 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Privacy-aware LLM in Healthcare: Threat Model, Privacy Techniques, Challenges and Recommendations
Jan 15, 2026Large Language Models (LLMs) are increasingly adopted in healthcare to support clinical decision-making, summarize electronic health records (EHRs), and enhance patient care. However, this integration introduces significant privacy and security challenges, driven by the sensitivity of clinical data and the high-stakes nature of medical workflows. These risks become even more pronounced across heterogeneous deployment environments, ranging from small on-premise hospital systems to regional health networks, each with unique resource limitations and regulatory demands. This Systematization of Knowledge (SoK) examines the evolving threat landscape across the three core LLM phases: Data preprocessing, Fine-tuning, and Inference within realistic healthcare settings. We present a detailed threat model that characterizes adversaries, capabilities, and attack surfaces at each phase, and we systematize how existing privacy-preserving techniques (PPTs) attempt to mitigate these vulnerabilities. While existing defenses show promise, our analysis identifies persistent limitations in securing sensitive clinical data across diverse operational tiers. We conclude with phase-aware recommendations and future research directions aimed at strengthening privacy guarantees for LLMs in regulated environments. This work provides a foundation for understanding the intersection of LLMs, threats, and privacy in healthcare, offering a roadmap toward more robust and clinically trustworthy AI systems.
Integrating Linguistics and AI: Morphological Analysis and Corpus development of Endangered Toto Language of West Bengal
Oct 26, 2025Preserving linguistic diversity is necessary as every language offers a distinct perspective on the world. There have been numerous global initiatives to preserve endangered languages through documentation. This paper is a part of a project which aims to develop a trilingual (Toto-Bangla-English) language learning application to digitally archive and promote the endangered Toto language of West Bengal, India. This application, designed for both native Toto speakers and non-native learners, aims to revitalize the language by ensuring accessibility and usability through Unicode script integration and a structured language corpus. The research includes detailed linguistic documentation collected via fieldwork, followed by the creation of a morpheme-tagged, trilingual corpus used to train a Small Language Model (SLM) and a Transformer-based translation engine. The analysis covers inflectional morphology such as person-number-gender agreement, tense-aspect-mood distinctions, and case marking, alongside derivational strategies that reflect word-class changes. Script standardization and digital literacy tools were also developed to enhance script usage. The study offers a sustainable model for preserving endangered languages by incorporating traditional linguistic methodology with AI. This bridge between linguistic research with technological innovation highlights the value of interdisciplinary collaboration for community-based language revitalization.
Blockchain Signatures to Ensure Information Integrity and Non-Repudiation in the Digital Era: A comprehensive study
Oct 26, 2025Blockchain systems rely on decentralized ledgers and strong security guarantees. A key requirement is non-repudiation, which prevents denial of transaction authorship and supports integrity of recorded data. This work surveys digital signature schemes used in blockchain platforms and analyzes how they deliver non-repudiation and contribute to overall system security. We examine representative scheme families and their cryptographic foundations, security assumptions, and properties relevant to deployment, including unforgeability, resistance to malleability, support for aggregation and multisignature or threshold settings, key and signature sizes, and verification cost. Using these criteria, we compare the suitability of different designs for consensus protocols, smart contract constraints, and resource limits. We highlight practical tradeoffs that affect throughput, storage, scalability, and attack surfaces, and summarize benefits and limitations of each scheme in blockchain contexts. The study underscores that carefully chosen digital signatures are central to achieving non-repudiation and preserving information integrity, and it outlines implementation considerations and open directions such as interoperability and post-quantum readiness.
A Critical Study on Tea Leaf Disease Detection using Deep Learning Techniques
Oct 26, 2025The proposed solution is Deep Learning Technique that will be able classify three types of tea leaves diseases from which two diseases are caused by the pests and one due to pathogens (infectious organisms) and environmental conditions and also show the area damaged by a disease in leaves. Namely Red Rust, Helopeltis and Red spider mite respectively. In this paper we have evaluated two models namely SSD MobileNet V2 and Faster R-CNN ResNet50 V1 for the object detection. The SSD MobileNet V2 gave precision of 0.209 for IOU range of 0.50:0.95 with recall of 0.02 on IOU 0.50:0.95 and final mAP of 20.9%. While Faster R-CNN ResNet50 V1 has precision of 0.252 on IOU range of 0.50:0.95 and recall of 0.044 on IOU of 0.50:0.95 with a mAP of 25%, which is better than SSD. Also used Mask R-CNN for Object Instance Segmentation where we have implemented our custom method to calculate the damaged diseased portion of leaves. Keywords: Tea Leaf Disease, Deep Learning, Red Rust, Helopeltis and Red Spider Mite, SSD MobileNet V2, Faster R-CNN ResNet50 V1 and Mask RCNN.
