 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGPT and post-test probability
Dec 04, 2023Reinforcement learning-based large language models, such as ChatGPT, are believed to have potential to aid human experts in many domains, including healthcare. There is, however, little work on ChatGPT's ability to perform a key task in healthcare: formal, probabilistic medical diagnostic reasoning. This type of reasoning is used, for example, to update a pre-test probability to a post-test probability. In this work, we probe ChatGPT's ability to perform this task. In particular, we ask ChatGPT to give examples of how to use Bayes rule for medical diagnosis. Our prompts range from queries that use terminology from pure probability (e.g., requests for a "posterior probability") to queries that use terminology from the medical diagnosis literature (e.g., requests for a "post-test probability"). We show how the introduction of medical variable names leads to an increase in the number of errors that ChatGPT makes. Given our results, we also show how one can use prompt engineering to facilitate ChatGPT's partial avoidance of these errors. We discuss our results in light of recent commentaries on sensitivity and specificity. We also discuss how our results might inform new research directions for large language models.
Inference for relative sparsity
Jun 25, 2023



In healthcare, there is much interest in estimating policies, or mappings from covariates to treatment decisions. Recently, there is also interest in constraining these estimated policies to the standard of care, which generated the observed data. A relative sparsity penalty was proposed to derive policies that have sparse, explainable differences from the standard of care, facilitating justification of the new policy. However, the developers of this penalty only considered estimation, not inference. Here, we develop inference for the relative sparsity objective function, because characterizing uncertainty is crucial to applications in medicine. Further, in the relative sparsity work, the authors only considered the single-stage decision case; here, we consider the more general, multi-stage case. Inference is difficult, because the relative sparsity objective depends on the unpenalized value function, which is unstable and has infinite estimands in the binary action case. Further, one must deal with a non-differentiable penalty. To tackle these issues, we nest a weighted Trust Region Policy Optimization function within a relative sparsity objective, implement an adaptive relative sparsity penalty, and propose a sample-splitting framework for post-selection inference. We study the asymptotic behavior of our proposed approaches, perform extensive simulations, and analyze a real, electronic health record dataset.
Relative Sparsity for Medical Decision Problems
Nov 29, 2022Existing statistical methods can be used to estimate a policy, or a mapping from covariates to decisions, which can then instruct decision makers. There is great interest in using such data-driven policies in healthcare. In healthcare, however, it is often important to explain to the healthcare provider, and to the patient, how a new policy differs from the current standard of care. This end is facilitated if one can pinpoint the aspects (i.e., parameters) of the policy that change most when moving from the standard of care to the new, suggested policy. To this end, we adapt ideas from Trust Region Policy Optimization. In our work, however, unlike in Trust Region Policy Optimization, the difference between the suggested policy and standard of care is required to be sparse, aiding with interpretability. In particular, we trade off between maximizing expected reward and minimizing the $L_1$ norm divergence between the parameters of the two policies. This yields "relative sparsity," where, as a function of a tuning parameter, $\lambda$, we can approximately control the number of parameters in our suggested policy that differ from their counterparts in the standard of care. We develop our methodology for the observational data setting. We propose a problem-specific criterion for selecting $\lambda$, perform simulations, and illustrate our method with a real, observational healthcare dataset, deriving a policy that is easy to explain in the context of the current standard of care. Our work promotes the adoption of data-driven decision aids, which have great potential to improve health outcomes.
