 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefined Gradient-Based Temperature Optimization for the Replica-Exchange Monte-Carlo Method
Jan 20, 2026The replica-exchange Monte-Carlo (RXMC) method is a powerful Markov-chain Monte-Carlo algorithm for sampling from multi-modal distributions, which are challenging for conventional methods. The sampling efficiency of the RXMC method depends highly on the selection of the temperatures, and finding optimal temperatures remains a challenge. In this study, we propose a refined online temperature selection method by extending the gradient-based optimization framework proposed previously. Building upon the existing temperature update approach, we introduce a reparameterization technique to strictly enforce physical constraints, such as the monotonic ordering of inverse temperatures, which were not explicitly addressed in the original formulation. The proposed method defines the variance of acceptance rates between adjacent replicas as a loss function, estimates its gradient using differential information from the sampling process, and optimizes the temperatures via gradient descent. We demonstrate the effectiveness of our method through experiments on benchmark spin systems, including the two-dimensional ferromagnetic Ising model, the two-dimensional ferromagnetic XY model, and the three-dimensional Edwards-Anderson model. Our results show that the method successfully achieves uniform acceptance rates and reduces round-trip times across the temperature space. Furthermore, our proposed method offers a significant advantage over recently proposed policy gradient method that require careful hyperparameter tuning, while simultaneously preventing the constraint violations that destabilize optimization.
Transfer Learning for Deep-Unfolded Combinatorial Optimization Solver with Quantum Annealer
Jan 07, 2025



Quantum annealing (QA) has attracted research interest as a sampler and combinatorial optimization problem (COP) solver. A recently proposed sampling-based solver for QA significantly reduces the required number of qubits, being capable of large COPs. In relation to this, a trainable sampling-based COP solver has been proposed that optimizes its internal parameters from a dataset by using a deep learning technique called deep unfolding. Although learning the internal parameters accelerates the convergence speed, the sampler in the trainable solver is restricted to using a classical sampler owing to the training cost. In this study, to utilize QA in the trainable solver, we propose classical-quantum transfer learning, where parameters are trained classically, and the trained parameters are used in the solver with QA. The results of numerical experiments demonstrate that the trainable quantum COP solver using classical-quantum transfer learning improves convergence speed and execution time over the original solver.
Accelerating Convergence of Stein Variational Gradient Descent via Deep Unfolding
Feb 23, 2024Stein variational gradient descent (SVGD) is a prominent particle-based variational inference method used for sampling a target distribution. SVGD has attracted interest for application in machine-learning techniques such as Bayesian inference. In this paper, we propose novel trainable algorithms that incorporate a deep-learning technique called deep unfolding,into SVGD. This approach facilitates the learning of the internal parameters of SVGD, thereby accelerating its convergence speed. To evaluate the proposed trainable SVGD algorithms, we conducted numerical simulations of three tasks: sampling a one-dimensional Gaussian mixture, performing Bayesian logistic regression, and learning Bayesian neural networks. The results show that our proposed algorithms exhibit faster convergence than the conventional variants of SVGD.
Convergence Acceleration of Markov Chain Monte Carlo-based Gradient Descent by Deep Unfolding
Feb 21, 2024This study proposes a trainable sampling-based solver for combinatorial optimization problems (COPs) using a deep-learning technique called deep unfolding. The proposed solver is based on the Ohzeki method that combines Markov-chain Monte-Carlo (MCMC) and gradient descent, and its step sizes are trained by minimizing a loss function. In the training process, we propose a sampling-based gradient estimation that substitutes auto-differentiation with a variance estimation, thereby circumventing the failure of back propagation due to the non-differentiability of MCMC. The numerical results for a few COPs demonstrated that the proposed solver significantly accelerated the convergence speed compared with the original Ohzeki method.
Deep Unfolded Simulated Bifurcation for Massive MIMO Signal Detection
Jun 28, 2023Multiple-input multiple-output (MIMO) is a key ingredient of next-generation wireless communications. Recently, various MIMO signal detectors based on deep learning techniques and quantum(-inspired) algorithms have been proposed to improve the detection performance compared with conventional detectors. This paper focuses on the simulated bifurcation (SB) algorithm, a quantum-inspired algorithm. This paper proposes two techniques to improve its detection performance. The first is modifying the algorithm inspired by the Levenberg-Marquardt algorithm to eliminate local minima of maximum likelihood detection. The second is the use of deep unfolding, a deep learning technique to train the internal parameters of an iterative algorithm. We propose a deep-unfolded SB by making the update rule of SB differentiable. The numerical results show that these proposed detectors significantly improve the signal detection performance in massive MIMO systems.
Hubbard-Stratonovich Detector for Simple Trainable MIMO Signal Detection
Feb 09, 2023Massive multiple-input multiple-output (MIMO) is a key technology used in fifth-generation wireless communication networks and beyond. Recently, various MIMO signal detectors based on deep learning have been proposed. Especially, deep unfolding (DU), which involves unrolling of an existing iterative algorithm and embedding of trainable parameters, has been applied with remarkable detection performance. Although DU has a lesser number of trainable parameters than conventional deep neural networks, the computational complexities related to training and execution have been problematic because DU-based MIMO detectors usually utilize matrix inversion to improve their detection performance. In this study, we attempted to construct a DU-based trainable MIMO detector with the simplest structure. The proposed detector based on the Hubbard--Stratonovich (HS) transformation and DU is called the trainable HS (THS) detector. It requires only $O(1)$ trainable parameters and its training and execution cost is $O(n^2)$ per iteration, where $n$ is the number of transmitting antennas. Numerical results show that the detection performance of the THS detector is better than that of existing algorithms of the same complexity and close to that of a DU-based detector, which has higher training and execution costs than the THS detector.
Convergence Acceleration via Chebyshev Step: Plausible Interpretation of Deep-Unfolded Gradient Descent
Oct 26, 2020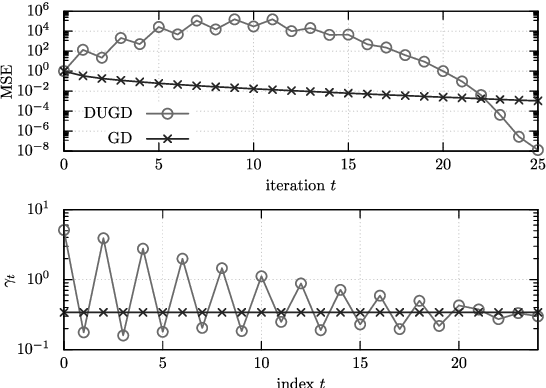

