 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating Healthcare Insights: A Birds Eye View of Explainability with Knowledge Graphs
Sep 28, 2023Knowledge graphs (KGs) are gaining prominence in Healthcare AI, especially in drug discovery and pharmaceutical research as they provide a structured way to integrate diverse information sources, enhancing AI system interpretability. This interpretability is crucial in healthcare, where trust and transparency matter, and eXplainable AI (XAI) supports decision making for healthcare professionals. This overview summarizes recent literature on the impact of KGs in healthcare and their role in developing explainable AI models. We cover KG workflow, including construction, relationship extraction, reasoning, and their applications in areas like Drug-Drug Interactions (DDI), Drug Target Interactions (DTI), Drug Development (DD), Adverse Drug Reactions (ADR), and bioinformatics. We emphasize the importance of making KGs more interpretable through knowledge-infused learning in healthcare. Finally, we highlight research challenges and provide insights for future directions.
A Birds Eye View on Knowledge Graph Embeddings, Software Libraries, Applications and Challenges
May 18, 2022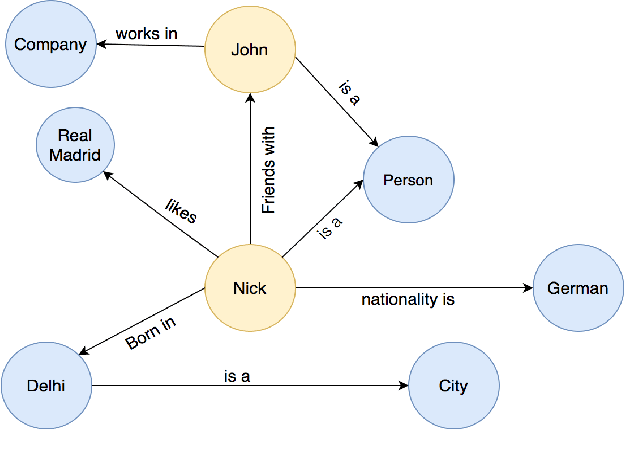
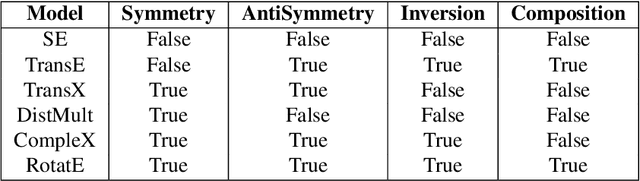
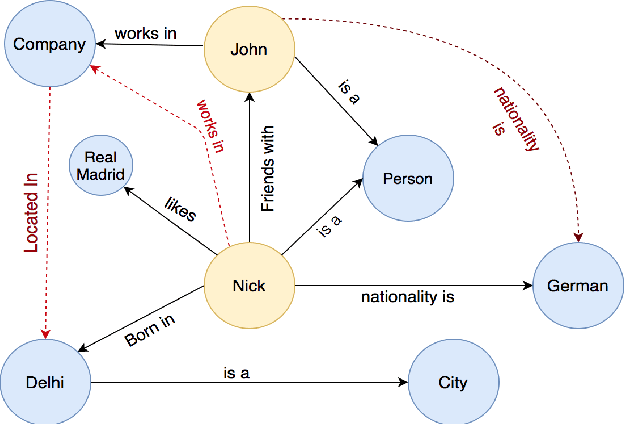
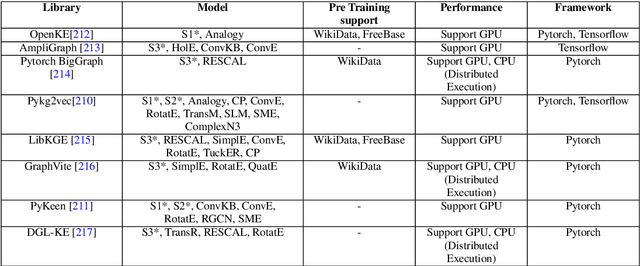
In recent years, Knowledge Graph (KG) development has attracted significant researches considering the applications in web search, relation prediction, natural language processing, information retrieval, question answering to name a few. However, often KGs are incomplete due to which Knowledge Graph Completion (KGC) has emerged as a sub-domain of research to automatically track down the missing connections in a KG. Numerous strategies have been suggested to work out the KGC dependent on different representation procedures intended to embed triples into a low-dimensional vector space. Given the difficulties related to KGC, researchers around the world are attempting to comprehend the attributes of the problem statement. This study intends to provide an overview of knowledge bases combined with different challenges and their impacts. We discuss existing KGC approaches, including the state-of-the-art Knowledge Graph Embeddings (KGE), not only on static graphs but also for the latest trends such as multimodal, temporal, and uncertain knowledge graphs. In addition, reinforcement learning techniques are reviewed to model complex queries as a link prediction problem. Subsequently, we explored popular software packages for model training and examine open research challenges that can guide future research.