Predicting Acute Kidney Injury at Hospital Re-entry Using High-dimensional Electronic Health Record Data
Aug 13, 2018
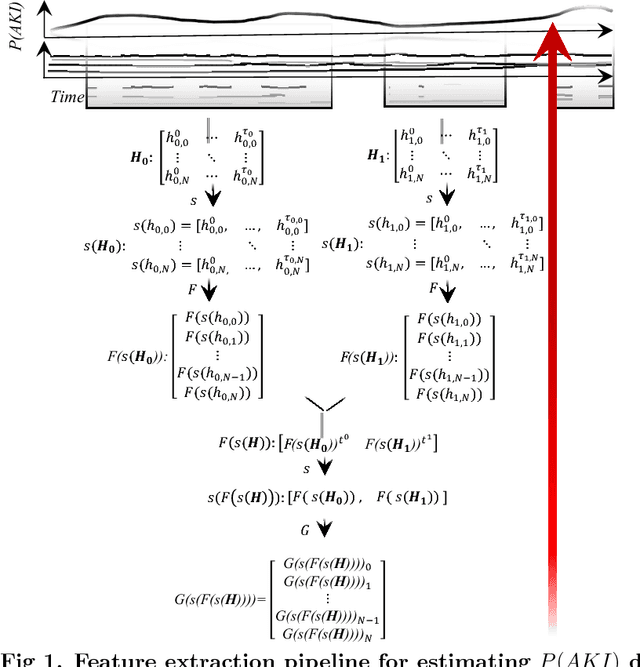
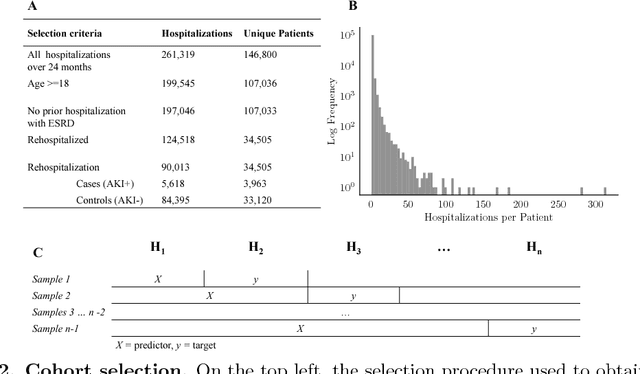
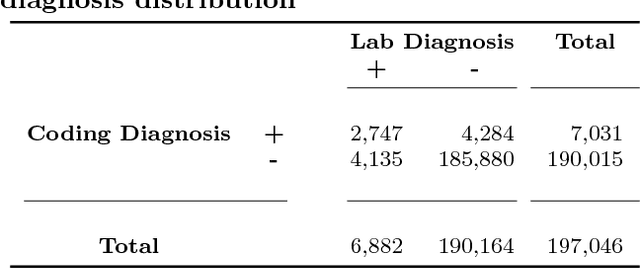
Acute Kidney Injury (AKI), a sudden decline in kidney function, is associated with increased mortality, morbidity, length of stay, and hospital cost. Since AKI is sometimes preventable, there is great interest in prediction. Most existing studies consider all patients and therefore restrict to features available in the first hours of hospitalization. Here, the focus is instead on rehospitalized patients, a cohort in which rich longitudinal features from prior hospitalizations can be analyzed. Our objective is to provide a risk score directly at hospital re-entry. Gradient boosting, penalized logistic regression (with and without stability selection), and a recurrent neural network are trained on two years of adult inpatient EHR data (3,387 attributes for 34,505 patients who generated 90,013 training samples with 5,618 cases and 84,395 controls). Predictions are internally evaluated with 50 iterations of 5-fold grouped cross-validation with special emphasis on calibration, an analysis of which is performed at the patient as well as hospitalization level. Error is assessed with respect to diagnosis, race, age, gender, AKI identification method, and hospital utilization. In an additional experiment, the regularization penalty is severely increased to induce parsimony and interpretability. Predictors identified for rehospitalized patients are also reported with a special analysis of medications that might be modifiable risk factors. Insights from this study might be used to construct a predictive tool for AKI in rehospitalized patients. An accurate estimate of AKI risk at hospital entry might serve as a prior for an admitting provider or another predictive algorithm.