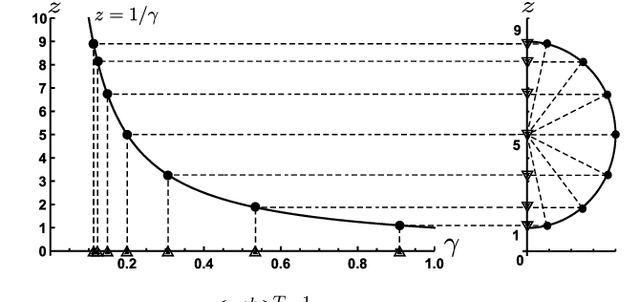
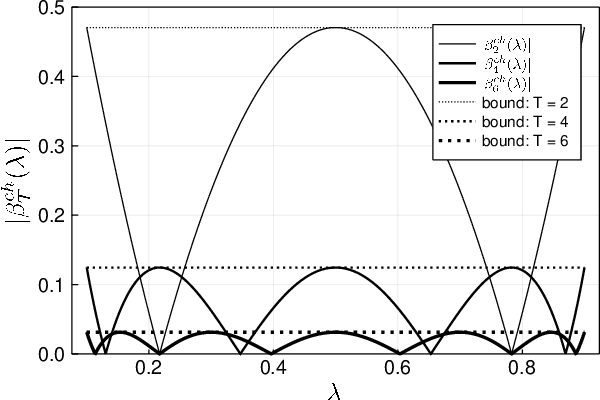
Deep unfolding is a promising deep-learning technique, whose network architecture is based on expanding the recursive structure of existing iterative algorithms. Although convergence acceleration is a remarkable advantage of deep unfolding, its theoretical aspects have not been revealed yet. The first half of this study details the theoretical analysis of the convergence acceleration in deep-unfolded gradient descent (DUGD) whose trainable parameters are step sizes. We propose a plausible interpretation of the learned step-size parameters in DUGD by introducing the principle of Chebyshev steps derived from Chebyshev polynomials. The use of Chebyshev steps in gradient descent (GD) enables us to bound the spectral radius of a matrix governing the convergence speed of GD, leading to a tight upper bound on the convergence rate. The convergence rate of GD using Chebyshev steps is shown to be asymptotically optimal, although it has no momentum terms. We also show that Chebyshev steps numerically explain the learned step-size parameters in DUGD well. In the second half of the study, %we apply the theory of Chebyshev steps and Chebyshev-periodical successive over-relaxation (Chebyshev-PSOR) is proposed for accelerating linear/nonlinear fixed-point iterations. Theoretical analysis and numerical experiments indicate that Chebyshev-PSOR exhibits significantly faster convergence for various examples such as Jacobi method and proximal gradient methods.
Deep Unfolded Multicast Beamforming
Apr 20, 2020



