 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAEA: Experiences and Lessons Learned from a Country-Scale Environmental Digital Twin
Nov 17, 2025This paper describes the experiences and lessons learned after the deployment of a country-scale environmental digital twin on the island of Cyprus for three years. This digital twin, called GAEA, contains 27 environmental geospatial services and is suitable for urban planners, policymakers, farmers, property owners, real-estate and forestry professionals, as well as insurance companies and banks that have properties in their portfolio. This paper demonstrates the power, potential, current and future challenges of geospatial analytics and environmental digital twins on a large scale.
A model-agnostic approach for generating Saliency Maps to explain inferred decisions of Deep Learning Models
Sep 27, 2022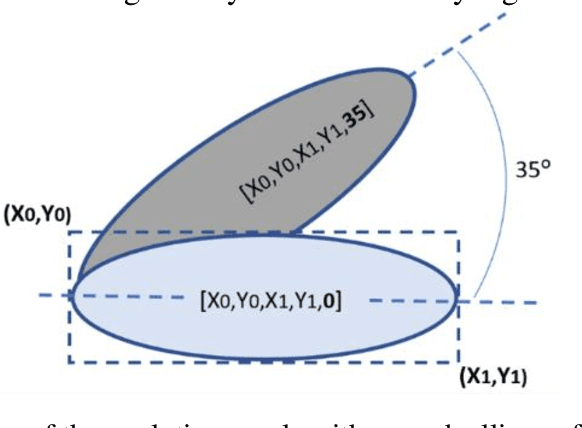
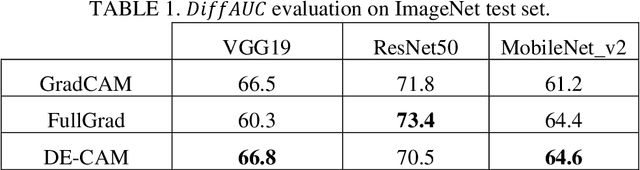

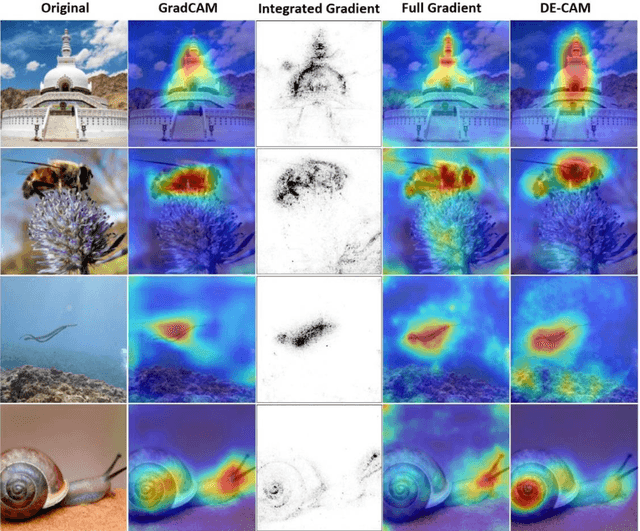
The widespread use of black-box AI models has raised the need for algorithms and methods that explain the decisions made by these models. In recent years, the AI research community is increasingly interested in models' explainability since black-box models take over more and more complicated and challenging tasks. Explainability becomes critical considering the dominance of deep learning techniques for a wide range of applications, including but not limited to computer vision. In the direction of understanding the inference process of deep learning models, many methods that provide human comprehensible evidence for the decisions of AI models have been developed, with the vast majority relying their operation on having access to the internal architecture and parameters of these models (e.g., the weights of neural networks). We propose a model-agnostic method for generating saliency maps that has access only to the output of the model and does not require additional information such as gradients. We use Differential Evolution (DE) to identify which image pixels are the most influential in a model's decision-making process and produce class activation maps (CAMs) whose quality is comparable to the quality of CAMs created with model-specific algorithms. DE-CAM achieves good performance without requiring access to the internal details of the model's architecture at the cost of more computational complexity.
