 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Generative Models for Learning Stochastic Processes
Apr 21, 2023A framework to learn a multi-modal distribution is proposed, denoted as the Conditional Quantum Generative Adversarial Network (C-qGAN). The neural network structure is strictly within a quantum circuit and, as a consequence, is shown to represent a more efficient state preparation procedure than current methods. This methodology has the potential to speed-up algorithms, such as Monte Carlo analysis. In particular, after demonstrating the effectiveness of the network in the learning task, the technique is applied to price Asian option derivatives, providing the foundation for further research on other path-dependent options.
An Advantage Using Feature Selection with a Quantum Annealer
Nov 21, 2022Feature selection is a technique in statistical prediction modeling that identifies features in a record with a strong statistical connection to the target variable. Excluding features with a weak statistical connection to the target variable in training not only drops the dimension of the data, which decreases the time complexity of the algorithm, it also decreases noise within the data which assists in avoiding overfitting. In all, feature selection assists in training a robust statistical model that performs well and is stable. Given the lack of scalability in classical computation, current techniques only consider the predictive power of the feature and not redundancy between the features themselves. Recent advancements in feature selection that leverages quantum annealing (QA) gives a scalable technique that aims to maximize the predictive power of the features while minimizing redundancy. As a consequence, it is expected that this algorithm would assist in the bias/variance trade-off yielding better features for training a statistical model. This paper tests this intuition against classical methods by utilizing open-source data sets and evaluate the efficacy of each trained statistical model well-known prediction algorithms. The numerical results display an advantage utilizing the features selected from the algorithm that leveraged QA.
$α$QBoost: An Iteratively Weighted Adiabatic Trained Classifier
Oct 14, 2022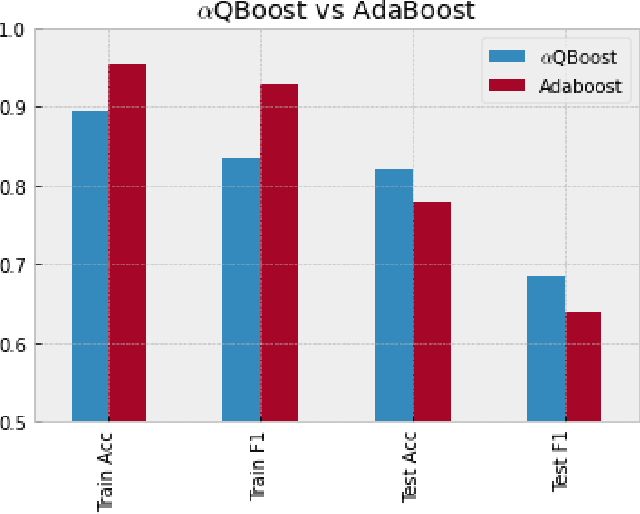
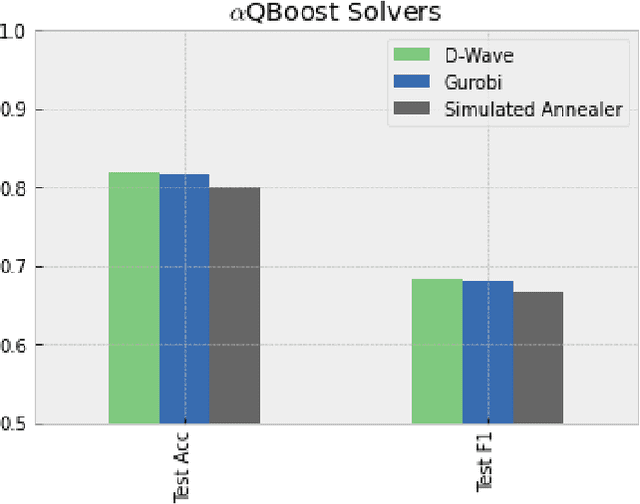
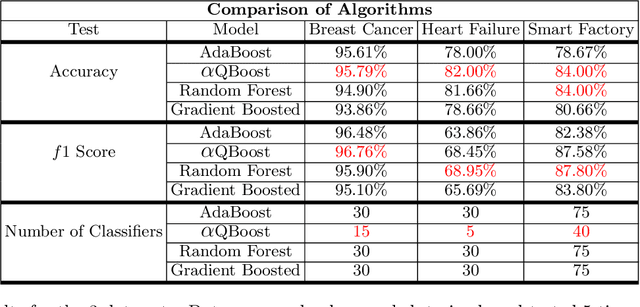
A new implementation of an adiabatically-trained ensemble model is derived that shows significant improvements over classical methods. In particular, empirical results of this new algorithm show that it offers not just higher performance, but also more stability with less classifiers, an attribute that is critically important in areas like explainability and speed-of-inference. In all, the empirical analysis displays that the algorithm can provide an increase in performance on unseen data by strengthening stability of the statistical model through further minimizing and balancing variance and bias, while decreasing the time to convergence over its predecessors.