On Continuous Integration / Continuous Delivery for Automated Deployment of Machine Learning Models using MLOps
Feb 07, 2022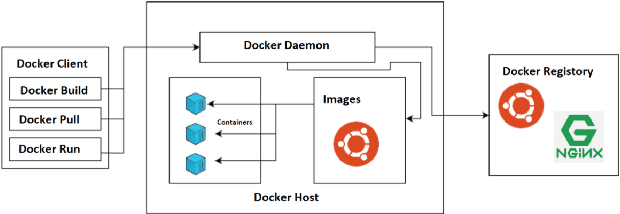
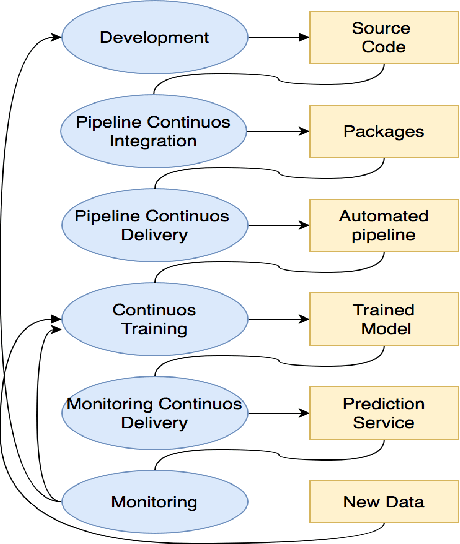
Model deployment in machine learning has emerged as an intriguing field of research in recent years. It is comparable to the procedure defined for conventional software development. Continuous Integration and Continuous Delivery (CI/CD) have been shown to smooth down software advancement and speed up businesses when used in conjunction with development and operations (DevOps). Using CI/CD pipelines in an application that includes Machine Learning Operations (MLOps) components, on the other hand, has difficult difficulties, and pioneers in the area solve them by using unique tools, which is typically provided by cloud providers. This research provides a more in-depth look at the machine learning lifecycle and the key distinctions between DevOps and MLOps. In the MLOps approach, we discuss tools and approaches for executing the CI/CD pipeline of machine learning frameworks. Following that, we take a deep look into push and pull-based deployments in Github Operations (GitOps). Open exploration issues are also identified and added, which may guide future study.
