 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal fine-tuning for early risk detection
May 16, 2025Early Risk Detection (ERD) on the Web aims to identify promptly users facing social and health issues. Users are analyzed post-by-post, and it is necessary to guarantee correct and quick answers, which is particularly challenging in critical scenarios. ERD involves optimizing classification precision and minimizing detection delay. Standard classification metrics may not suffice, resorting to specific metrics such as ERDE(theta) that explicitly consider precision and delay. The current research focuses on applying a multi-objective approach, prioritizing classification performance and establishing a separate criterion for decision time. In this work, we propose a completely different strategy, temporal fine-tuning, which allows tuning transformer-based models by explicitly incorporating time within the learning process. Our method allows us to analyze complete user post histories, tune models considering different contexts, and evaluate training performance using temporal metrics. We evaluated our proposal in the depression and eating disorders tasks for the Spanish language, achieving competitive results compared to the best models of MentalRiskES 2023. We found that temporal fine-tuning optimized decisions considering context and time progress. In this way, by properly taking advantage of the power of transformers, it is possible to address ERD by combining precision and speed as a single objective.
Hacia la interpretabilidad de la detección anticipada de riesgos de depresión utilizando grandes modelos de lenguaje
Mar 26, 2025Early Detection of Risks (EDR) on the Web involves identifying at-risk users as early as possible. Although Large Language Models (LLMs) have proven to solve various linguistic tasks efficiently, assessing their reasoning ability in specific domains is crucial. In this work, we propose a method for solving depression-related EDR using LLMs on Spanish texts, with responses that can be interpreted by humans. We define a reasoning criterion to analyze users through a specialist, apply in-context learning to the Gemini model, and evaluate its performance both quantitatively and qualitatively. The results show that accurate predictions can be obtained, supported by explanatory reasoning, providing a deeper understanding of the solution. Our approach offers new perspectives for addressing EDR problems by leveraging the power of LLMs.
* In Spanish language, In 30{\deg} Congreso Argentino de Ciencias de la Computaci\'on (CACIC 2024), La Plata, Argentina
A Time-Aware Approach to Early Detection of Anorexia: UNSL at eRisk 2024
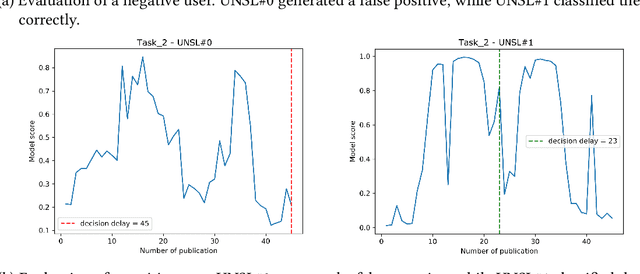
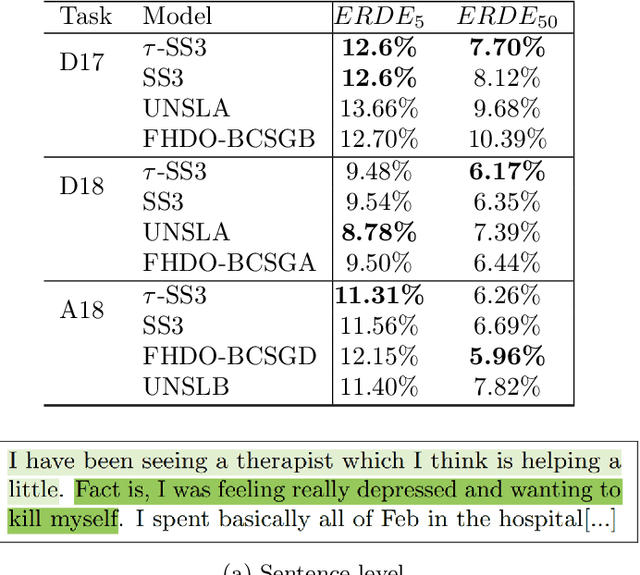
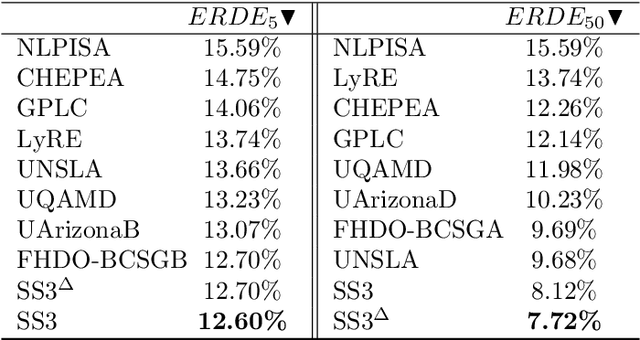
Oct 23, 2024The eRisk laboratory aims to address issues related to early risk detection on the Web. In this year's edition, three tasks were proposed, where Task 2 was about early detection of signs of anorexia. Early risk detection is a problem where precision and speed are two crucial objectives. Our research group solved Task 2 by defining a CPI+DMC approach, addressing both objectives independently, and a time-aware approach, where precision and speed are considered a combined single-objective. We implemented the last approach by explicitly integrating time during the learning process, considering the ERDE{\theta} metric as the training objective. It also allowed us to incorporate temporal metrics to validate and select the optimal models. We achieved outstanding results for the ERDE50 metric and ranking-based metrics, demonstrating consistency in solving ERD problems.
