could be affected, such systems must also be able to justify their decisions. However, most standard and state-of-the-art supervised machine learning models (such as SVM, MNB, Neural Networks, etc.) are not well suited to deal with this scenario. This is due to the fact that they either act as black boxes or do not support incremental classification/learning. In this paper we introduce SS3, a novel supervised learning model for text classification that naturally supports these aspects. SS3 was designed to be used as a general framework to deal with ERD problems. We evaluated our model on the CLEF's eRisk2017 pilot task on early depression detection. Most of the 30 contributions submitted to this competition used state-of-the-art methods. Experimental results show that our classifier was able to outperform these models and standard classifiers, despite being less computationally expensive and having the ability to explain its rationale.
* Highlights: (*) A novel text classifier having the ability to visually explain its rationale; (*) Domain-independent classification that does not require feature engineering; (*) Support for incremental learning and text classification over streams; (*) Efficient framework for addressing early risk detection problems; (*) State-of-the-art performance on early depression detection task