 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposing the Probabilistic Causal Structure of Discrimination
Mar 08, 2017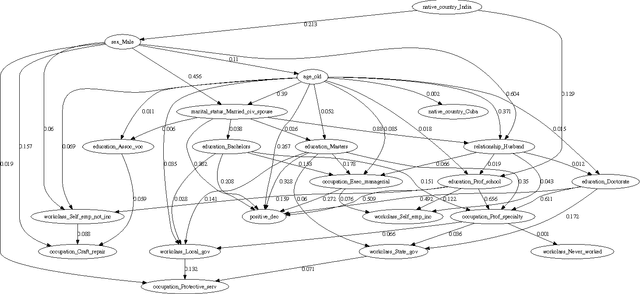
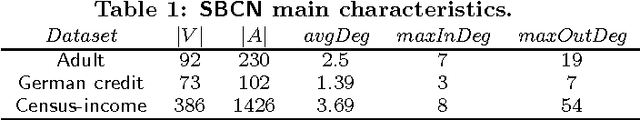
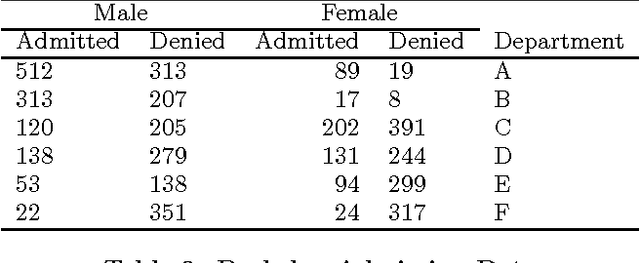
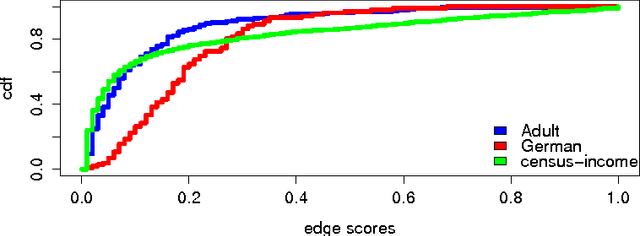
Discrimination discovery from data is an important task aiming at identifying patterns of illegal and unethical discriminatory activities against protected-by-law groups, e.g., ethnic minorities. While any legally-valid proof of discrimination requires evidence of causality, the state-of-the-art methods are essentially correlation-based, albeit, as it is well known, correlation does not imply causation. In this paper we take a principled causal approach to the data mining problem of discrimination detection in databases. Following Suppes' probabilistic causation theory, we define a method to extract, from a dataset of historical decision records, the causal structures existing among the attributes in the data. The result is a type of constrained Bayesian network, which we dub Suppes-Bayes Causal Network (SBCN). Next, we develop a toolkit of methods based on random walks on top of the SBCN, addressing different anti-discrimination legal concepts, such as direct and indirect discrimination, group and individual discrimination, genuine requirement, and favoritism. Our experiments on real-world datasets confirm the inferential power of our approach in all these different tasks.