Exploiting Digital Surface Models for Inferring Super-Resolution for Remotely Sensed Images
May 09, 2022



Despite the plethora of successful Super-Resolution Reconstruction (SRR) models applied to natural images, their application to remote sensing imagery tends to produce poor results. Remote sensing imagery is often more complicated than natural images and has its peculiarities such as being of lower resolution, it contains noise, and often depicting large textured surfaces. As a result, applying non-specialized SRR models on remote sensing imagery results in artifacts and poor reconstructions. To address these problems, this paper proposes an architecture inspired by previous research work, introducing a novel approach for forcing an SRR model to output realistic remote sensing images: instead of relying on feature-space similarities as a perceptual loss, the model considers pixel-level information inferred from the normalized Digital Surface Model (nDSM) of the image. This strategy allows the application of better-informed updates during the training of the model which sources from a task (elevation map inference) that is closely related to remote sensing. Nonetheless, the nDSM auxiliary information is not required during production and thus the model infers a super-resolution image without any additional data besides its low-resolution pairs. We assess our model on two remotely sensed datasets of different spatial resolutions that also contain the DSM pairs of the images: the DFC2018 dataset and the dataset containing the national Lidar fly-by of Luxembourg. Based on visual inspection, the inferred super-resolution images exhibit particularly superior quality. In particular, the results for the high-resolution DFC2018 dataset are realistic and almost indistinguishable from the ground truth images.
Focusing on Shadows for Predicting Heightmaps from Single Remotely Sensed RGB Images with Deep Learning
Apr 22, 2021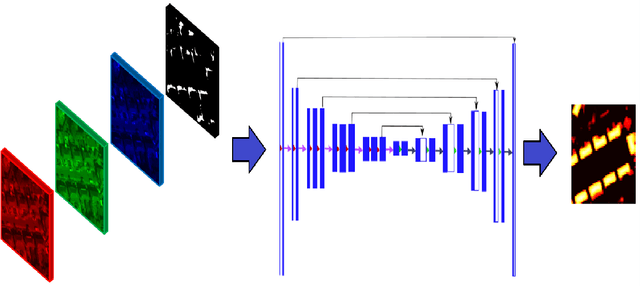

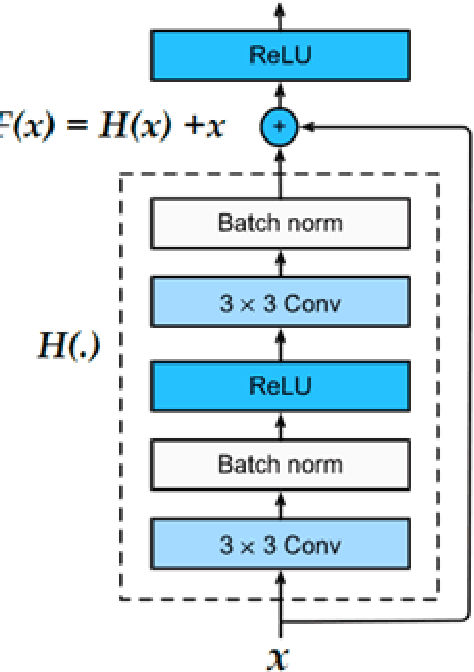
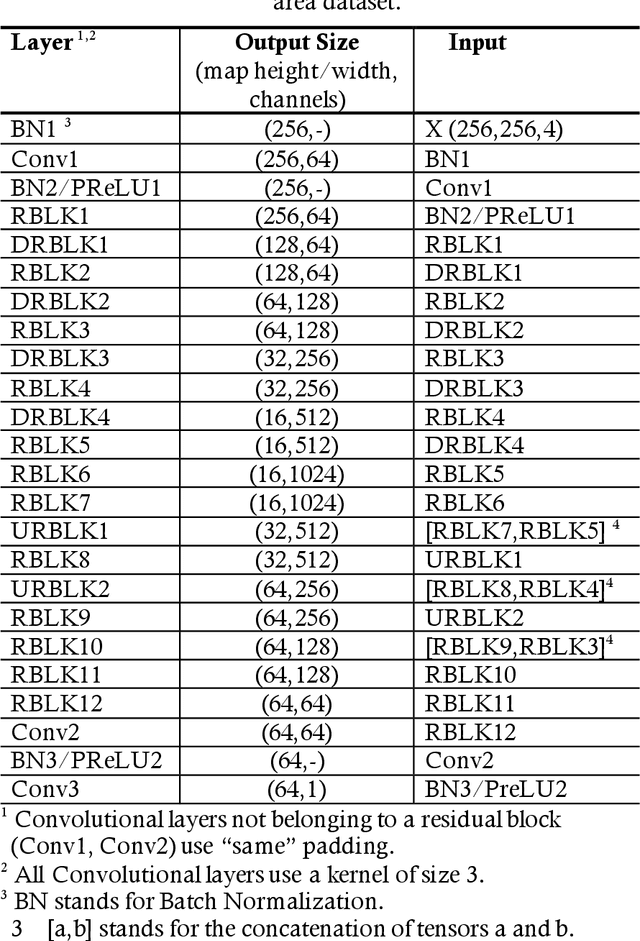
