 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetworkFF: Unified Layer Optimization in Forward-Only Neural Networks
Dec 22, 2025The Forward-Forward algorithm eliminates backpropagation's memory constraints and biological implausibility through dual forward passes with positive and negative data. However, conventional implementations suffer from critical inter-layer isolation, where layers optimize goodness functions independently without leveraging collective learning dynamics. This isolation constrains representational coordination and limits convergence efficiency in deeper architectures. This paper introduces Collaborative Forward-Forward (CFF) learning, extending the original algorithm through inter-layer cooperation mechanisms that preserve forward-only computation while enabling global context integration. Our framework implements two collaborative paradigms: Fixed CFF (F-CFF) with constant inter-layer coupling and Adaptive CFF (A-CFF) with learnable collaboration parameters that evolve during training. The collaborative goodness function incorporates weighted contributions from all layers, enabling coordinated feature learning while maintaining memory efficiency and biological plausibility. Comprehensive evaluation on MNIST and Fashion-MNIST demonstrates significant performance improvements over baseline Forward-Forward implementations. These findings establish inter-layer collaboration as a fundamental enhancement to Forward-Forward learning, with immediate applicability to neuromorphic computing architectures and energy-constrained AI systems.
Resource-efficient medical image classification for edge devices
Dec 19, 2025Medical image classification is a critical task in healthcare, enabling accurate and timely diagnosis. However, deploying deep learning models on resource-constrained edge devices presents significant challenges due to computational and memory limitations. This research investigates a resource-efficient approach to medical image classification by employing model quantization techniques. Quantization reduces the precision of model parameters and activations, significantly lowering computational overhead and memory requirements without sacrificing classification accuracy. The study focuses on the optimization of quantization-aware training (QAT) and post-training quantization (PTQ) methods tailored for edge devices, analyzing their impact on model performance across medical imaging datasets. Experimental results demonstrate that quantized models achieve substantial reductions in model size and inference latency, enabling real-time processing on edge hardware while maintaining clinically acceptable diagnostic accuracy. This work provides a practical pathway for deploying AI-driven medical diagnostics in remote and resource-limited settings, enhancing the accessibility and scalability of healthcare technologies.
* Conference paper published in ICAMIDA 2025 (IEEE)
Quantized and Interpretable Learning Scheme for Deep Neural Networks in Classification Task
Dec 05, 2024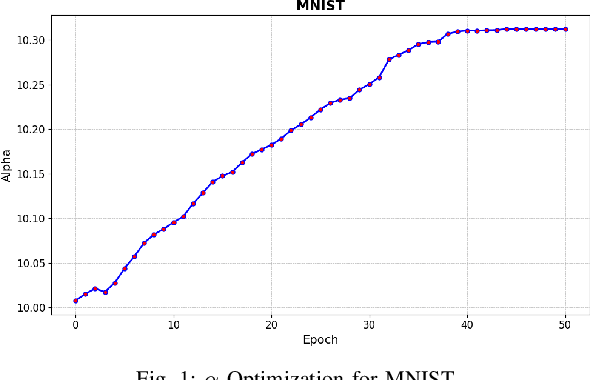
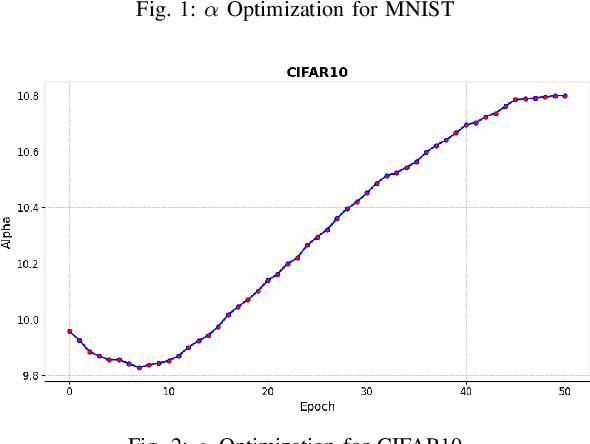
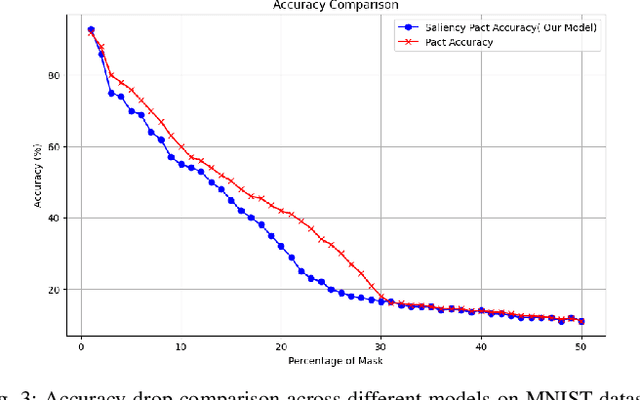
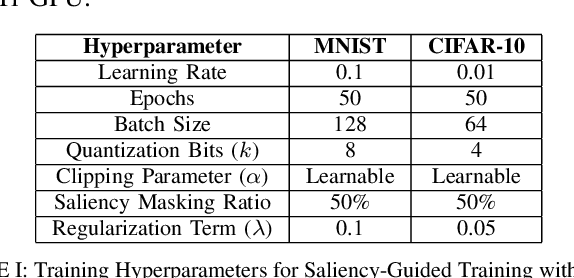
Deep learning techniques have proven highly effective in image classification, but their deployment in resourceconstrained environments remains challenging due to high computational demands. Furthermore, their interpretability is of high importance which demands even more available resources. In this work, we introduce an approach that combines saliency-guided training with quantization techniques to create an interpretable and resource-efficient model without compromising accuracy. We utilize Parameterized Clipping Activation (PACT) to perform quantization-aware training, specifically targeting activations and weights to optimize precision while minimizing resource usage. Concurrently, saliency-guided training is employed to enhance interpretability by iteratively masking features with low gradient values, leading to more focused and meaningful saliency maps. This training procedure helps in mitigating noisy gradients and yields models that provide clearer, more interpretable insights into their decision-making processes. To evaluate the impact of our approach, we conduct experiments using famous Convolutional Neural Networks (CNN) architecture on the MNIST and CIFAR-10 benchmark datasets as two popular datasets. We compare the saliency maps generated by standard and quantized models to assess the influence of quantization on both interpretability and classification accuracy. Our results demonstrate that the combined use of saliency-guided training and PACT-based quantization not only maintains classification performance but also produces models that are significantly more efficient and interpretable, making them suitable for deployment in resource-limited settings.