MOFit: A Framework to reduce Obesity using Machine learning and IoT
Aug 19, 2021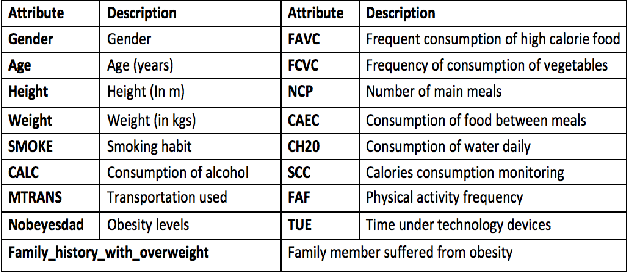
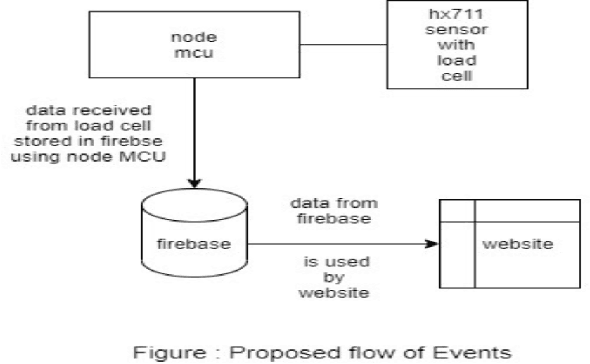
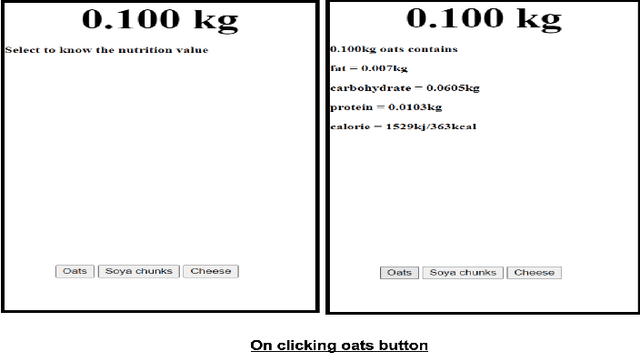
From the past few years, due to advancements in technologies, the sedentary living style in urban areas is at its peak. This results in individuals getting a victim of obesity at an early age. There are various health impacts of obesity like Diabetes, Heart disease, Blood pressure problems, and many more. Machine learning from the past few years is showing its implications in all expertise like forecasting, healthcare, medical imaging, sentiment analysis, etc. In this work, we aim to provide a framework that uses machine learning algorithms namely, Random Forest, Decision Tree, XGBoost, Extra Trees, and KNN to train models that would help predict obesity levels (Classification), Bodyweight, and fat percentage levels (Regression) using various parameters. We also applied and compared various hyperparameter optimization (HPO) algorithms such as Genetic algorithm, Random Search, Grid Search, Optuna to further improve the accuracy of the models. The website framework contains various other features like making customizable Diet plans, workout plans, and a dashboard to track the progress. The framework is built using the Python Flask. Furthermore, a weighing scale using the Internet of Things (IoT) is also integrated into the framework to track calories and macronutrients from food intake.
