 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti LoRA Meets Vision: Merging multiple adapters to create a multi task model
Nov 21, 2024Parameter efficient finetuning (PEFT) methods are widely used in LLMs and generative models in computer vision. Especially one can use multiple of these during inference to change the behavior of the base model. In this paper we investigated whether multiple LoRA adapters trained on computer vision tasks can be merged together and used during inference without loss in performance. By achieving this, multitask models can be created just by merging different LoRAs. Merging these will reduce inference time and it will not require any additional retraining. We have trained adapters on six different tasks and evaluated their performance when they are merged together. For comparison we used a model with a frozen backbone and finetuned its head. Our results show that even with simple merging techniques creating a multitask model by merging adapters is achievable by slightly loosing performance in some cases. In our experiments we merged up to three adapters together. Depending on the task and the similarity of the data adapters were trained on, merges can outperform head finetuning. We have observed that LoRAs trained with dissimilar datasets tend to perform better compared to model trained on similar datasets.
Resume Information Extraction via Post-OCR Text Processing
Jun 23, 2023Information extraction (IE), one of the main tasks of natural language processing (NLP), has recently increased importance in the use of resumes. In studies on the text to extract information from the CV, sentence classification was generally made using NLP models. In this study, it is aimed to extract information by classifying all of the text groups after pre-processing such as Optical Character Recognition (OCT) and object recognition with the YOLOv8 model of the resumes. The text dataset consists of 286 resumes collected for 5 different (education, experience, talent, personal and language) job descriptions in the IT industry. The dataset created for object recognition consists of 1198 resumes, which were collected from the open-source internet and labeled as sets of text. BERT, BERT-t, DistilBERT, RoBERTa and XLNet were used as models. F1 score variances were used to compare the model results. In addition, the YOLOv8 model has also been reported comparatively in itself. As a result of the comparison, DistilBERT was showed better results despite having a lower number of parameters than other models.
A Comparison of Time-based Models for Multimodal Emotion Recognition
Jun 22, 2023Emotion recognition has become an important research topic in the field of human-computer interaction. Studies on sound and videos to understand emotions focused mainly on analyzing facial expressions and classified 6 basic emotions. In this study, the performance of different sequence models in multi-modal emotion recognition was compared. The sound and images were first processed by multi-layered CNN models, and the outputs of these models were fed into various sequence models. The sequence model is GRU, Transformer, LSTM and Max Pooling. Accuracy, precision, and