Saliency Assisted Quantization for Neural Networks
Nov 07, 2024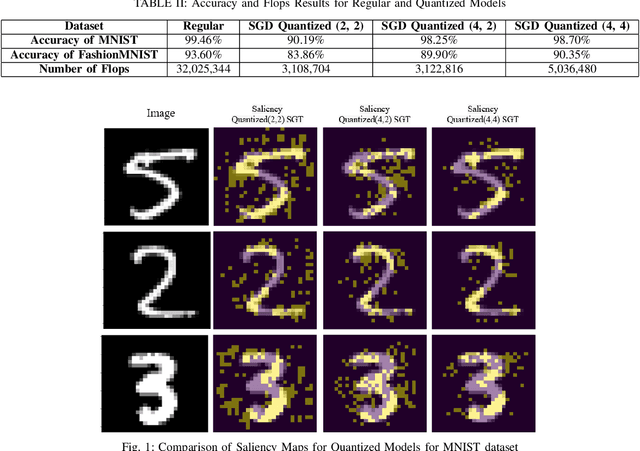
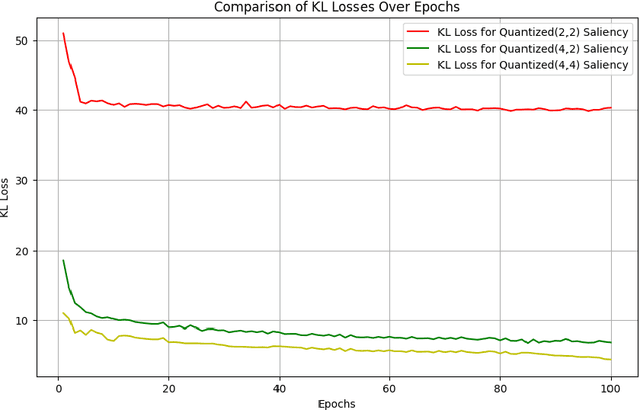
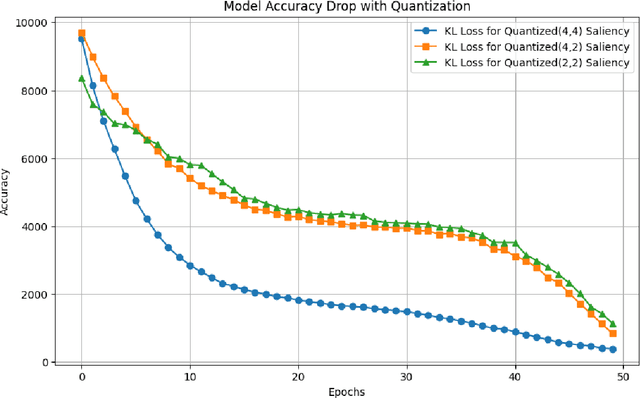
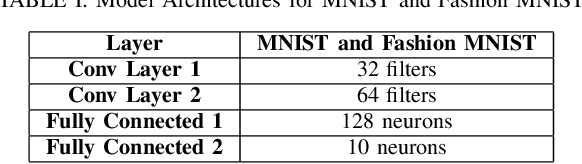
Deep learning methods have established a significant place in image classification. While prior research has focused on enhancing final outcomes, the opaque nature of the decision-making process in these models remains a concern for experts. Additionally, the deployment of these methods can be problematic in resource-limited environments. This paper tackles the inherent black-box nature of these models by providing real-time explanations during the training phase, compelling the model to concentrate on the most distinctive and crucial aspects of the input. Furthermore, we employ established quantization techniques to address resource constraints. To assess the effectiveness of our approach, we explore how quantization influences the interpretability and accuracy of Convolutional Neural Networks through a comparative analysis of saliency maps from standard and quantized models. Quantization is implemented during the training phase using the Parameterized Clipping Activation method, with a focus on the MNIST and FashionMNIST benchmark datasets. We evaluated three bit-width configurations (2-bit, 4-bit, and mixed 4/2-bit) to explore the trade-off between efficiency and interpretability, with each configuration designed to highlight varying impacts on saliency map clarity and model accuracy. The results indicate that while quantization is crucial for implementing models on resource-limited devices, it necessitates a trade-off between accuracy and interpretability. Lower bit-widths result in more pronounced reductions in both metrics, highlighting the necessity of meticulous quantization parameter selection in applications where model transparency is paramount. The study underscores the importance of achieving a balance between efficiency and interpretability in the deployment of neural networks.