 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource-efficient medical image classification for edge devices
Dec 19, 2025Medical image classification is a critical task in healthcare, enabling accurate and timely diagnosis. However, deploying deep learning models on resource-constrained edge devices presents significant challenges due to computational and memory limitations. This research investigates a resource-efficient approach to medical image classification by employing model quantization techniques. Quantization reduces the precision of model parameters and activations, significantly lowering computational overhead and memory requirements without sacrificing classification accuracy. The study focuses on the optimization of quantization-aware training (QAT) and post-training quantization (PTQ) methods tailored for edge devices, analyzing their impact on model performance across medical imaging datasets. Experimental results demonstrate that quantized models achieve substantial reductions in model size and inference latency, enabling real-time processing on edge hardware while maintaining clinically acceptable diagnostic accuracy. This work provides a practical pathway for deploying AI-driven medical diagnostics in remote and resource-limited settings, enhancing the accessibility and scalability of healthcare technologies.
* Conference paper published in ICAMIDA 2025 (IEEE)
Quantized and Interpretable Learning Scheme for Deep Neural Networks in Classification Task
Dec 05, 2024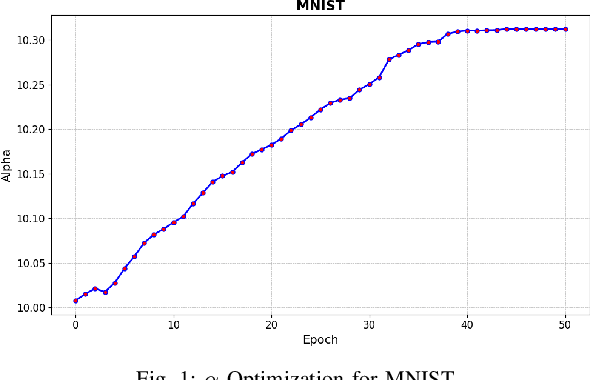
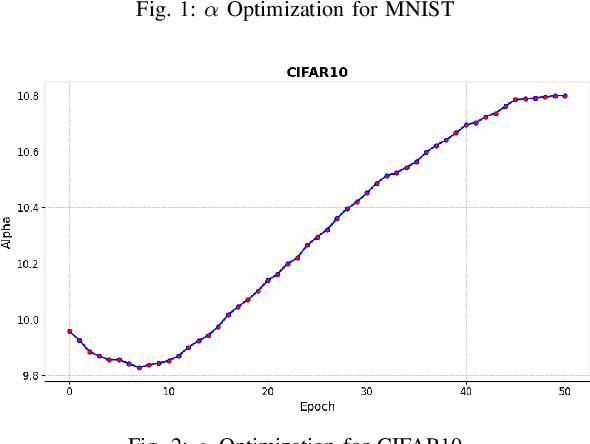
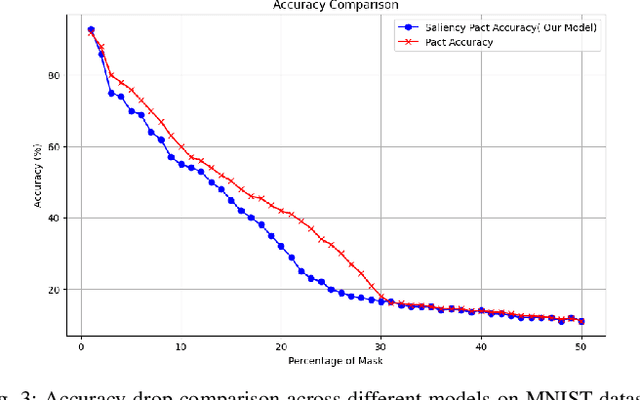
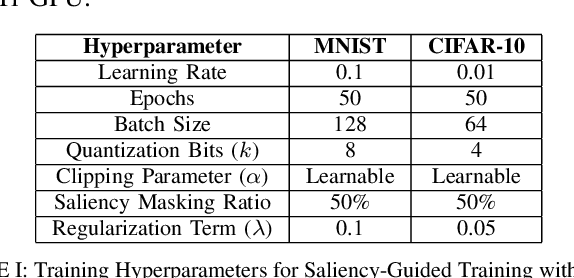
Deep learning techniques have proven highly effective in image classification, but their deployment in resourceconstrained environments remains challenging due to high computational demands. Furthermore, their interpretability is of high importance which demands even more available resources. In this work, we introduce an approach that combines saliency-guided training with quantization techniques to create an interpretable and resource-efficient model without compromising accuracy. We utilize Parameterized Clipping Activation (PACT) to perform quantization-aware training, specifically targeting activations and weights to optimize precision while minimizing resource usage. Concurrently, saliency-guided training is employed to enhance interpretability by iteratively masking features with low gradient values, leading to more focused and meaningful saliency maps. This training procedure helps in mitigating noisy gradients and yields models that provide clearer, more interpretable insights into their decision-making processes. To evaluate the impact of our approach, we conduct experiments using famous Convolutional Neural Networks (CNN) architecture on the MNIST and CIFAR-10 benchmark datasets as two popular datasets. We compare the saliency maps generated by standard and quantized models to assess the influence of quantization on both interpretability and classification accuracy. Our results demonstrate that the combined use of saliency-guided training and PACT-based quantization not only maintains classification performance but also produces models that are significantly more efficient and interpretable, making them suitable for deployment in resource-limited settings.