Estimating the heightmaps of buildings and vegetation in single remotely sensed images is a challenging problem. Effective solutions to this problem can comprise the stepping stone for solving complex and demanding problems that require 3D information of aerial imagery in the remote sensing discipline, which might be expensive or not feasible to require. We propose a task-focused Deep Learning (DL) model that takes advantage of the shadow map of a remotely sensed image to calculate its heightmap. The shadow is computed efficiently and does not add significant computation complexity. The model is trained with aerial images and their Lidar measurements, achieving superior performance on the task. We validate the model with a dataset covering a large area of Manchester, UK, as well as the 2018 IEEE GRSS Data Fusion Contest Lidar dataset. Our work suggests that the proposed DL architecture and the technique of injecting shadows information into the model are valuable for improving the heightmap estimation task for single remotely sensed imagery.
EscapeWildFire: Assisting People to Escape Wildfires in Real-Time
Feb 23, 2021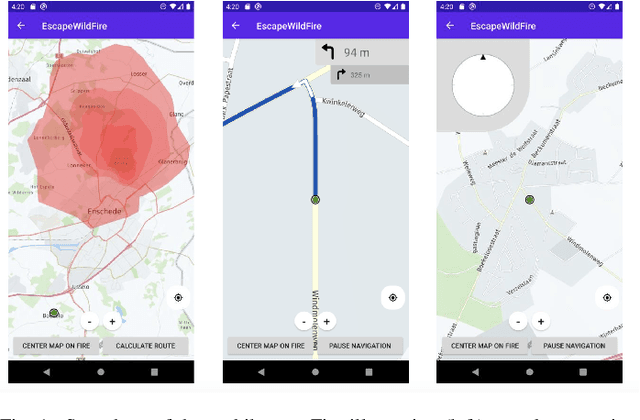
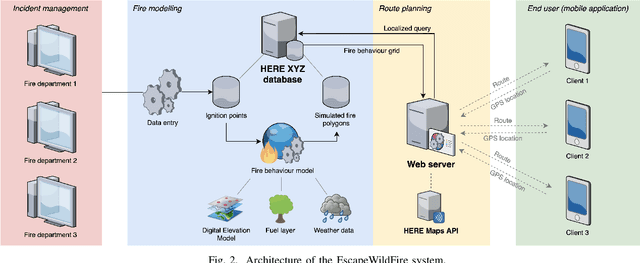
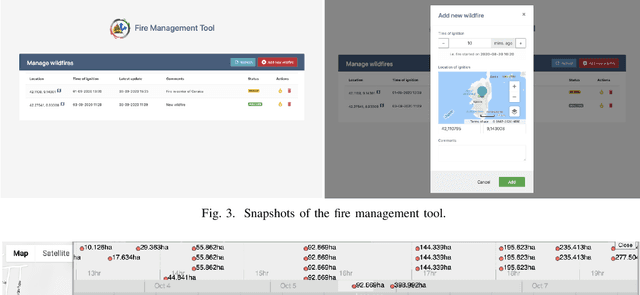
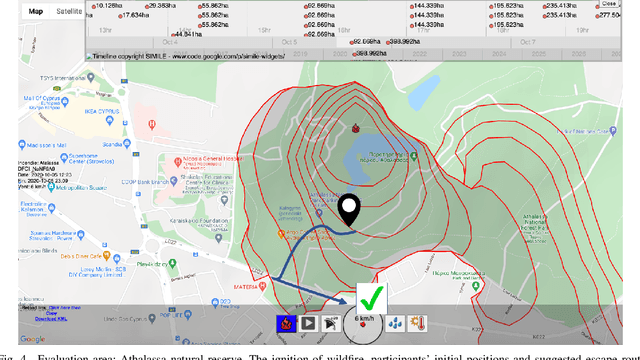
Over the past couple of decades, the number of wildfires and area of land burned around the world has been steadily increasing, partly due to climatic changes and global warming. Therefore, there is a high probability that more people will be exposed to and endangered by forest fires. Hence there is an urgent need to design pervasive systems that effectively assist people and guide them to safety during wildfires. This paper presents EscapeWildFire, a mobile application connected to a backend system which models and predicts wildfire geographical progression, assisting citizens to escape wildfires in real-time. A small pilot indicates the correctness of the system. The code is open-source; fire authorities around the world are encouraged to adopt this approach.
