 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCiteBART: Learning to Generate Citations for Local Citation Recommendation
Dec 23, 2024Citations are essential building blocks in scientific writing. The scientific community is longing for support in their generation. Citation generation involves two complementary subtasks: Determining the citation worthiness of a context and, if it's worth it, proposing the best candidate papers for the citation placeholder. The latter subtask is called local citation recommendation (LCR). This paper proposes CiteBART, a custom BART pre-training based on citation token masking to generate citations to achieve LCR. In the base scheme, we mask the citation token in the local citation context to make the citation prediction. In the global one, we concatenate the citing paper's title and abstract to the local citation context to learn to reconstruct the citation token. CiteBART outperforms state-of-the-art approaches on the citation recommendation benchmarks except for the smallest FullTextPeerRead dataset. The effect is significant in the larger benchmarks, e.g., Refseer and ArXiv. We present a qualitative analysis and an ablation study to provide insights into the workings of CiteBART. Our analyses confirm that its generative nature brings about a zero-shot capability.
An End-to-End System for Reproducibility Assessment of Source Code Repositories via Their Readmes
Oct 14, 2023Increased reproducibility of machine learning research has been a driving force for dramatic improvements in learning performances. The scientific community further fosters this effort by including reproducibility ratings in reviewer forms and considering them as a crucial factor for the overall evaluation of papers. Accompanying source code is not sufficient to make a work reproducible. The shared codes should meet the ML reproducibility checklist as well. This work aims to support reproducibility evaluations of papers with source codes. We propose an end-to-end system that operates on the Readme file of the source code repositories. The system checks the compliance of a given Readme to a template proposed by a widely used platform for sharing source codes of research. Our system generates scores based on a custom function to combine section scores. We also train a hierarchical transformer model to assign a class label to a given Readme. The experimental results show that the section similarity-based system performs better than the hierarchical transformer. Moreover, it has an advantage regarding explainability since one can directly relate the score to the sections of Readme files.