Multicast beamforming is a promising technique for multicast communication. Providing an efficient and powerful beamforming design algorithm is a crucial issue because multicast beamforming problems such as a max-min-fair problem are NP-hard in general. Recently, deep learning-based approaches have been proposed for beamforming design. Although these approaches using deep neural networks exhibit reasonable performance gain compared with conventional optimization-based algorithms, their scalability is an emerging problem for large systems in which beamforming design becomes a more demanding task. In this paper, we propose a novel deep unfolded trainable beamforming design with high scalability and efficiency. The algorithm is designed by expanding the recursive structure of an existing algorithm based on projections onto convex sets and embedding a constant number of trainable parameters to the expanded network, which leads to a scalable and stable training process. Numerical results show that the proposed algorithm can accelerate its convergence speed by using unsupervised learning, which is a challenging training process for deep unfolding.
Theoretical Interpretation of Learned Step Size in Deep-Unfolded Gradient Descent
Jan 30, 2020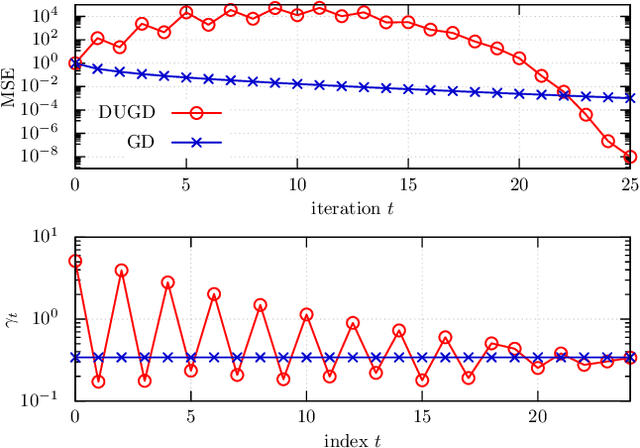
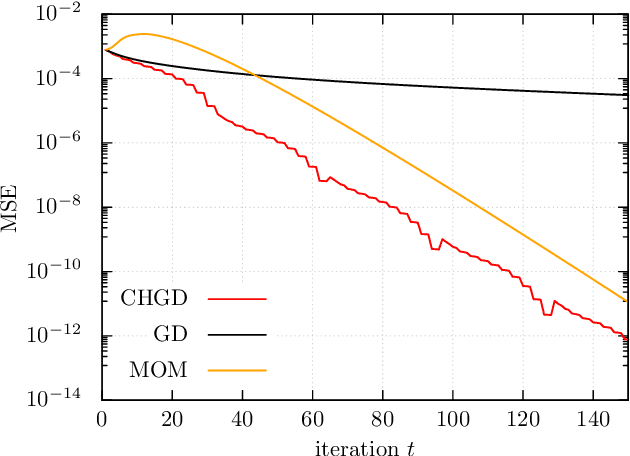


Deep unfolding is a promising deep-learning technique in which an iterative algorithm is unrolled to a deep network architecture with trainable parameters. In the case of gradient descent algorithms, as a result of the training process, one often observes the acceleration of the convergence speed with learned non-constant step size parameters whose behavior is not intuitive nor interpretable from conventional theory. In this paper, we provide a theoretical interpretation of the learned step size of deep-unfolded gradient descent (DUGD). We first prove that the training process of DUGD reduces not only the mean squared error loss but also the spectral radius related to the convergence rate. Next, we show that minimizing the upper bound of the spectral radius naturally leads to the Chebyshev step which is a sequence of the step size based on Chebyshev polynomials. The numerical experiments confirm that the Chebyshev steps qualitatively reproduce the learned step size parameters in DUGD, which provides a plausible interpretation of the learned parameters. Additionally, we show that the Chebyshev steps achieve the lower bound of the convergence rate for the first-order method in a specific limit without learning parameters or momentum terms.
Trainable Projected Gradient Detector for Sparsely Spread Code Division Multiple Access
Oct 23, 2019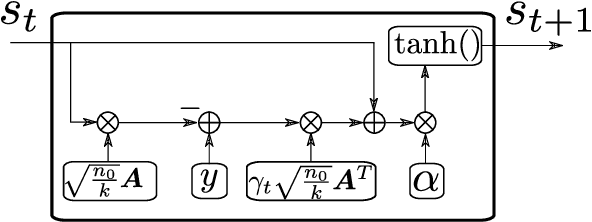



Sparsely spread code division multiple access (SCDMA) is a promising non-orthogonal multiple access technique for future wireless communications. In this paper, we propose a novel trainable multiuser detector called sparse trainable projected gradient (STPG) detector, which is based on the notion of deep unfolding. In the STPG detector, trainable parameters are embedded to a projected gradient descent algorithm, which can be trained by standard deep learning techniques such as back propagation and stochastic gradient descent. Advantages of the detector are its low computational cost and small number of trainable parameters, which enables us to treat massive SCDMA systems. In particular, its computational cost is smaller than a conventional belief propagation (BP) detector while the STPG detector exhibits nearly same detection performance with a BP detector. We also propose a scalable joint learning of signature sequences and the STPG detector for signature design. Numerical results show that the joint learning improves multiuser detection performance particular in the low SNR regime.