The pursuit of beauty: Converting image labels to meaningful vectors
Aug 03, 2020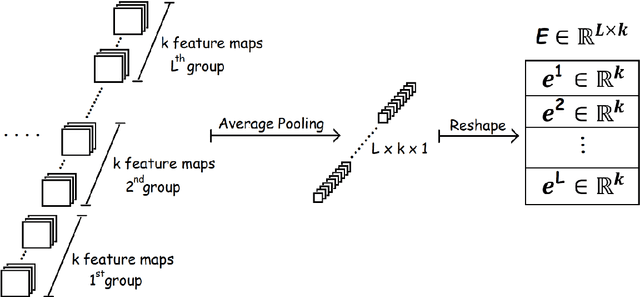
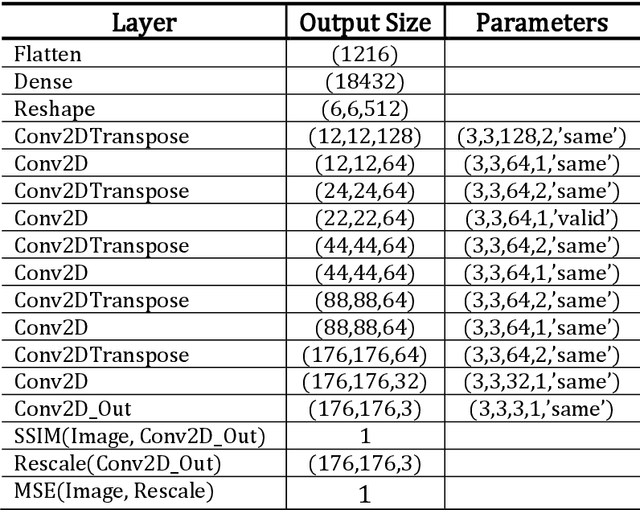
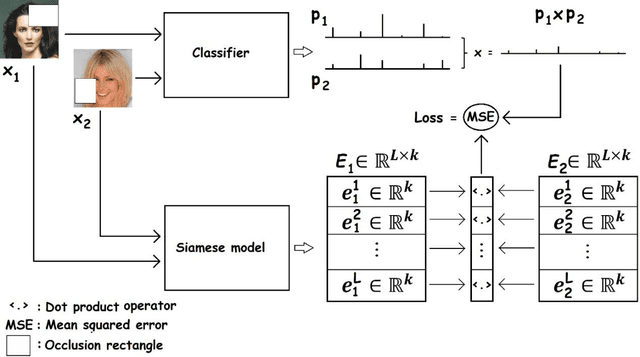

A challenge of the computer vision community is to understand the semantics of an image, in order to allow image reconstruction based on existing high-level features or to better analyze (semi-)labelled datasets. Towards addressing this challenge, this paper introduces a method, called Occlusion-based Latent Representations (OLR), for converting image labels to meaningful representations that capture a significant amount of data semantics. Besides being informational rich, these representations compose a disentangled low-dimensional latent space where each image label is encoded into a separate vector. We evaluate the quality of these representations in a series of experiments whose results suggest that the proposed model can capture data concepts and discover data interrelations.