A Survey On Neural Word Embeddings
Oct 05, 2021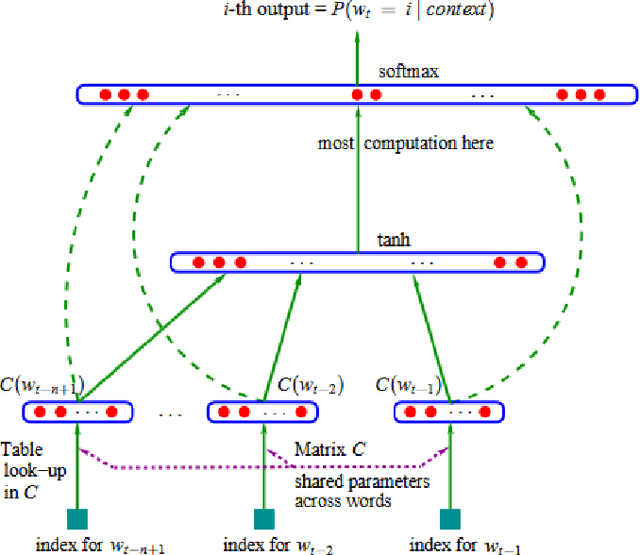
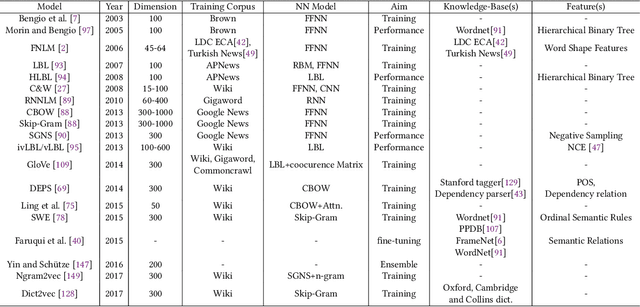

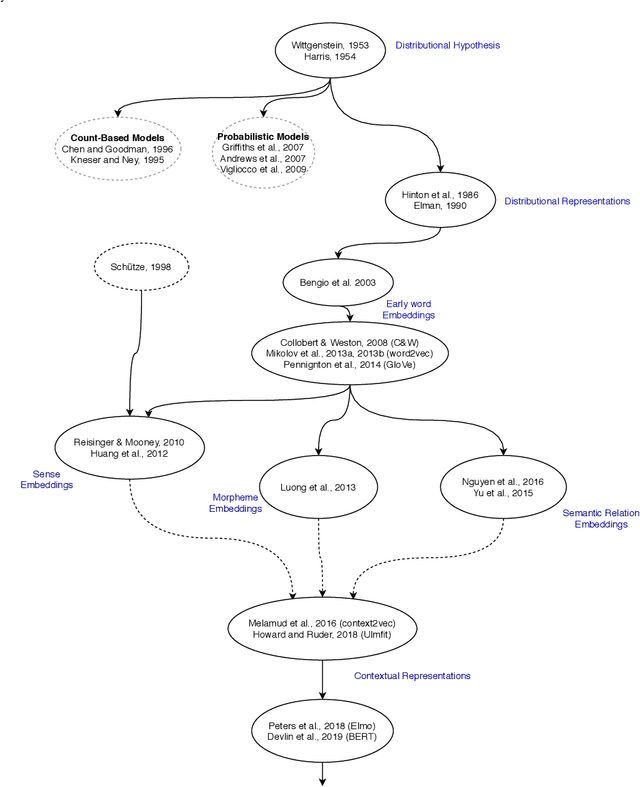
Understanding human language has been a sub-challenge on the way of intelligent machines. The study of meaning in natural language processing (NLP) relies on the distributional hypothesis where language elements get meaning from the words that co-occur within contexts. The revolutionary idea of distributed representation for a concept is close to the working of a human mind in that the meaning of a word is spread across several neurons, and a loss of activation will only slightly affect the memory retrieval process. Neural word embeddings transformed the whole field of NLP by introducing substantial improvements in all NLP tasks. In this survey, we provide a comprehensive literature review on neural word embeddings. We give theoretical foundations and describe existing work by an interplay between word embeddings and language modelling. We provide broad coverage on neural word embeddings, including early word embeddings, embeddings targeting specific semantic relations, sense embeddings, morpheme embeddings, and finally, contextual representations. Finally, we describe benchmark datasets in word embeddings' performance evaluation and downstream tasks along with the performance results of/due to word embeddings.
Leveraging Commonsense Knowledge on Classifying False News and Determining Checkworthiness of Claims
Aug 08, 2021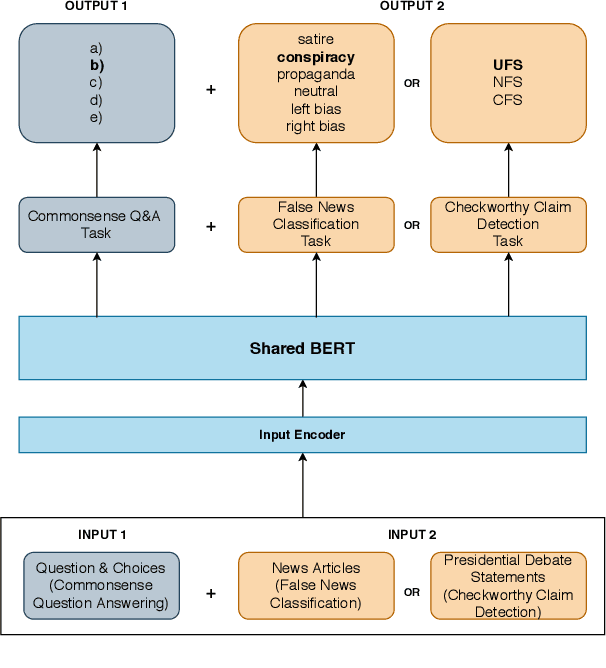

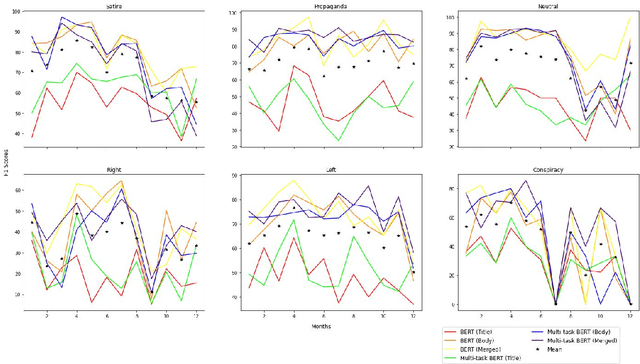

Widespread and rapid dissemination of false news has made fact-checking an indispensable requirement. Given its time-consuming and labor-intensive nature, the task calls for an automated support to meet the demand. In this paper, we propose to leverage commonsense knowledge for the tasks of false news classification and check-worthy claim detection. Arguing that commonsense knowledge is a factor in human believability, we fine-tune the BERT language model with a commonsense question answering task and the aforementioned tasks in a multi-task learning environment. For predicting fine-grained false news types, we compare the proposed fine-tuned model's performance with the false news classification models on a public dataset as well as a newly collected dataset. We compare the model's performance with the single-task BERT model and a state-of-the-art check-worthy claim detection tool to evaluate the check-worthy claim detection. Our experimental analysis demonstrates that commonsense knowledge can improve performance in both tasks.
