 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeighborhood Information-based Probabilistic Algorithm for Network Disintegration
Mar 08, 2020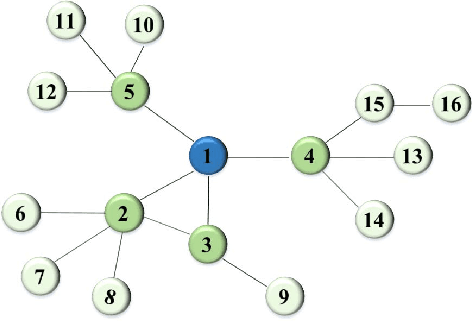

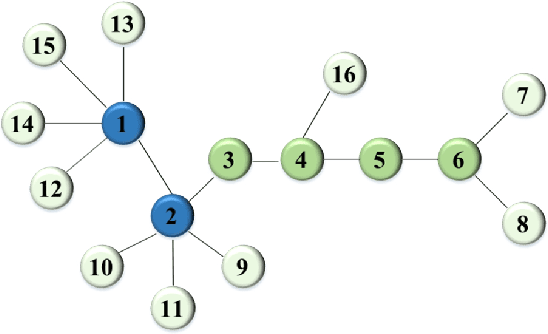

Many real-world applications can be modelled as complex networks, and such networks include the Internet, epidemic disease networks, transport networks, power grids, protein-folding structures and others. Network integrity and robustness are important to ensure that crucial networks are protected and undesired harmful networks can be dismantled. Network structure and integrity can be controlled by a set of key nodes, and to find the optimal combination of nodes in a network to ensure network structure and integrity can be an NP-complete problem. Despite extensive studies, existing methods have many limitations and there are still many unresolved problems. This paper presents a probabilistic approach based on neighborhood information and node importance, namely, neighborhood information-based probabilistic algorithm (NIPA). We also define a new centrality-based importance measure (IM), which combines the contribution ratios of the neighbor nodes of each target node and two-hop node information. Our proposed NIPA has been tested for different network benchmarks and compared with three other methods: optimal attack strategy (OAS), high betweenness first (HBF) and high degree first (HDF). Experiments suggest that the proposed NIPA is most effective among all four methods. In general, NIPA can identify the most crucial node combination with higher effectiveness, and the set of optimal key nodes found by our proposed NIPA is much smaller than that by heuristic centrality prediction. In addition, many previously neglected weakly connected nodes are identified, which become a crucial part of the newly identified optimal nodes. Thus, revised strategies for protection are recommended to ensure the safeguard of network integrity. Further key issues and future research topics are also discussed.
* 25 pages, 13 figures, 2 tables
Influence of Initialization on the Performance of Metaheuristic Optimizers
Mar 08, 2020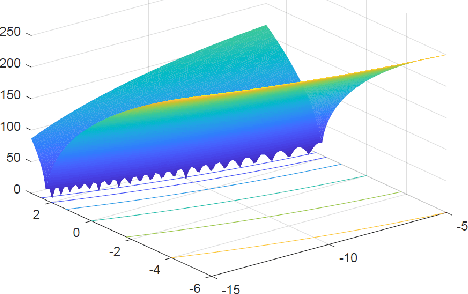

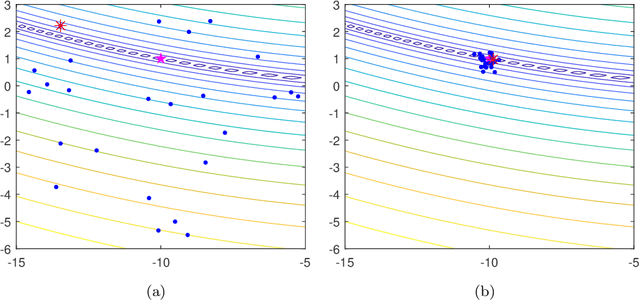
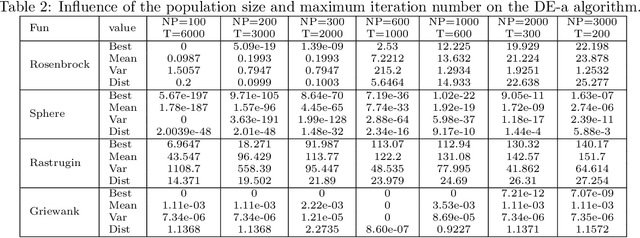
All metaheuristic optimization algorithms require some initialization, and the initialization for such optimizers is usually carried out randomly. However, initialization can have some significant influence on the performance of such algorithms. This paper presents a systematic comparison of 22 different initialization methods on the convergence and accuracy of five optimizers: differential evolution (DE), particle swarm optimization (PSO), cuckoo search (CS), artificial bee colony (ABC) algorithm and genetic algorithm (GA). We have used 19 different test functions with different properties and modalities to compare the possible effects of initialization, population sizes and the numbers of iterations. Rigorous statistical ranking tests indicate that 43.37\% of the functions using the DE algorithm show significant differences for different initialization methods, while 73.68\% of the functions using both PSO and CS algorithms are significantly affected by different initialization methods. The simulations show that DE is less sensitive to initialization, while both PSO and CS are more sensitive to initialization. In addition, under the condition of the same maximum number of function evaluations (FEs), the population size can also have a strong effect. Particle swarm optimization usually requires a larger population, while the cuckoo search needs only a small population size. Differential evolution depends more heavily on the number of iterations, a relatively small population with more iterations can lead to better results. Furthermore, ABC is more sensitive to initialization, while such initialization has little effect on GA. Some probability distributions such as the beta distribution, exponential distribution and Rayleigh distribution can usually lead to better performance. The implications of this study and further research topics are also discussed in detail.
* 39 pages, 10 figures, 20 tables