 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Hype: Assessing the Performance, Trustworthiness, and Clinical Suitability of GPT3.5
Jun 28, 2023
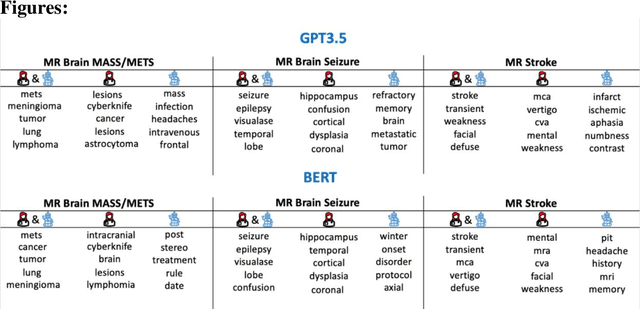
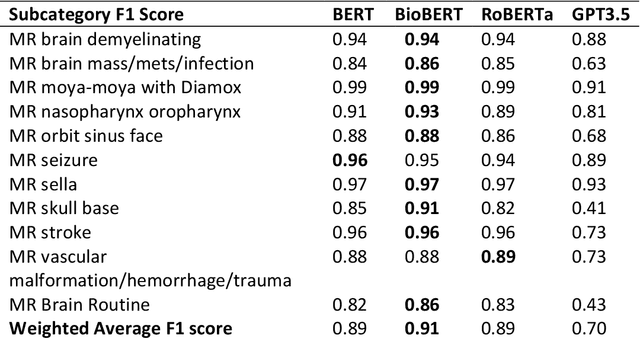
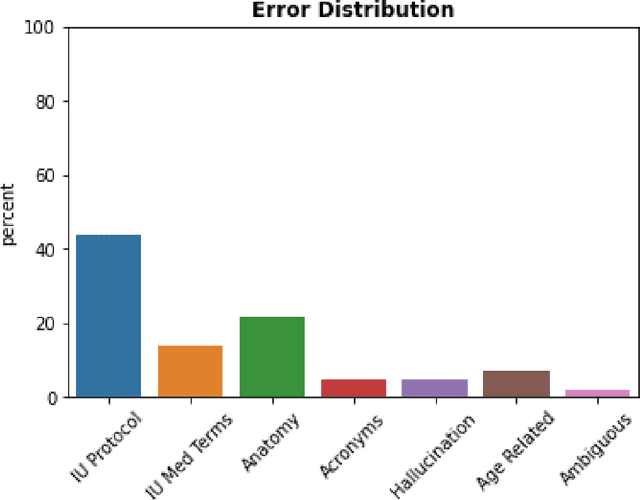
The use of large language models (LLMs) in healthcare is gaining popularity, but their practicality and safety in clinical settings have not been thoroughly assessed. In high-stakes environments like medical settings, trust and safety are critical issues for LLMs. To address these concerns, we present an approach to evaluate the performance and trustworthiness of a GPT3.5 model for medical image protocol assignment. We compare it with a fine-tuned BERT model and a radiologist. In addition, we have a radiologist review the GPT3.5 output to evaluate its decision-making process. Our evaluation dataset consists of 4,700 physician entries across 11 imaging protocol classes spanning the entire head. Our findings suggest that the GPT3.5 performance falls behind BERT and a radiologist. However, GPT3.5 outperforms BERT in its ability to explain its decision, detect relevant word indicators, and model calibration. Furthermore, by analyzing the explanations of GPT3.5 for misclassifications, we reveal systematic errors that need to be resolved to enhance its safety and suitability for clinical use.