 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoMoFormer: Multi-Person Pose Forecasting with Transformers
Aug 30, 2022
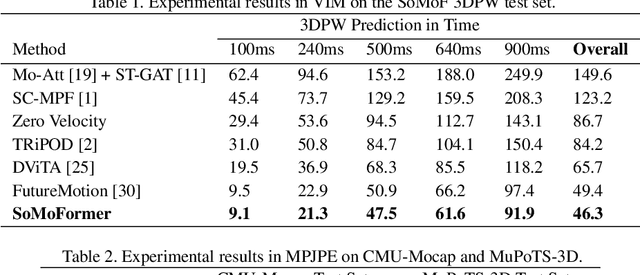
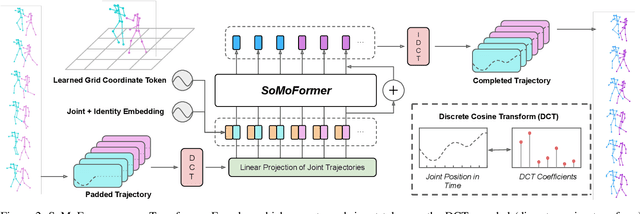
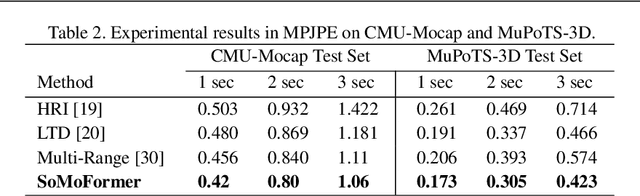
Human pose forecasting is a challenging problem involving complex human body motion and posture dynamics. In cases that there are multiple people in the environment, one's motion may also be influenced by the motion and dynamic movements of others. Although there are several previous works targeting the problem of multi-person dynamic pose forecasting, they often model the entire pose sequence as time series (ignoring the underlying relationship between joints) or only output the future pose sequence of one person at a time. In this paper, we present a new method, called Social Motion Transformer (SoMoFormer), for multi-person 3D pose forecasting. Our transformer architecture uniquely models human motion input as a joint sequence rather than a time sequence, allowing us to perform attention over joints while predicting an entire future motion sequence for each joint in parallel. We show that with this problem reformulation, SoMoFormer naturally extends to multi-person scenes by using the joints of all people in a scene as input queries. Using learned embeddings to denote the type of joint, person identity, and global position, our model learns the relationships between joints and between people, attending more strongly to joints from the same or nearby people. SoMoFormer outperforms state-of-the-art methods for long-term motion prediction on the SoMoF benchmark as well as the CMU-Mocap and MuPoTS-3D datasets. Code will be made available after publication.