 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularized Calibration with Successive Rounding for Post-Training Quantization
Feb 05, 2026Large language models (LLMs) deliver robust performance across diverse applications, yet their deployment often faces challenges due to the memory and latency costs of storing and accessing billions of parameters. Post-training quantization (PTQ) enables efficient inference by mapping pretrained weights to low-bit formats without retraining, but its effectiveness depends critically on both the quantization objective and the rounding procedure used to obtain low-bit weight representations. In this work, we show that interpolating between symmetric and asymmetric calibration acts as a form of regularization that preserves the standard quadratic structure used in PTQ while providing robustness to activation mismatch. Building on this perspective, we derive a simple successive rounding procedure that naturally incorporates asymmetric calibration, as well as a bounded-search extension that allows for an explicit trade-off between quantization quality and the compute cost. Experiments across multiple LLM families, quantization bit-widths, and benchmarks demonstrate that the proposed bounded search based on a regularized asymmetric calibration objective consistently improves perplexity and accuracy over PTQ baselines, while incurring only modest and controllable additional computational cost.
GeFL: Model-Agnostic Federated Learning with Generative Models
Dec 24, 2024



Federated learning (FL) is a promising paradigm in distributed learning while preserving the privacy of users. However, the increasing size of recent models makes it unaffordable for a few users to encompass the model. It leads the users to adopt heterogeneous models based on their diverse computing capabilities and network bandwidth. Correspondingly, FL with heterogeneous models should be addressed, given that FL typically involves training a single global model. In this paper, we propose Generative Model-Aided Federated Learning (GeFL), incorporating a generative model that aggregates global knowledge across users of heterogeneous models. Our experiments on various classification tasks demonstrate notable performance improvements of GeFL compared to baselines, as well as limitations in terms of privacy and scalability. To tackle these concerns, we introduce a novel framework, GeFL-F. It trains target networks aided by feature-generative models. We empirically demonstrate the consistent performance gains of GeFL-F, while demonstrating better privacy preservation and robustness to a large number of clients. Codes are available at [1].
On the Temperature of Bayesian Graph Neural Networks for Conformal Prediction
Oct 23, 2023


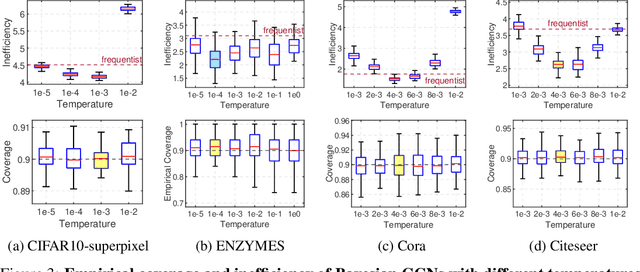
Accurate uncertainty quantification in graph neural networks (GNNs) is essential, especially in high-stakes domains where GNNs are frequently employed. Conformal prediction (CP) offers a promising framework for quantifying uncertainty by providing $\textit{valid}$ prediction sets for any black-box model. CP ensures formal probabilistic guarantees that a prediction set contains a true label with a desired probability. However, the size of prediction sets, known as $\textit{inefficiency}$, is influenced by the underlying model and data generating process. On the other hand, Bayesian learning also provides a credible region based on the estimated posterior distribution, but this region is $\textit{well-calibrated}$ only when the model is correctly specified. Building on a recent work that introduced a scaling parameter for constructing valid credible regions from posterior estimate, our study explores the advantages of incorporating a temperature parameter into Bayesian GNNs within CP framework. We empirically demonstrate the existence of temperatures that result in more efficient prediction sets. Furthermore, we conduct an analysis to identify the factors contributing to inefficiency and offer valuable insights into the relationship between CP performance and model calibration.
NeFL: Nested Federated Learning for Heterogeneous Clients
Aug 15, 2023Federated learning (FL) is a promising approach in distributed learning keeping privacy. However, during the training pipeline of FL, slow or incapable clients (i.e., stragglers) slow down the total training time and degrade performance. System heterogeneity, including heterogeneous computing and network bandwidth, has been addressed to mitigate the impact of stragglers. Previous studies split models to tackle the issue, but with less degree-of-freedom in terms of model architecture. We propose nested federated learning (NeFL), a generalized framework that efficiently divides a model into submodels using both depthwise and widthwise scaling. NeFL is implemented by interpreting models as solving ordinary differential equations (ODEs) with adaptive step sizes. To address the inconsistency that arises when training multiple submodels with different architecture, we decouple a few parameters. NeFL enables resource-constrained clients to effectively join the FL pipeline and the model to be trained with a larger amount of data. Through a series of experiments, we demonstrate that NeFL leads to significant gains, especially for the worst-case submodel (e.g., 8.33 improvement on CIFAR-10). Furthermore, we demonstrate NeFL aligns with recent studies in FL.