Identification of Tree Species in Japanese Forests based on Aerial Photography and Deep Learning
Jul 17, 2020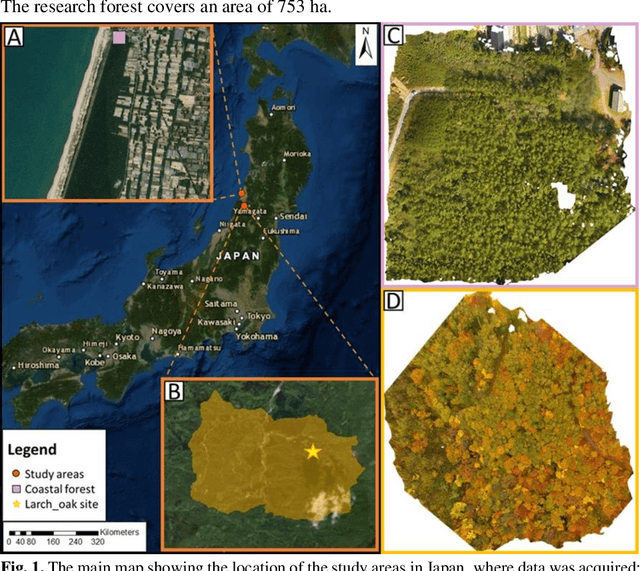

Natural forests are complex ecosystems whose tree species distribution and their ecosystem functions are still not well understood. Sustainable management of these forests is of high importance because of their significant role in climate regulation, biodiversity, soil erosion and disaster prevention among many other ecosystem services they provide. In Japan particularly, natural forests are mainly located in steep mountains, hence the use of aerial imagery in combination with computer vision are important modern tools that can be applied to forest research. Thus, this study constitutes a preliminary research in this field, aiming at classifying tree species in Japanese mixed forests using UAV images and deep learning in two different mixed forest types: a black pine (Pinus thunbergii)-black locust (Robinia pseudoacacia) and a larch (Larix kaempferi)-oak (Quercus mongolica) mixed forest. Our results indicate that it is possible to identify black locust trees with 62.6 % True Positives (TP) and 98.1% True Negatives (TN), while lower precision was reached for larch trees (37.4% TP and 97.7% TN).
Training Deep Learning Models via Synthetic Data: Application in Unmanned Aerial Vehicles
Aug 18, 2019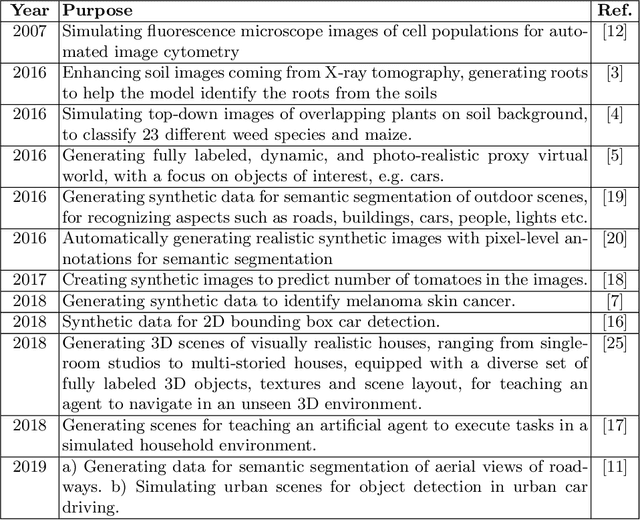

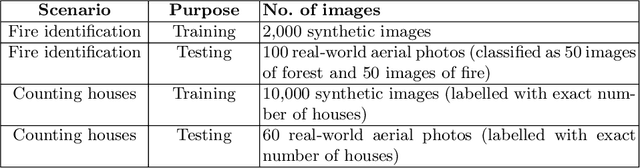

This paper describes preliminary work in the recent promising approach of generating synthetic training data for facilitating the learning procedure of deep learning (DL) models, with a focus on aerial photos produced by unmanned aerial vehicles (UAV). The general concept and methodology are described, and preliminary results are presented, based on a classification problem of fire identification in forests as well as a counting problem of estimating number of houses in urban areas. The proposed technique constitutes a new possibility for the DL community, especially related to UAV-based imagery analysis, with much potential, promising results, and unexplored ground for further research.