Revealing patterns in HIV viral load data and classifying patients via a novel machine learning cluster summarization method
Apr 25, 2018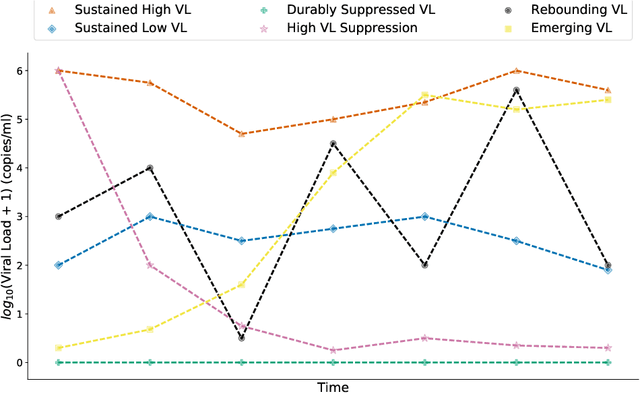
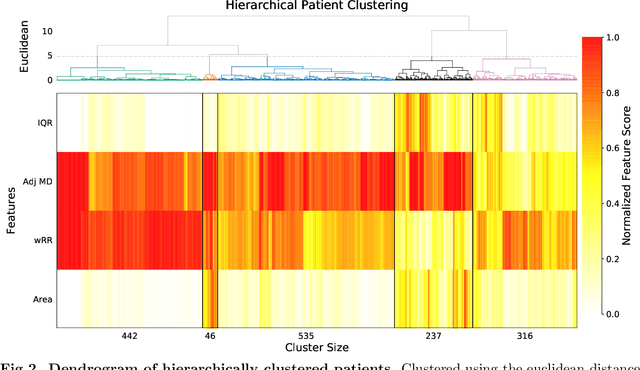

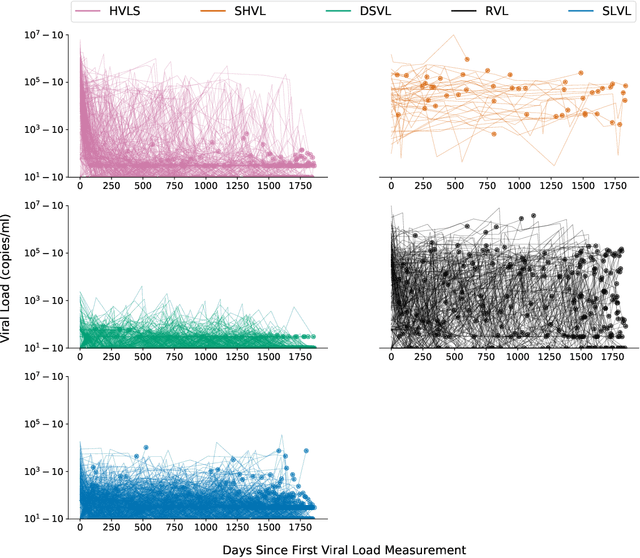
HIV RNA viral load (VL) is an important outcome variable in studies of HIV infected persons. There exists only a handful of methods which classify patients by viral load patterns. Most methods place limits on the use of viral load measurements, are often specific to a particular study design, and do not account for complex, temporal variation. To address this issue, we propose a set of four unambiguous computable characteristics (features) of time-varying HIV viral load patterns, along with a novel centroid-based classification algorithm, which we use to classify a population of 1,576 HIV positive clinic patients into one of five different viral load patterns (clusters) often found in the literature: durably suppressed viral load (DSVL), sustained low viral load (SLVL), sustained high viral load (SHVL), high viral load suppression (HVLS), and rebounding viral load (RVL). The centroid algorithm summarizes these clusters in terms of their centroids and radii. We show that this allows new viral load patterns to be assigned pattern membership based on the distance from the centroid relative to its radius, which we term radial normalization classification. This method has the benefit of providing an objective and quantitative method to assign viral load pattern membership with a concise and interpretable model that aids clinical decision making. This method also facilitates meta-analyses by providing computably distinct HIV categories. Finally we propose that this novel centroid algorithm could also be useful in the areas of cluster comparison for outcomes research and data reduction in machine learning.