Towards a Multimodal System for Precision Agriculture using IoT and Machine Learning
Jul 10, 2021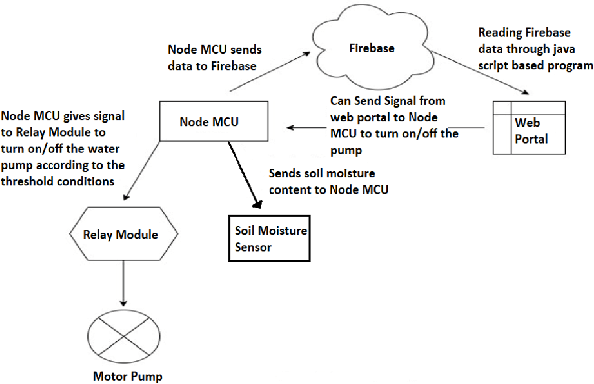
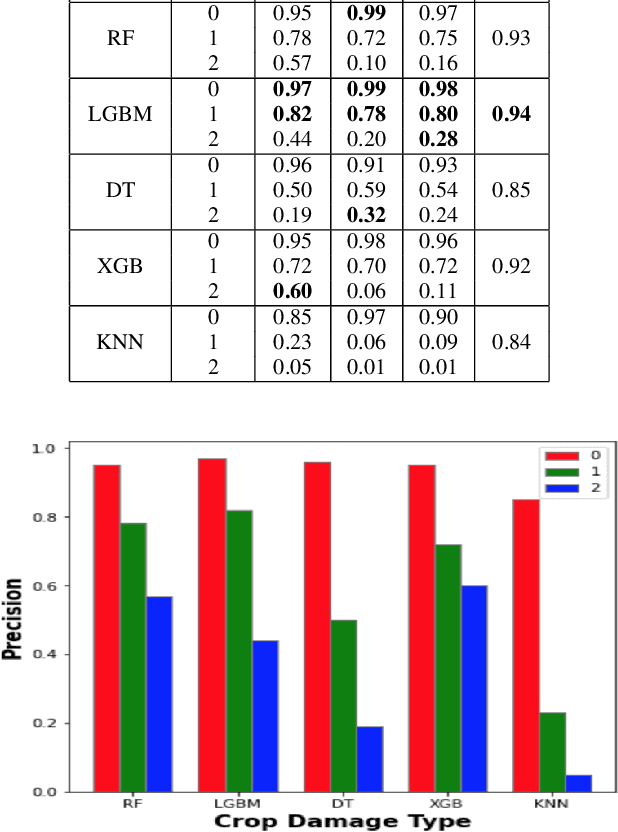

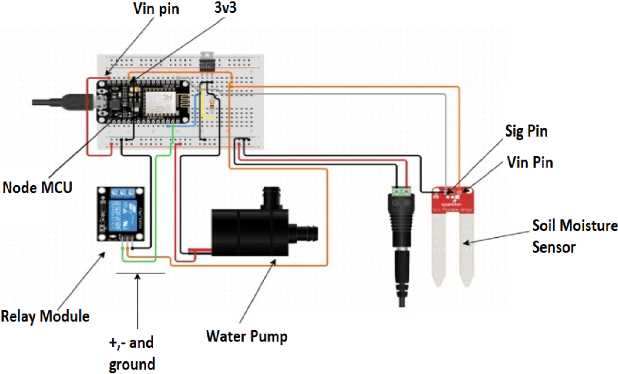
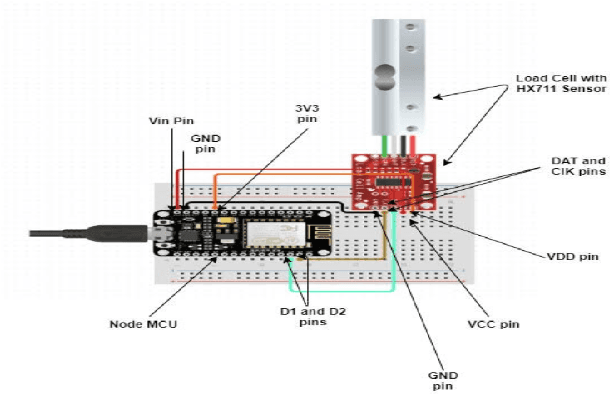
Precision agriculture system is an arising idea that refers to overseeing farms utilizing current information and communication technologies to improve the quantity and quality of yields while advancing the human work required. The automation requires the assortment of information given by the sensors such as soil, water, light, humidity, temperature for additional information to furnish the operator with exact data to acquire excellent yield to farmers. In this work, a study is proposed that incorporates all common state-of-the-art approaches for precision agriculture use. Technologies like the Internet of Things (IoT) for data collection, machine Learning for crop damage prediction, and deep learning for crop disease detection is used. The data collection using IoT is responsible for the measure of moisture levels for smart irrigation, n, p, k estimations of fertilizers for best yield development. For crop damage prediction, various algorithms like Random Forest (RF), Light gradient boosting machine (LGBM), XGBoost (XGB), Decision Tree (DT) and K Nearest Neighbor (KNN) are used. Subsequently, Pre-Trained Convolutional Neural Network (CNN) models such as VGG16, Resnet50, and DenseNet121 are also trained to check if the crop was tainted with some illness or not.