Gender Prediction from Tweets: Improving Neural Representations with Hand-Crafted Features
Sep 06, 2019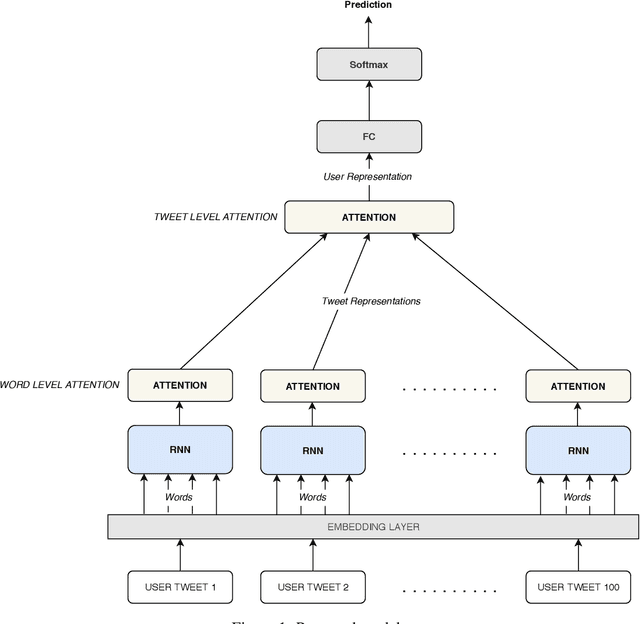

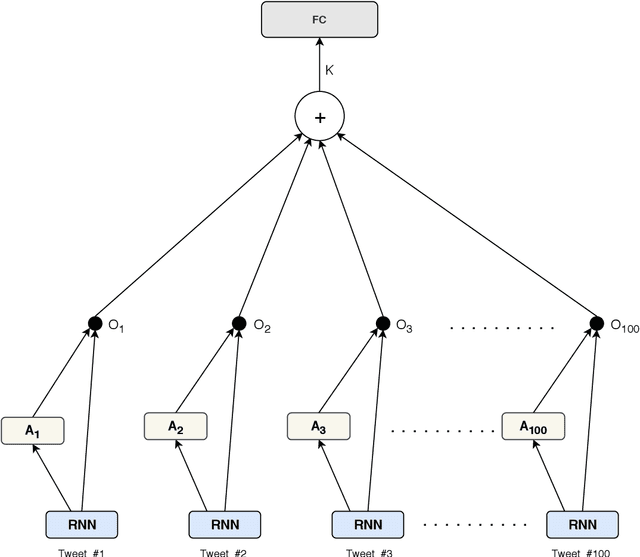
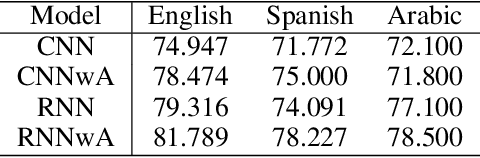
Author profiling is the characterization of an author through some key attributes such as gender, age, and language. In this paper, a RNN model with Attention (RNNwA) is proposed to predict the gender of a twitter user using their tweets. Both word level and tweet level attentions are utilized to learn 'where to look'. This model (https://github.com/Darg-Iztech/gender-prediction-from-tweets) is improved by concatenating LSA-reduced n-gram features with the learned neural representation of a user. Both models are tested on three languages: English, Spanish, Arabic. The improved version of the proposed model (RNNwA + n-gram) achieves state-of-the-art performance on English and has competitive results on Spanish and Arabic.