 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Monotonic Aggregation for Open-domain QA
Aug 08, 2023Question answering (QA) is a critical task for speech-based retrieval from knowledge sources, by sifting only the answers without requiring to read supporting documents. Specifically, open-domain QA aims to answer user questions on unrestricted knowledge sources. Ideally, adding a source should not decrease the accuracy, but we find this property (denoted as "monotonicity") does not hold for current state-of-the-art methods. We identify the cause, and based on that we propose Judge-Specialist framework. Our framework consists of (1) specialist retrievers/readers to cover individual sources, and (2) judge, a dedicated language model to select the final answer. Our experiments show that our framework not only ensures monotonicity, but also outperforms state-of-the-art multi-source QA methods on Natural Questions. Additionally, we show that our models robustly preserve the monotonicity against noise from speech recognition. We publicly release our code and setting.
When to Read Documents or QA History: On Unified and Selective Open-domain QA
Jun 07, 2023
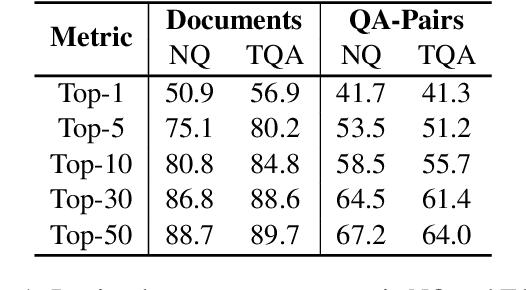
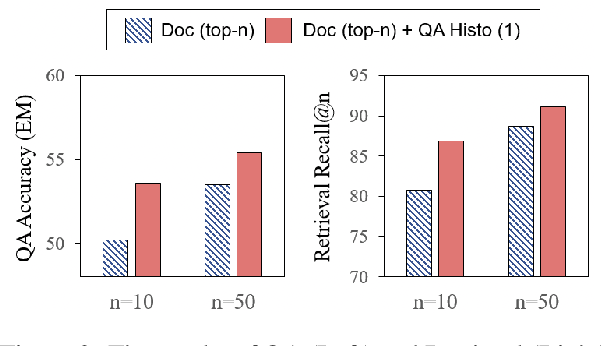
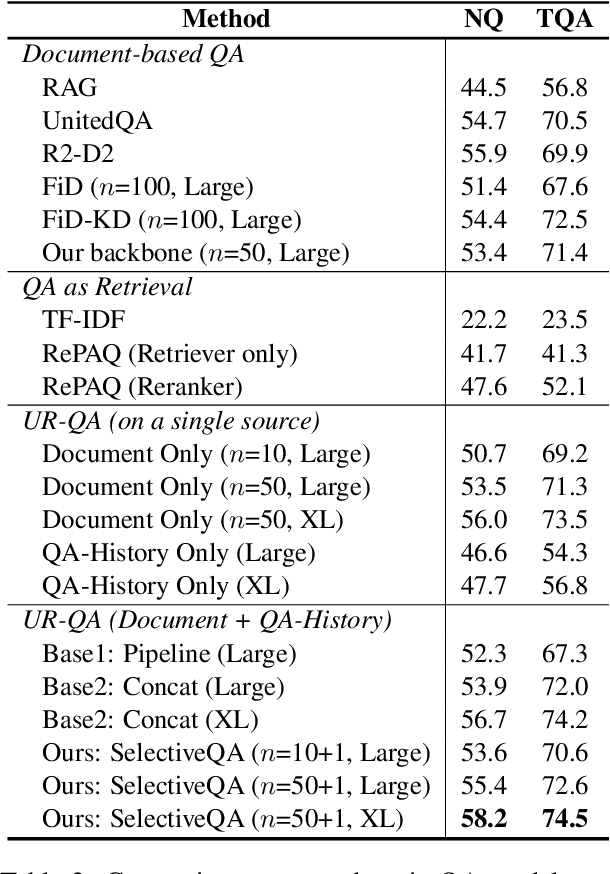
This paper studies the problem of open-domain question answering, with the aim of answering a diverse range of questions leveraging knowledge resources. Two types of sources, QA-pair and document corpora, have been actively leveraged with the following complementary strength. The former is highly precise when the paraphrase of given question $q$ was seen and answered during training, often posed as a retrieval problem, while the latter generalizes better for unseen questions. A natural follow-up is thus leveraging both models, while a naive pipelining or integration approaches have failed to bring additional gains over either model alone. Our distinction is interpreting the problem as calibration, which estimates the confidence of predicted answers as an indicator to decide when to use a document or QA-pair corpus. The effectiveness of our method was validated on widely adopted benchmarks such as Natural Questions and TriviaQA.