DEK-Forecaster: A Novel Deep Learning Model Integrated with EMD-KNN for Traffic Prediction
Jun 06, 2023
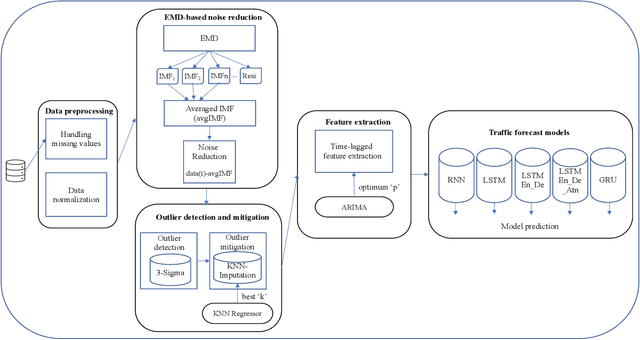
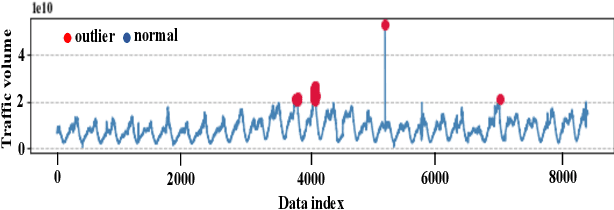
Internet traffic volume estimation has a significant impact on the business policies of the ISP (Internet Service Provider) industry and business successions. Forecasting the internet traffic demand helps to shed light on the future traffic trend, which is often helpful for ISPs decision-making in network planning activities and investments. Besides, the capability to understand future trend contributes to managing regular and long-term operations. This study aims to predict the network traffic volume demand using deep sequence methods that incorporate Empirical Mode Decomposition (EMD) based noise reduction, Empirical rule based outlier detection, and $K$-Nearest Neighbour (KNN) based outlier mitigation. In contrast to the former studies, the proposed model does not rely on a particular EMD decomposed component called Intrinsic Mode Function (IMF) for signal denoising. In our proposed traffic prediction model, we used an average of all IMFs components for signal denoising. Moreover, the abnormal data points are replaced by $K$ nearest data points average, and the value for $K$ has been optimized based on the KNN regressor prediction error measured in Root Mean Squared Error (RMSE). Finally, we selected the best time-lagged feature subset for our prediction model based on AutoRegressive Integrated Moving Average (ARIMA) and Akaike Information Criterion (AIC) value. Our experiments are conducted on real-world internet traffic datasets from industry, and the proposed method is compared with various traditional deep sequence baseline models. Our results show that the proposed EMD-KNN integrated prediction models outperform comparative models.
Transfer Learning Based Efficient Traffic Prediction with Limited Training Data
May 09, 2022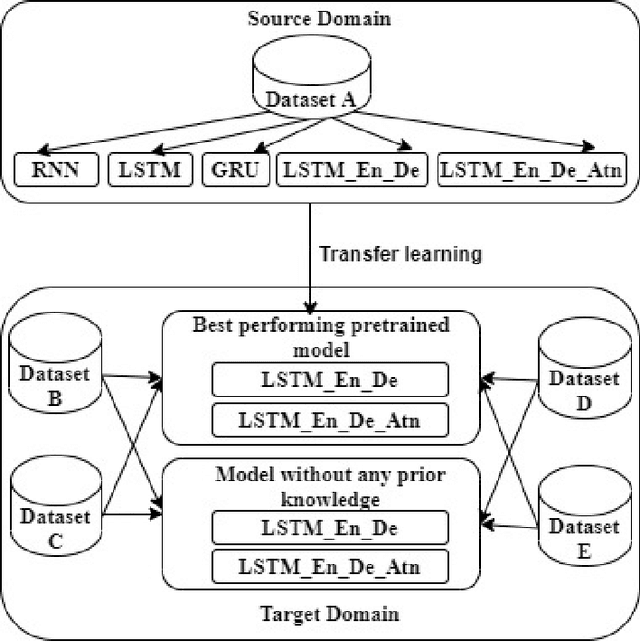
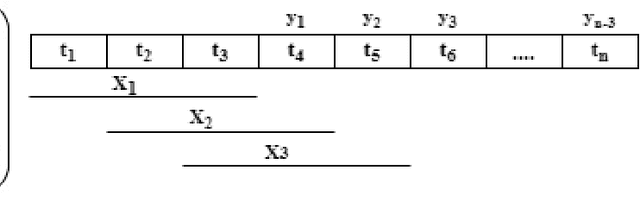
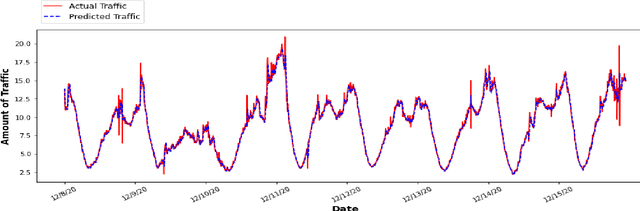
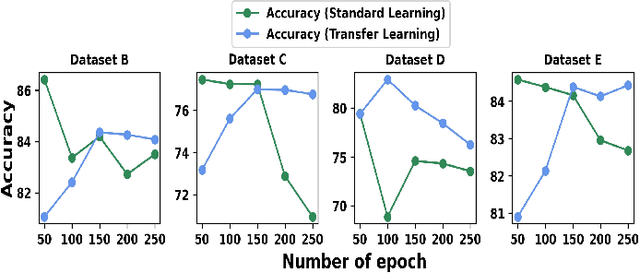