* In Conference and Labs of the Evaluation Forum (CLEF 2024), Grenoble, France
Early Detection of Depression and Eating Disorders in Spanish: UNSL at MentalRiskES 2023
Oct 30, 2023


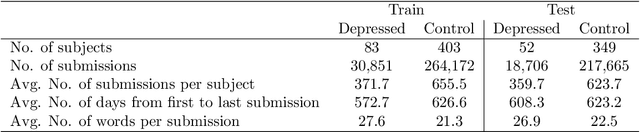
MentalRiskES is a novel challenge that proposes to solve problems related to early risk detection for the Spanish language. The objective is to detect, as soon as possible, Telegram users who show signs of mental disorders considering different tasks. Task 1 involved the users' detection of eating disorders, Task 2 focused on depression detection, and Task 3 aimed at detecting an unknown disorder. These tasks were divided into subtasks, each one defining a resolution approach. Our research group participated in subtask A for Tasks 1 and 2: a binary classification problem that evaluated whether the users were positive or negative. To solve these tasks, we proposed models based on Transformers followed by a decision policy according to criteria defined by an early detection framework. One of the models presented an extended vocabulary with important words for each task to be solved. In addition, we applied a decision policy based on the history of predictions that the model performs during user evaluation. For Tasks 1 and 2, we obtained the second-best performance according to rankings based on classification and latency, demonstrating the effectiveness and consistency of our approaches for solving early detection problems in the Spanish language.
* In Iberian Languages Evaluation Forum (IberLEF 2023), Ja\'en, Spain
Strategies to Harness the Transformers' Potential: UNSL at eRisk 2023
Oct 30, 2023The CLEF eRisk Laboratory explores solutions to different tasks related to risk detection on the Internet. In the 2023 edition, Task 1 consisted of searching for symptoms of depression, the objective of which was to extract user writings according to their relevance to the BDI Questionnaire symptoms. Task 2 was related to the problem of early detection of pathological gambling risks, where the participants had to detect users at risk as quickly as possible. Finally, Task 3 consisted of estimating the severity levels of signs of eating disorders. Our research group participated in the first two tasks, proposing solutions based on Transformers. For Task 1, we applied different approaches that can be interesting in information retrieval tasks. Two proposals were based on the similarity of contextualized embedding vectors, and the other one was based on prompting, an attractive current technique of machine learning. For Task 2, we proposed three fine-tuned models followed by decision policy according to criteria defined by an early detection framework. One model presented extended vocabulary with important words to the addressed domain. In the last task, we obtained good performances considering the decision-based metrics, ranking-based metrics, and runtime. In this work, we explore different ways to deploy the predictive potential of Transformers in eRisk tasks.