Evaluation of Time Series Forecasting Models for Estimation of PM2.5 Levels in Air
Apr 07, 2021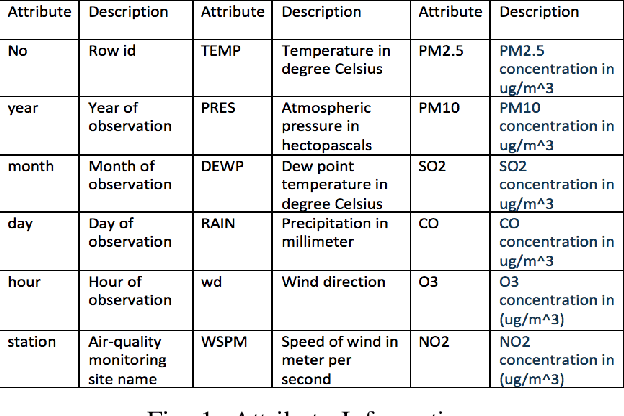
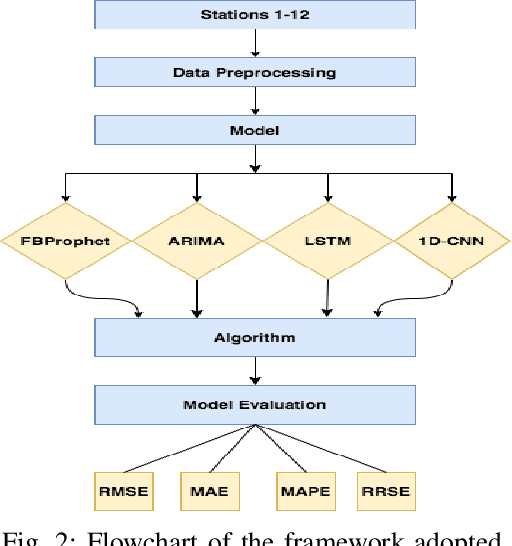
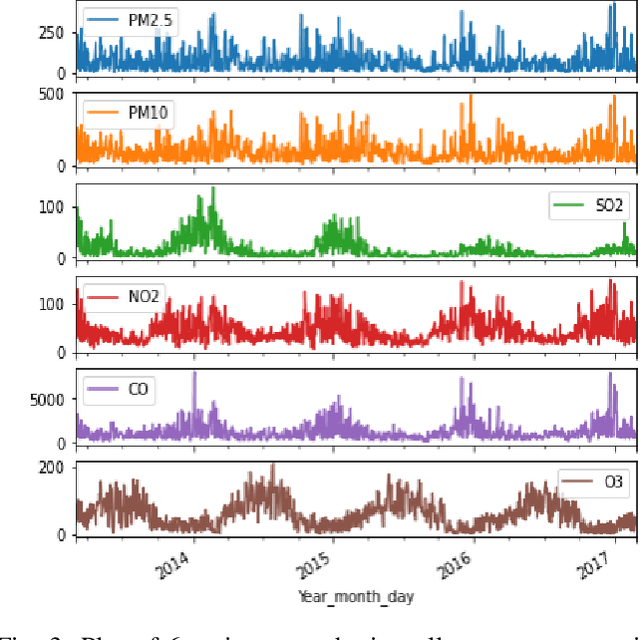
Air contamination in urban areas has risen consistently over the past few years. Due to expanding industrialization and increasing concentration of toxic gases in the climate, the air is getting more poisonous step by step at an alarming rate. Since the arrival of the Coronavirus pandemic, it is getting more critical to lessen air contamination to reduce its impact. The specialists and environmentalists are making a valiant effort to gauge air contamination levels. However, its genuinely unpredictable to mimic subatomic communication in the air, which brings about off base outcomes. There has been an ascent in using machine learning and deep learning models to foresee the results on time series data. This study adopts ARIMA, FBProphet, and deep learning models such as LSTM, 1D CNN, to estimate the concentration of PM2.5 in the environment. Our predicted results convey that all adopted methods give comparative outcomes in terms of average root mean squared error. However, the LSTM outperforms all other models with reference to mean absolute percentage error.
