 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Alignment of Modalities in Large Vision Language Models
Mar 25, 2025



Recent advancements in vision-language models have achieved remarkable results in making language models understand vision inputs. However, a unified approach to align these models across diverse tasks such as image captioning and visual question answering remains a challenge. Existing methods either require very big language models or very big datasets which is not efficient in utilizing existing models. This paper addresses this gap and devises a training strategy of auto-regressive vision-language models, to unify vision-language tasks like image-captioning and visual question answering. We propose four training stages for aligning the vision model with the language model, in other words, the language model is given an ability to process visual inputs. We also devise different attention masks for training transformer-based language models that improve the quality of visual features. Further, we introduce some findings, 1) the attention mask should not be applied on visual inputs, 2) the Language model converges faster on AI- generated data, 3) More work should be done in the alignment stage during the pre-training of the model, 4) the model can easily adapt to any downstream tasks like visual question answering on healthcare datasets like PathVQA. After training the model for one epoch for all the stages, it outperforms large models like VILA-13 billion models on common benchmarks like CIDEr scores on COCO and Flickr30k datasets and achieves very close scores to GIT-2 on the same dataset despite being a much smaller model trained on a much smaller dataset. All of the training is done using best practices available like multi- GPU parallel training, lower-precision training with 16-bit float numbers, faster attention (SDPA), and gradient accumulation, and completed the training within 12 hours.
On Continuous Integration / Continuous Delivery for Automated Deployment of Machine Learning Models using MLOps
Feb 07, 2022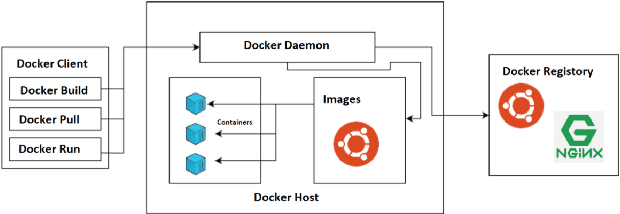
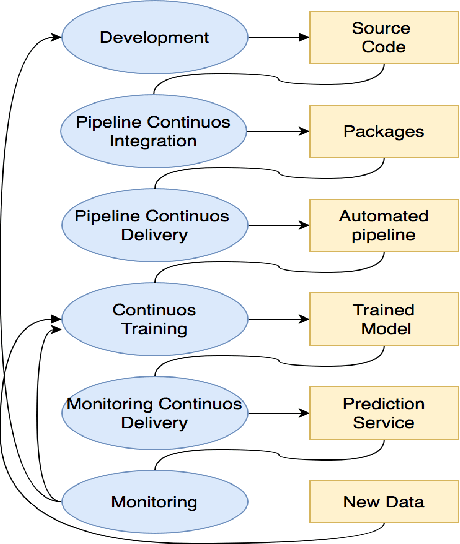
Model deployment in machine learning has emerged as an intriguing field of research in recent years. It is comparable to the procedure defined for conventional software development. Continuous Integration and Continuous Delivery (CI/CD) have been shown to smooth down software advancement and speed up businesses when used in conjunction with development and operations (DevOps). Using CI/CD pipelines in an application that includes Machine Learning Operations (MLOps) components, on the other hand, has difficult difficulties, and pioneers in the area solve them by using unique tools, which is typically provided by cloud providers. This research provides a more in-depth look at the machine learning lifecycle and the key distinctions between DevOps and MLOps. In the MLOps approach, we discuss tools and approaches for executing the CI/CD pipeline of machine learning frameworks. Following that, we take a deep look into push and pull-based deployments in Github Operations (GitOps). Open exploration issues are also identified and added, which may guide future study.