 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Formality in Low-Resource NMT with Domain Adaptation and Re-Ranking: SLT-CDT-UoS at IWSLT2022
May 12, 2022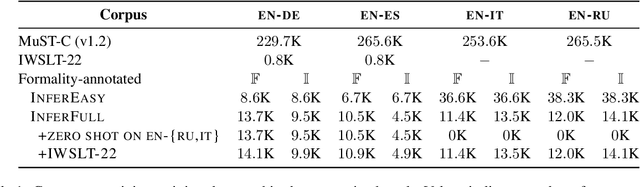


This paper describes the SLT-CDT-UoS group's submission to the first Special Task on Formality Control for Spoken Language Translation, part of the IWSLT 2022 Evaluation Campaign. Our efforts were split between two fronts: data engineering and altering the objective function for best hypothesis selection. We used language-independent methods to extract formal and informal sentence pairs from the provided corpora; using English as a pivot language, we propagated formality annotations to languages treated as zero-shot in the task; we also further improved formality controlling with a hypothesis re-ranking approach. On the test sets for English-to-German and English-to-Spanish, we achieved an average accuracy of .935 within the constrained setting and .995 within unconstrained setting. In a zero-shot setting for English-to-Russian and English-to-Italian, we scored average accuracy of .590 for constrained setting and .659 for unconstrained.
Controlling Extra-Textual Attributes about Dialogue Participants: A Case Study of English-to-Polish Neural Machine Translation
May 10, 2022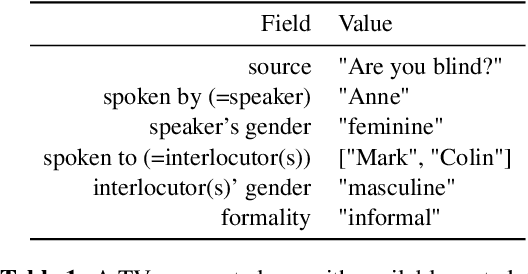
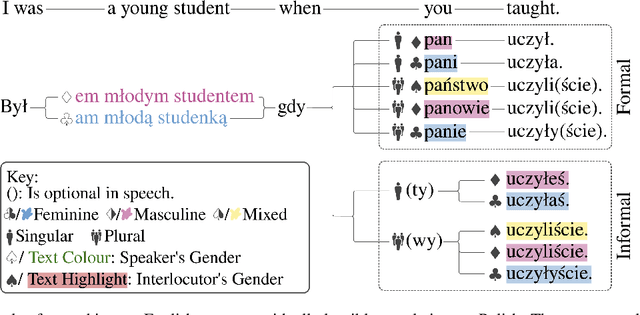
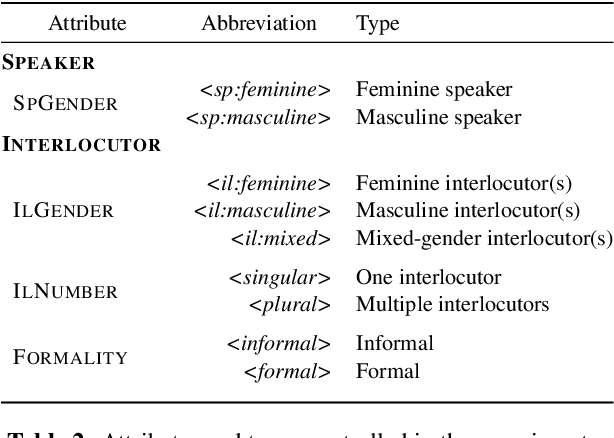

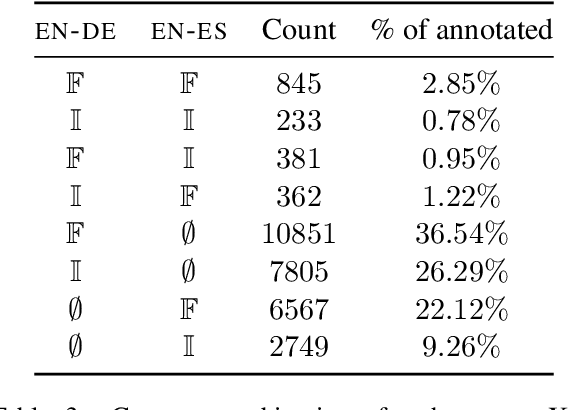
Unlike English, morphologically rich languages can reveal characteristics of speakers or their conversational partners, such as gender and number, via pronouns, morphological endings of words and syntax. When translating from English to such languages, a machine translation model needs to opt for a certain interpretation of textual context, which may lead to serious translation errors if extra-textual information is unavailable. We investigate this challenge in the English-to-Polish language direction. We focus on the underresearched problem of utilising external metadata in automatic translation of TV dialogue, proposing a case study where a wide range of approaches for controlling attributes in translation is employed in a multi-attribute scenario. The best model achieves an improvement of +5.81 chrF++/+6.03 BLEU, with other models achieving competitive performance. We additionally contribute a novel attribute-annotated dataset of Polish TV dialogue and a morphological analysis script used to evaluate attribute control in models.
Towards Personalised and Document-level Machine Translation of Dialogue
Feb 11, 2021



State-of-the-art (SOTA) neural machine translation (NMT) systems translate texts at sentence level, ignoring context: intra-textual information, like the previous sentence, and extra-textual information, like the gender of the speaker. Because of that, some sentences are translated incorrectly. Personalised NMT (PersNMT) and document-level NMT (DocNMT) incorporate this information into the translation process. Both fields are relatively new and previous work within them is limited. Moreover, there are no readily available robust evaluation metrics for them, which makes it difficult to develop better systems, as well as track global progress and compare different methods. This thesis proposal focuses on PersNMT and DocNMT for the domain of dialogue extracted from TV subtitles in five languages: English, Brazilian Portuguese, German, French and Polish. Three main challenges are addressed: (1) incorporating extra-textual information directly into NMT systems; (2) improving the machine translation of cohesion devices; (3) reliable evaluation for PersNMT and DocNMT.