Drug Recommendation System based on Sentiment Analysis of Drug Reviews using Machine Learning
Apr 05, 2021



Since coronavirus has shown up, inaccessibility of legitimate clinical resources is at its peak, like the shortage of specialists, healthcare workers, lack of proper equipment and medicines. The entire medical fraternity is in distress, which results in numerous individuals demise. Due to unavailability, people started taking medication independently without appropriate consultation, making the health condition worse than usual. As of late, machine learning has been valuable in numerous applications, and there is an increase in innovative work for automation. This paper intends to present a drug recommender system that can drastically reduce specialists heap. In this research, we build a medicine recommendation system that uses patient reviews to predict the sentiment using various vectorization processes like Bow, TFIDF, Word2Vec, and Manual Feature Analysis, which can help recommend the top drug for a given disease by different classification algorithms. The predicted sentiments were evaluated by precision, recall, f1score, accuracy, and AUC score. The results show that classifier LinearSVC using TFIDF vectorization outperforms all other models with 93% accuracy.
Prediction of lung and colon cancer through analysis of histopathological images by utilizing Pre-trained CNN models with visualization of class activation and saliency maps
Mar 22, 2021
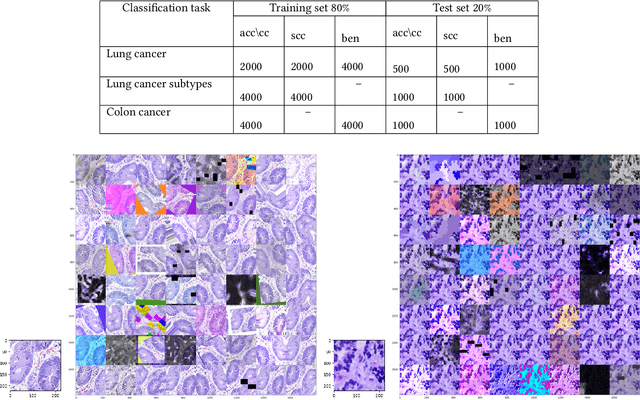

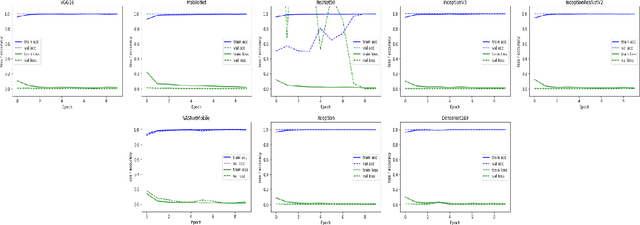
Colon and Lung cancer is one of the most perilous and dangerous ailments that individuals are enduring worldwide and has become a general medical problem. To lessen the risk of death, a legitimate and early finding is particularly required. In any case, it is a truly troublesome task that depends on the experience of histopathologists. If a histologist is under-prepared it may even hazard the life of a patient. As of late, deep learning has picked up energy, and it is being valued in the analysis of Medical Imaging. This paper intends to utilize and alter the current pre-trained CNN-based model to identify lung and colon cancer utilizing histopathological images with better augmentation techniques. In this paper, eight distinctive Pre-trained CNN models, VGG16, NASNetMobile, InceptionV3, InceptionResNetV2, ResNet50, Xception, MobileNet, and DenseNet169 are trained on LC25000 dataset. The model performances are assessed on precision, recall, f1score, accuracy, and auroc score. The results exhibit that all eight models accomplished noteworthy results ranging from 96% to 100% accuracy. Subsequently, GradCAM and SmoothGrad are also used to picture the attention images of Pre-trained CNN models classifying malignant and benign images.