 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexPerT: Extended Persistence Transformer
Oct 18, 2024
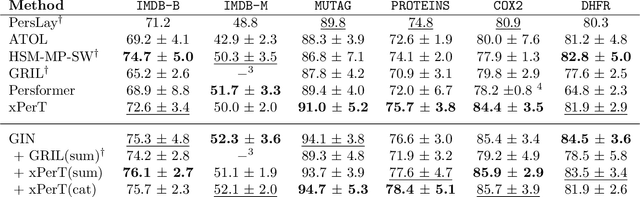


A persistence diagram provides a compact summary of persistent homology, which captures the topological features of a space at different scales. However, due to its nature as a set, incorporating it as a feature into a machine learning framework is challenging. Several methods have been proposed to use persistence diagrams as input for machine learning models, but they often require complex preprocessing steps and extensive hyperparameter tuning. In this paper, we propose a novel transformer architecture called the \textit{Extended Persistence Transformer (xPerT)}, which is highly scalable than the compared to Persformer, an existing transformer for persistence diagrams. xPerT reduces GPU memory usage by over 90\% and improves accuracy on multiple datasets. Additionally, xPerT does not require complex preprocessing steps or extensive hyperparameter tuning, making it easy to use in practice. Our code is available at https://github.com/sehunfromdaegu/ECG_JEPA.
Learning General Representation of 12-Lead Electrocardiogram with a Joint-Embedding Predictive architecture
Oct 11, 2024We propose a self-supervised learning method for 12-lead Electrocardiogram (ECG) analysis, named ECG Joint Embedding Predictive Architecture (ECG-JEPA). ECG-JEPA employs a masking strategy to learn semantic representations of ECG data. Unlike existing methods, ECG-JEPA predicts at the hidden representation level rather than reconstructing raw data. This approach offers several advantages in the ECG domain: (1) it avoids producing unnecessary details, such as noise, which is common in standard ECG; and (2) it addresses the limitations of na\"ive L2 loss between raw signals. Another key contribution is the introduction of a special masked attention tailored for 12-lead ECG data, Cross-Pattern Attention (CroPA). CroPA enables the model to effectively capture inter-patch relationships. Additionally, ECG-JEPA is highly scalable, allowing efficient training on large datasets. Our code is openly available https://github.com/sehunfromdaegu/ECG_JEPA.
Improved Architecture for High-resolution Piano Transcription to Efficiently Capture Acoustic Characteristics of Music Signals
Sep 29, 2024Automatic music transcription (AMT), aiming to convert musical signals into musical notation, is one of the important tasks in music information retrieval. Recently, previous works have applied high-resolution labels, i.e., the continuous onset and offset times of piano notes, as training targets, achieving substantial improvements in transcription performance. However, there still remain some issues to be addressed, e.g., the harmonics of notes are sometimes recognized as false positive notes, and the size of AMT model tends to be larger to improve the transcription performance. To address these issues, we propose an improved high-resolution piano transcription model to well capture specific acoustic characteristics of music signals. First, we employ the Constant-Q Transform as the input representation to better adapt to musical signals. Moreover, we have designed two architectures: the first is based on a convolutional recurrent neural network (CRNN) with dilated convolution, and the second is an encoder-decoder architecture that combines CRNN with a non-autoregressive Transformer decoder. We conduct systematic experiments for our models. Compared to the high-resolution AMT system used as a baseline, our models effectively achieve 1) consistent improvement in note-level metrics, and 2) the significant smaller model size, which shed lights on future work.