 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBangla Image Caption Generation through CNN-Transformer based Encoder-Decoder Network
Oct 24, 2021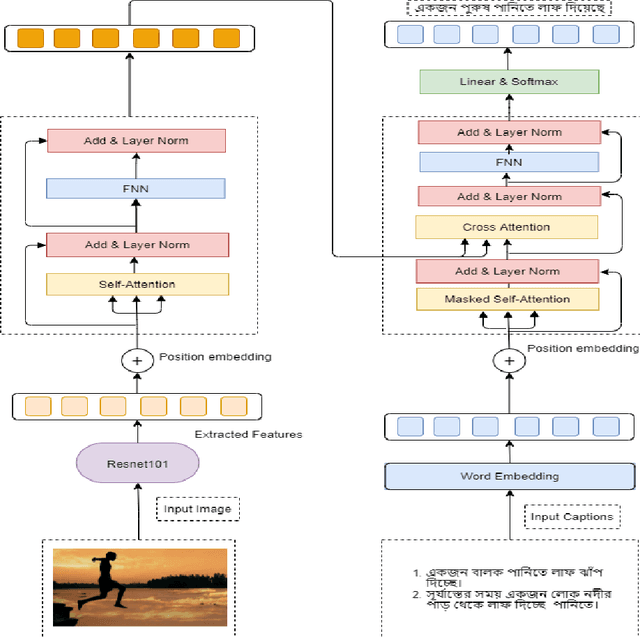

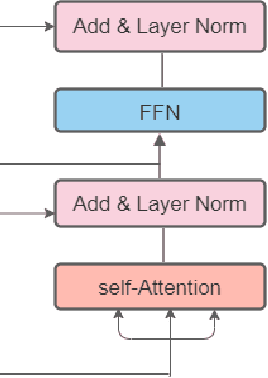
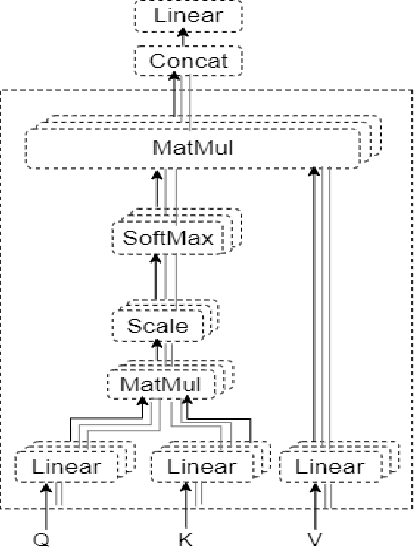
Automatic Image Captioning is the never-ending effort of creating syntactically and validating the accuracy of textual descriptions of an image in natural language with context. The encoder-decoder structure used throughout existing Bengali Image Captioning (BIC) research utilized abstract image feature vectors as the encoder's input. We propose a novel transformer-based architecture with an attention mechanism with a pre-trained ResNet-101 model image encoder for feature extraction from images. Experiments demonstrate that the language decoder in our technique captures fine-grained information in the caption and, then paired with image features, produces accurate and diverse captions on the BanglaLekhaImageCaptions dataset. Our approach outperforms all existing Bengali Image Captioning work and sets a new benchmark by scoring 0.694 on BLEU-1, 0.630 on BLEU-2, 0.582 on BLEU-3, and 0.337 on METEOR.