 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Prominence of Artificial Intelligence in COVID-19
Nov 18, 2021

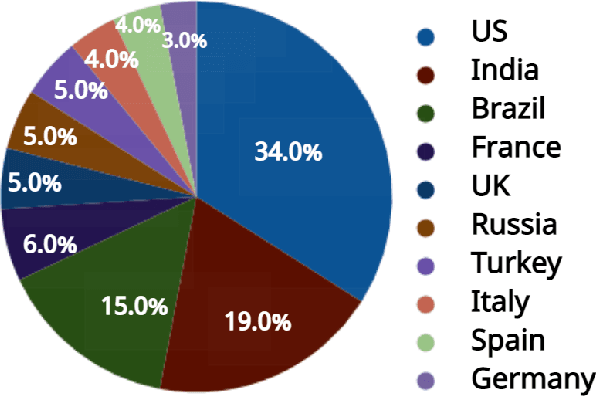
In December 2019, a novel virus called COVID-19 had caused an enormous number of causalities to date. The battle with the novel Coronavirus is baffling and horrifying after the Spanish Flu 2019. While the front-line doctors and medical researchers have made significant progress in controlling the spread of the highly contiguous virus, technology has also proved its significance in the battle. Moreover, Artificial Intelligence has been adopted in many medical applications to diagnose many diseases, even baffling experienced doctors. Therefore, this survey paper explores the methodologies proposed that can aid doctors and researchers in early and inexpensive methods of diagnosis of the disease. Most developing countries have difficulties carrying out tests using the conventional manner, but a significant way can be adopted with Machine and Deep Learning. On the other hand, the access to different types of medical images has motivated the researchers. As a result, a mammoth number of techniques are proposed. This paper first details the background knowledge of the conventional methods in the Artificial Intelligence domain. Following that, we gather the commonly used datasets and their use cases to date. In addition, we also show the percentage of researchers adopting Machine Learning over Deep Learning. Thus we provide a thorough analysis of this scenario. Lastly, in the research challenges, we elaborate on the problems faced in COVID-19 research, and we address the issues with our understanding to build a bright and healthy environment.
Bangla Image Caption Generation through CNN-Transformer based Encoder-Decoder Network
Oct 24, 2021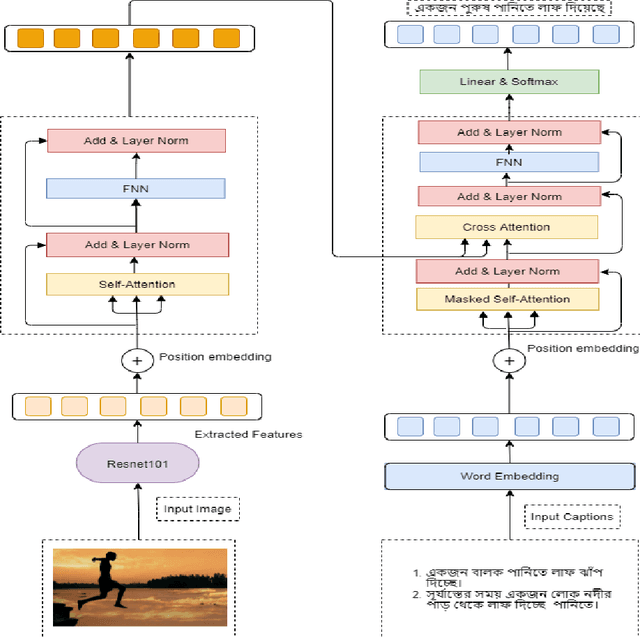

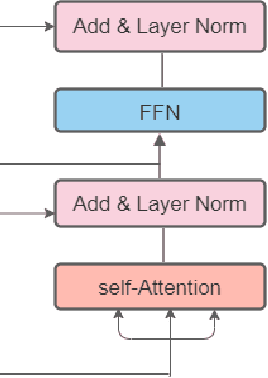
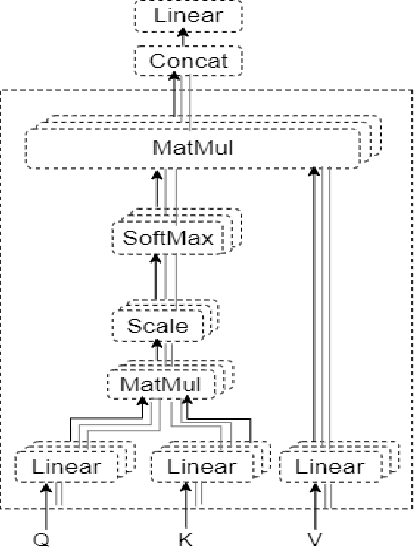
Automatic Image Captioning is the never-ending effort of creating syntactically and validating the accuracy of textual descriptions of an image in natural language with context. The encoder-decoder structure used throughout existing Bengali Image Captioning (BIC) research utilized abstract image feature vectors as the encoder's input. We propose a novel transformer-based architecture with an attention mechanism with a pre-trained ResNet-101 model image encoder for feature extraction from images. Experiments demonstrate that the language decoder in our technique captures fine-grained information in the caption and, then paired with image features, produces accurate and diverse captions on the BanglaLekhaImageCaptions dataset. Our approach outperforms all existing Bengali Image Captioning work and sets a new benchmark by scoring 0.694 on BLEU-1, 0.630 on BLEU-2, 0.582 on BLEU-3, and 0.337 on METEOR.
Fine-Grained Image Generation from Bangla Text Description using Attentional Generative Adversarial Network
Sep 24, 2021
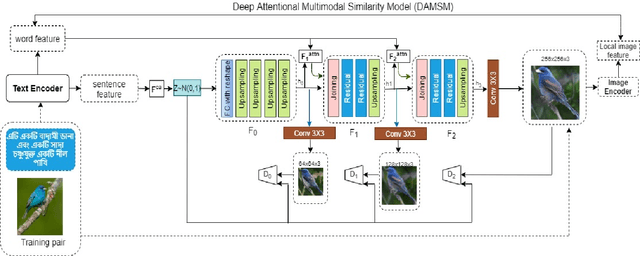


Generating fine-grained, realistic images from text has many applications in the visual and semantic realm. Considering that, we propose Bangla Attentional Generative Adversarial Network (AttnGAN) that allows intensified, multi-stage processing for high-resolution Bangla text-to-image generation. Our model can integrate the most specific details at different sub-regions of the image. We distinctively concentrate on the relevant words in the natural language description. This framework has achieved a better inception score on the CUB dataset. For the first time, a fine-grained image is generated from Bangla text using attentional GAN. Bangla has achieved 7th position among 100 most spoken languages. This inspires us to explicitly focus on this language, which will ensure the inevitable need of many people. Moreover, Bangla has a more complex syntactic structure and less natural language processing resource that validates our work more.