 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Hostile Posts using Relational Graph Convolutional Network
Jan 10, 2021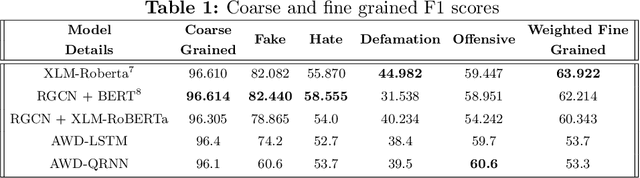
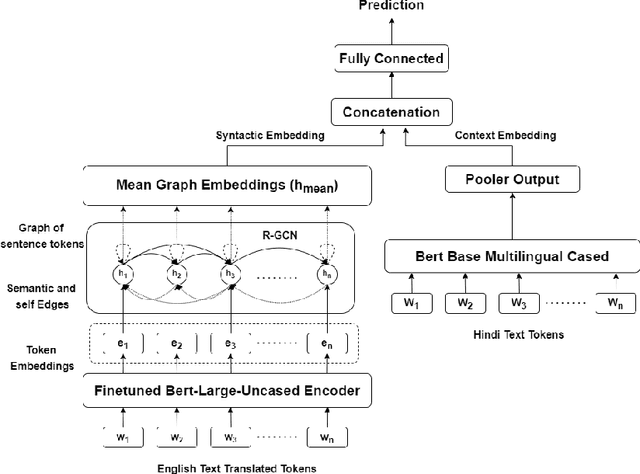
This work is based on the submission to the competition Hindi Constraint conducted by AAAI@2021 for detection of hostile posts in Hindi on social media platforms. Here, a model is presented for detection and classification of hostile posts and further classify into fake, offensive, hate and defamation using Relational Graph Convolutional Networks. Unlike other existing work, our approach is focused on using semantic meaning along with contextutal information for better classification. The results from AAAI@2021 indicates that the proposed model is performing at par with Google's XLM-RoBERTa on the given dataset. Our best submission with RGCN achieves an F1 score of 0.97 (7th Rank) on coarse-grained evaluation and achieved best performance on identifying fake posts. Among all submissions to the challenge, our classification system with XLM-Roberta secured 2nd rank on fine-grained classification.
EmbPred30: Assessing 30-days Readmission for Diabetic Patients using Categorical Embeddings
Feb 25, 2020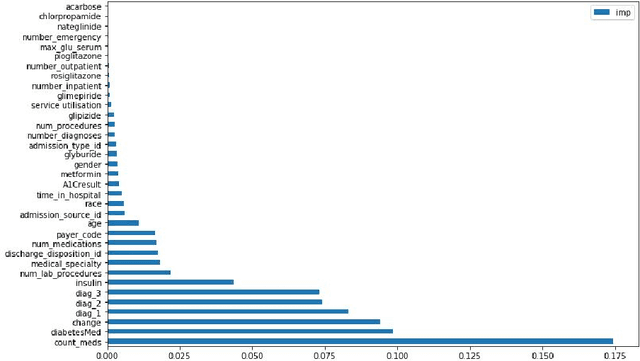
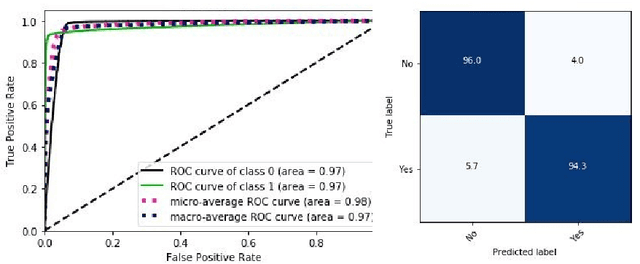
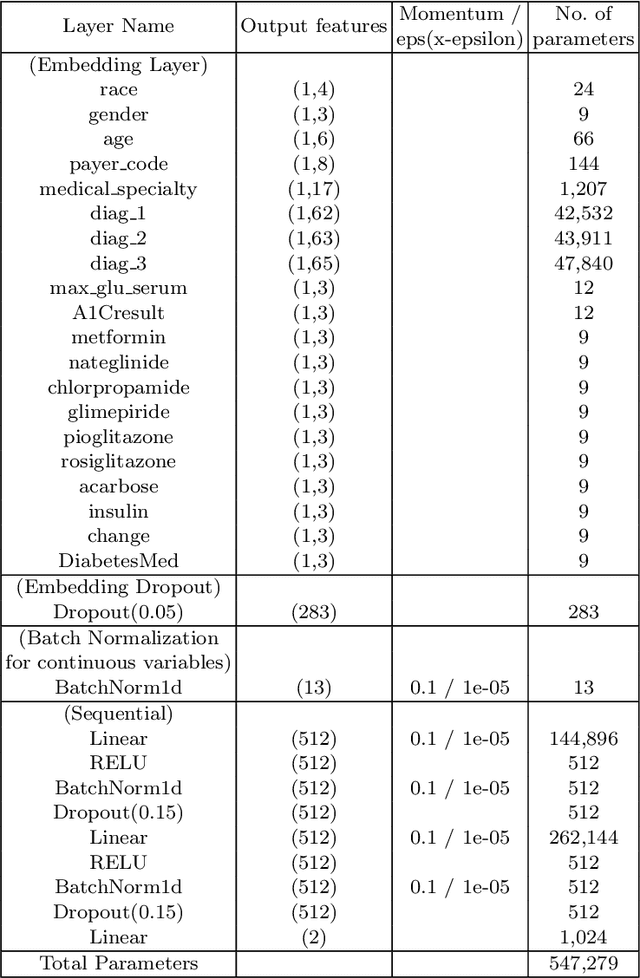
Hospital readmission is a crucial healthcare quality measure that helps in determining the level of quality of care that a hospital offers to a patient and has proven to be immensely expensive. It is estimated that more than $25 billion are spent yearly due to readmission of diabetic patients in the USA. This paper benchmarks existing models and proposes a new embedding based state-of-the-art deep neural network(DNN). The model can identify whether a hospitalized diabetic patient will be readmitted within 30 days or not with an accuracy of 95.2% and Area Under the Receiver Operating Characteristics(AUROC) of 97.4% on data collected from 130 US hospitals between 1999-2008. The results are encouraging with patients having changes in medication while admitted having a high chance of getting readmitted. Identifying prospective patients for readmission could help the hospital systems in improving their inpatient care, thereby saving them from unnecessary expenditures.