* In Conference and Labs of the Evaluation Forum (CLEF 2023), Thessaloniki, Greece
PySS3: A Python package implementing a novel text classifier with visualization tools for Explainable AI
Dec 19, 2019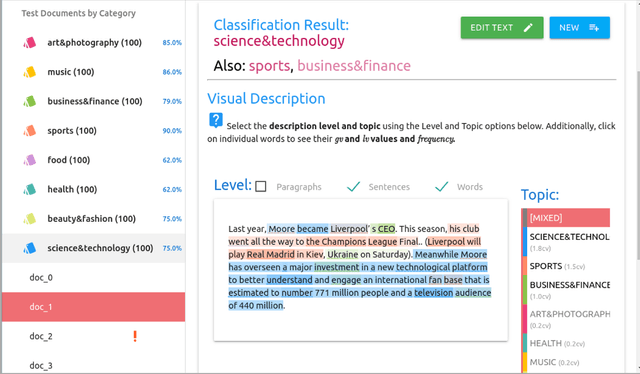
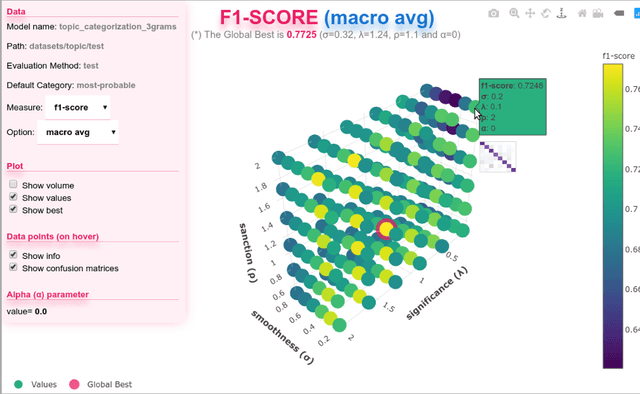
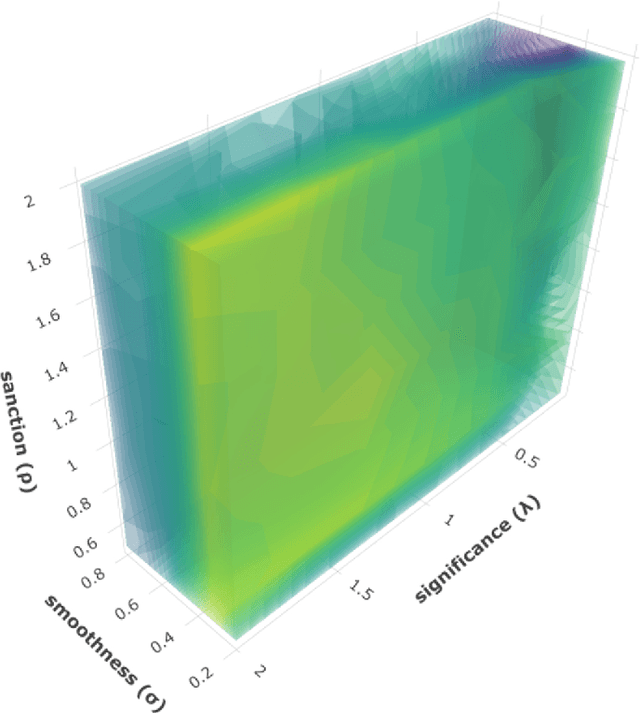

A recently introduced text classifier, called SS3, has obtained state-of-the-art performance on the CLEF's eRisk tasks. SS3 was created to deal with risk detection over text streams and therefore not only supports incremental training and classification but also can visually explain its rationale. However, little attention has been paid to the potential use of SS3 as a general classifier. We believe this could be due to the unavailability of an open-source implementation of SS3. In this work, we introduce PySS3, a package that not only implements SS3 but also comes with visualization tools that allow researchers deploying robust, explainable and trusty machine learning models for text classification.
t-SS3: a text classifier with dynamic n-grams for early risk detection over text streams
Nov 11, 2019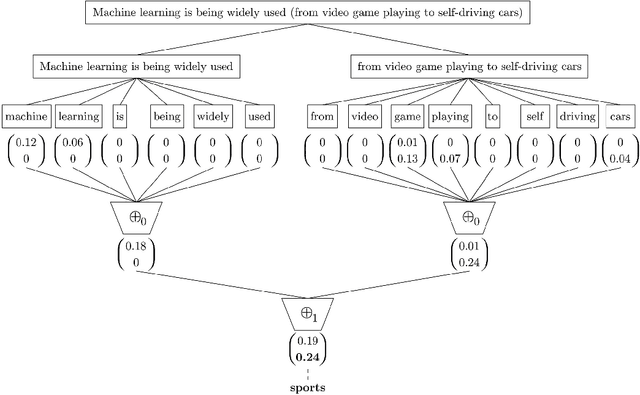
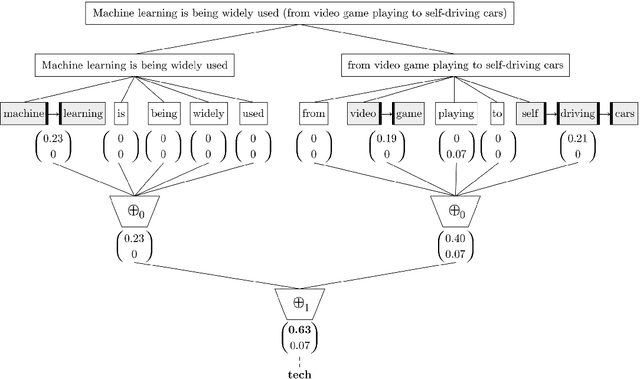
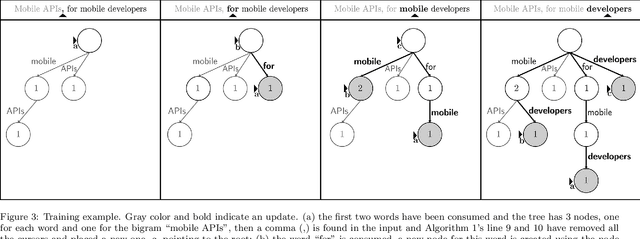
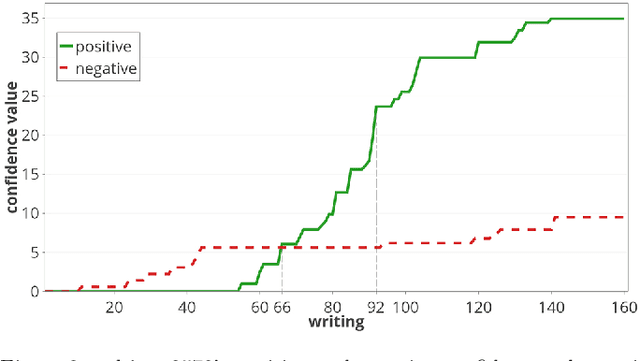
A recently introduced classifier, called SS3, has shown to be well suited to deal with early risk detection (ERD) problems on text streams. It obtained state-of-the-art performance on early depression and anorexia detection on Reddit in the CLEF's eRisk open tasks. SS3 was created to naturally deal with ERD problems since: it supports incremental training and classification over text streams and it can visually explain its rationale. However, SS3 processes the input using a bag-of-word model lacking the ability to recognize important word sequences. This could negatively affect the classification performance and also reduces the descriptiveness of visual explanations. In the standard document classification field, it is very common to use word n-grams to try to overcome some of these limitations. Unfortunately, when working with text streams, using n-grams is not trivial since the system must learn and recognize which n-grams are important ``on the fly''. This paper introduces t-SS3, a variation of SS3 which expands the model to dynamically recognize useful patterns over text streams. We evaluated our model on the eRisk 2017 and 2018 tasks on early depression and anorexia detection. Experimental results show that t-SS3 is able to improve both, existing results and the richness of visual explanations.