Robustifying Multi-hop QA through Pseudo-Evidentiality Training
Jul 07, 2021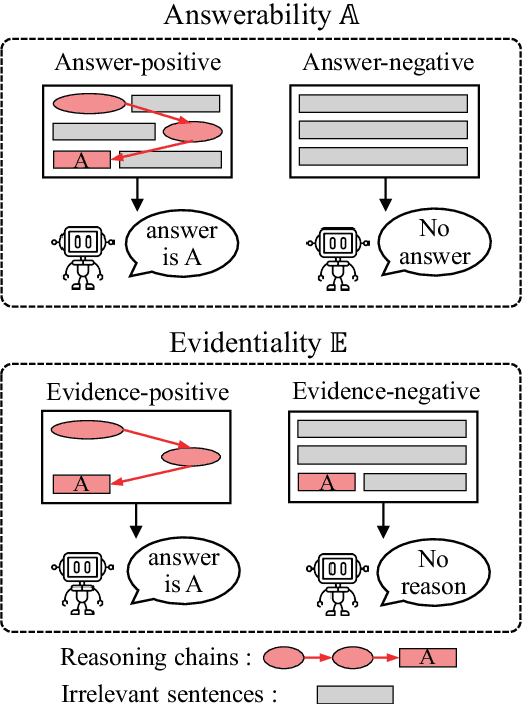
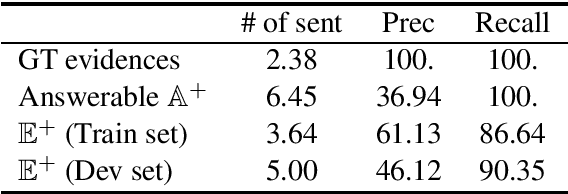
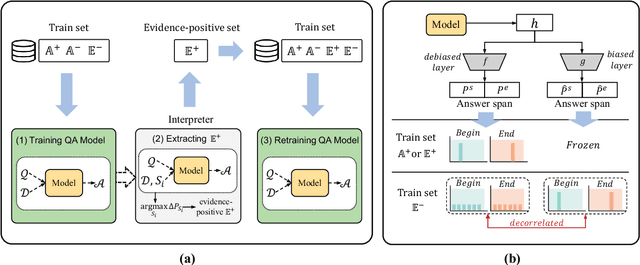
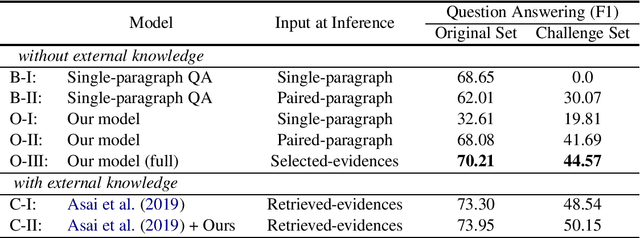
This paper studies the bias problem of multi-hop question answering models, of answering correctly without correct reasoning. One way to robustify these models is by supervising to not only answer right, but also with right reasoning chains. An existing direction is to annotate reasoning chains to train models, requiring expensive additional annotations. In contrast, we propose a new approach to learn evidentiality, deciding whether the answer prediction is supported by correct evidences, without such annotations. Instead, we compare counterfactual changes in answer confidence with and without evidence sentences, to generate "pseudo-evidentiality" annotations. We validate our proposed model on an original set and challenge set in HotpotQA, showing that our method is accurate and robust in multi-hop reasoning.