Spoken Language Identification using ConvNets
Oct 09, 2019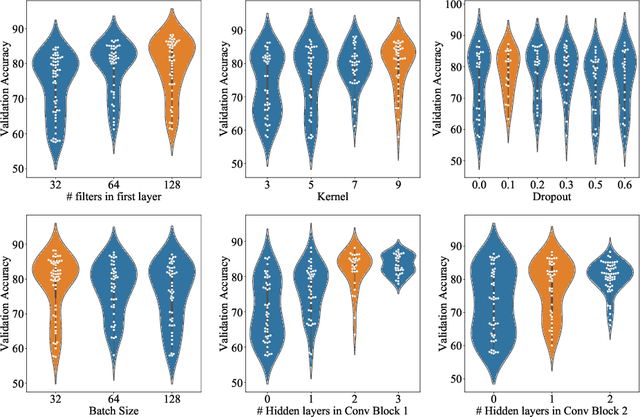
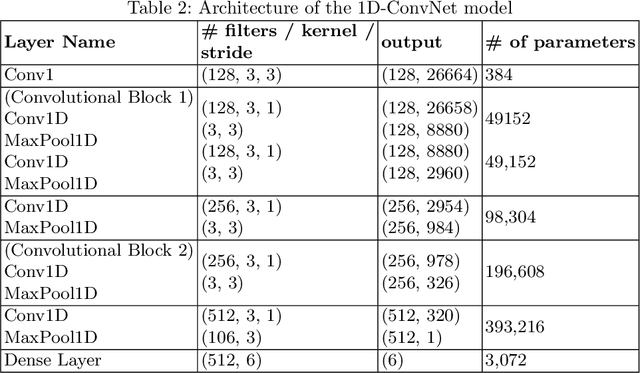
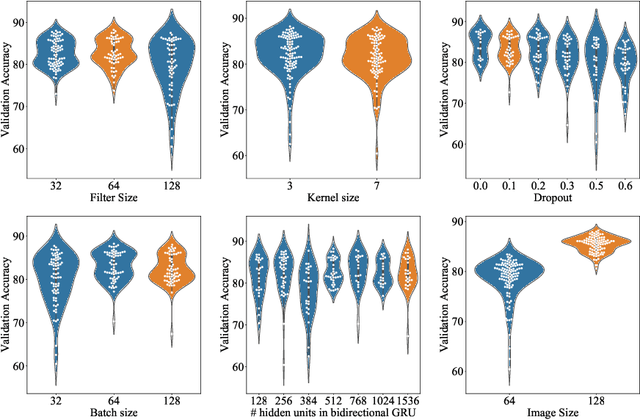
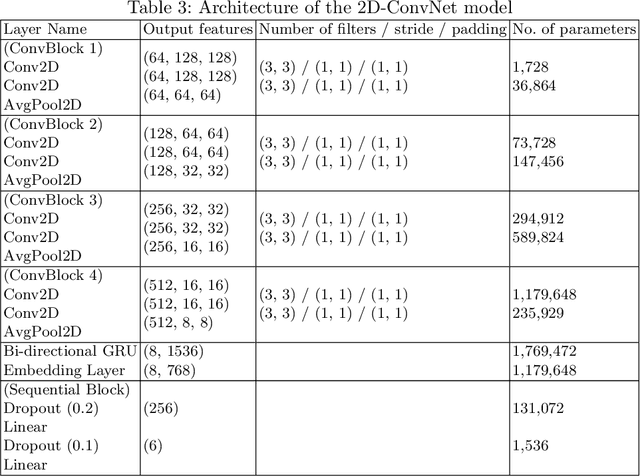
Language Identification (LI) is an important first step in several speech processing systems. With a growing number of voice-based assistants, speech LI has emerged as a widely researched field. To approach the problem of identifying languages, we can either adopt an implicit approach where only the speech for a language is present or an explicit one where text is available with its corresponding transcript. This paper focuses on an implicit approach due to the absence of transcriptive data. This paper benchmarks existing models and proposes a new attention based model for language identification which uses log-Mel spectrogram images as input. We also present the effectiveness of raw waveforms as features to neural network models for LI tasks. For training and evaluation of models, we classified six languages (English, French, German, Spanish, Russian and Italian) with an accuracy of 95.4% and four languages (English, French, German, Spanish) with an accuracy of 96.3% obtained from the VoxForge dataset. This approach can further be scaled to incorporate more languages.