A Text Classification Framework for Simple and Effective Early Depression Detection Over Social Media Streams
May 18, 2019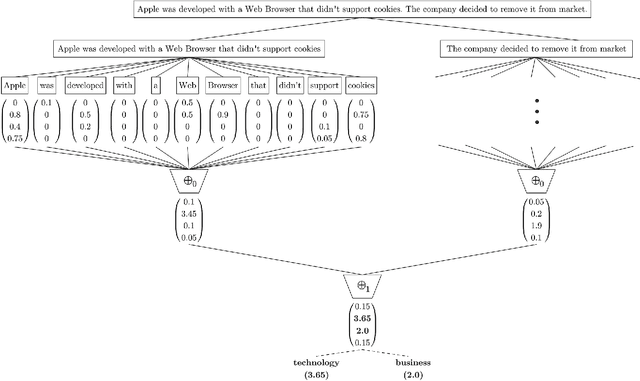
With the rise of the Internet, there is a growing need to build intelligent systems that are capable of efficiently dealing with early risk detection (ERD) problems on social media, such as early depression detection, early rumor detection or identification of sexual predators. These systems, nowadays mostly based on machine learning techniques, must be able to deal with data streams since users provide their data over time. In addition, these systems must be able to decide when the processed data is sufficient to actually classify users. Moreover, since ERD tasks involve risky decisions by which people's lives could be affected, such systems must also be able to justify their decisions. However, most standard and state-of-the-art supervised machine learning models (such as SVM, MNB, Neural Networks, etc.) are not well suited to deal with this scenario. This is due to the fact that they either act as black boxes or do not support incremental classification/learning. In this paper we introduce SS3, a novel supervised learning model for text classification that naturally supports these aspects. SS3 was designed to be used as a general framework to deal with ERD problems. We evaluated our model on the CLEF's eRisk2017 pilot task on early depression detection. Most of the 30 contributions submitted to this competition used state-of-the-art methods. Experimental results show that our classifier was able to outperform these models and standard classifiers, despite being less computationally expensive and having the ability to explain its rationale.
* Highlights: (*) A novel text classifier having the ability to visually explain its rationale; (*) Domain-independent classification that does not require feature engineering; (*) Support for incremental learning and text classification over streams; (*) Efficient framework for addressing early risk detection problems; (*) State-of-the-art performance on early depression detection task