F1 Score values of all models were calculated. The multi-modal CREMA-D dataset was used in the experiments. As a result of the comparison of the CREMA-D dataset, GRU-based architecture with 0.640 showed the best result in F1 score, LSTM-based architecture with 0.699 in precision metric, while sensitivity showed the best results over time with Max Pooling-based architecture with 0.620. As a result, it has been observed that the sequence models compare performances close to each other.
Tooth Instance Segmentation on Panoramic Dental Radiographs Using U-Nets and Morphological Processing
Mar 31, 2022

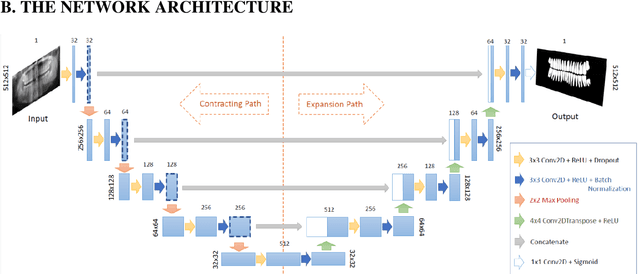
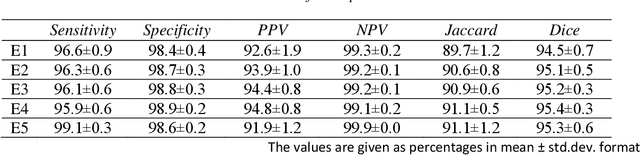
Automatic teeth segmentation in panoramic x-ray images is an important research subject of the image analysis in dentistry. In this study, we propose a post-processing stage to obtain a segmentation map in which the objects in the image are separated, and apply this technique to tooth instance segmentation with U-Net network. The post-processing consists of grayscale morphological and filtering operations, which are applied to the sigmoid output of the network before binarization. A dice overlap score of 95.4 - 0.3% is obtained in overall teeth segmentation. The proposed post-processing stages reduce the mean error of tooth count to 6.15%, whereas the error without post-processing is 26.81%. The performances of both segmentation and tooth counting are the highest in the literature, to our knowledge. Moreover, this is achieved by using a relatively small training dataset, which consists of 105 images. Although the aim in this study is to segment tooth instances, the presented method is applicable to similar problems in other domains, such as separating the cell instances
* 12 pages, 7 figures
Short-Term Forecasting COVID-19 Cases In Turkey Using Long Short-Term Memory Network
Sep 16, 2020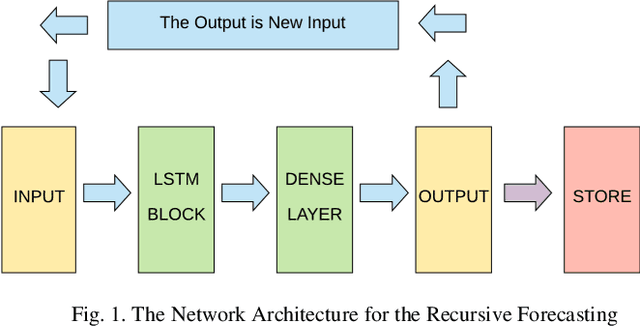
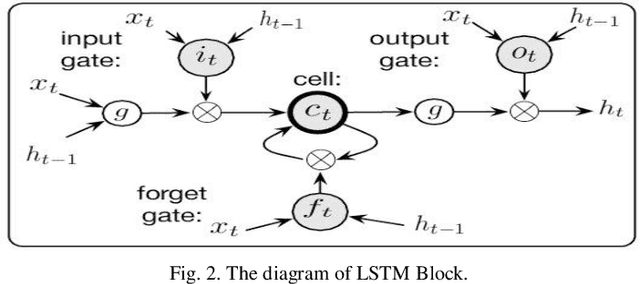
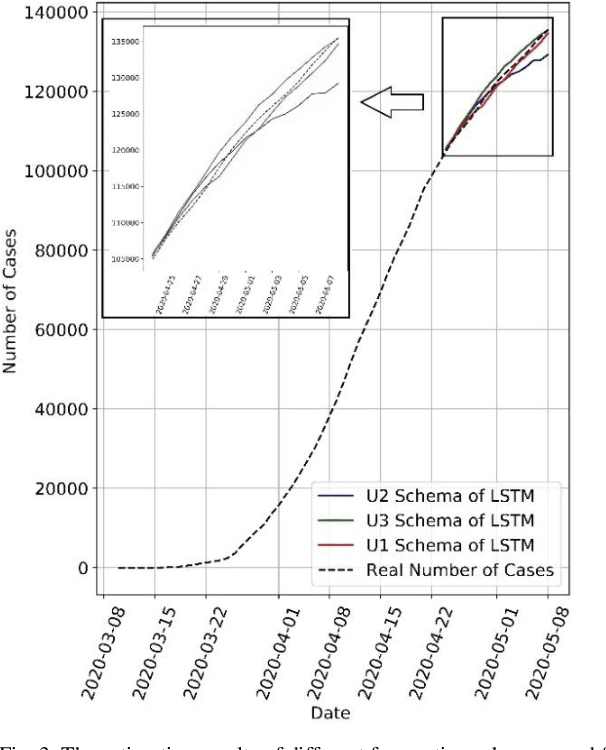
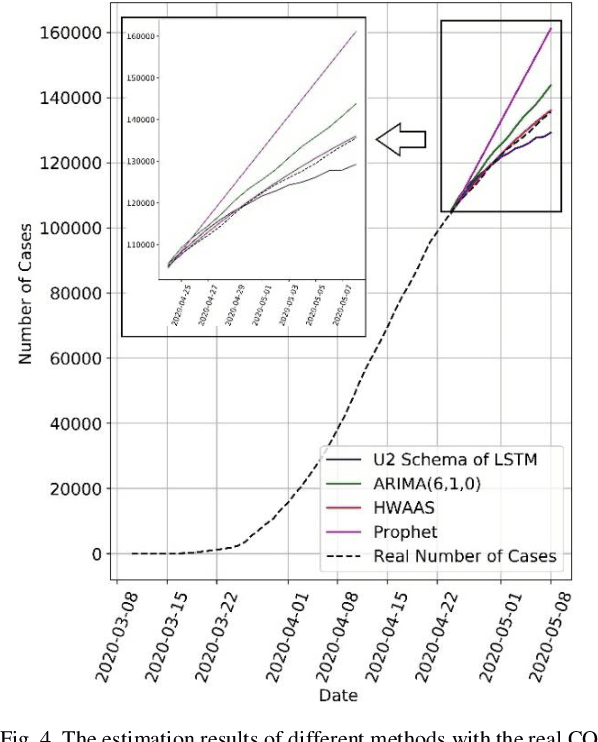
COVID-19 has been one of the most severe diseases, causing a harsh pandemic all over the world, since December 2019. The aim of this study is to evaluate the value of Long Short-Term Memory (LSTM) Networks in forecasting the total number of COVID-19 cases in Turkey. The COVID-19 data for 30 days, between March 24 and April 23, 2020, are used to estimate the next fifteen days. The mean absolute error of the LSTM Network for 15 days estimation is 1,69$\pm$1.35%. Whereas, for the same data, the error of the Box-Jenkins method is 3.24$\pm$1.56%, Prophet method is 6.88$\pm$4.96% and Holt-Winters Additive method with Damped Trend is 0.47$\pm$0.28%. Additionally, when the number of deaths data is also provided with the number of total cases to the input of LSTM Network, the mean error reduces to 0.99$\pm$0.51%. Consequently, addition of the number of deaths data to the input, results a lower error in forecasting, compared to using only the number of total cases as the input. However, Holt-Winters Additive method with Damped Trend gives superior results to LSTM Networks in forecasting the total number of COVID-19 cases.