Efficient prediction of internet traffic is an essential part of Self Organizing Network (SON) for ensuring proactive management. There are many existing solutions for internet traffic prediction with higher accuracy using deep learning. But designing individual predictive models for each service provider in the network is challenging due to data heterogeneity, scarcity, and abnormality. Moreover, the performance of the deep sequence model in network traffic prediction with limited training data has not been studied extensively in the current works. In this paper, we investigated and evaluated the performance of the deep transfer learning technique in traffic prediction with inadequate historical data leveraging the knowledge of our pre-trained model. First, we used a comparatively larger real-world traffic dataset for source domain prediction based on five different deep sequence models: Recurrent Neural Network (RNN), Long Short-Term Memory (LSTM), LSTM Encoder-Decoder (LSTM_En_De), LSTM_En_De with Attention layer (LSTM_En_De_Atn), and Gated Recurrent Unit (GRU). Then, two best-performing models, LSTM_En_De and LSTM_En_De_Atn, from the source domain with an accuracy of 96.06% and 96.05% are considered for the target domain prediction. Finally, four smaller traffic datasets collected for four particular sources and destination pairs are used in the target domain to compare the performance of the standard learning and transfer learning in terms of accuracy and execution time. According to our experimental result, transfer learning helps to reduce the execution time for most cases, while the model's accuracy is improved in transfer learning with a larger training session.
Wavelet-Based Hybrid Machine Learning Model for Out-of-distribution Internet Traffic Prediction
May 09, 2022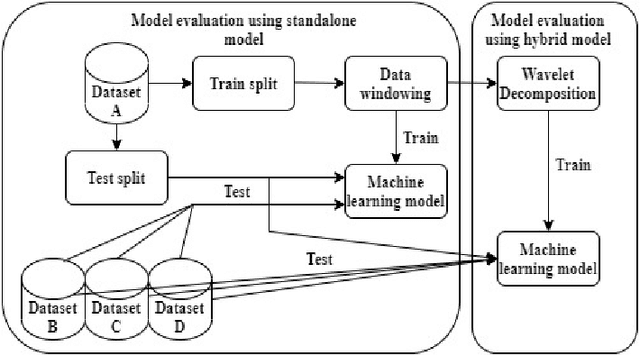
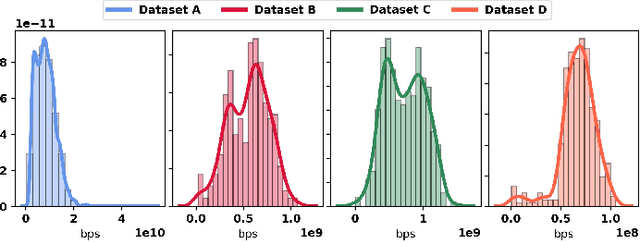
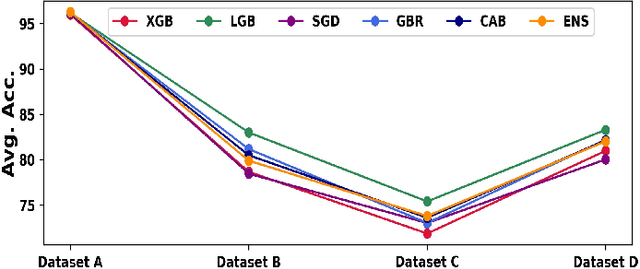

Efficient prediction of internet traffic is essential for ensuring proactive management of computer networks. Nowadays, machine learning approaches show promising performance in modeling real-world complex traffic. However, most existing works assumed that model training and evaluation data came from identical distribution. But in practice, there is a high probability that the model will deal with data from a slightly or entirely unknown distribution in the deployment phase. This paper investigated and evaluated machine learning performances using eXtreme Gradient Boosting, Light Gradient Boosting Machine, Stochastic Gradient Descent, Gradient Boosting Regressor, CatBoost Regressor, and their stacked ensemble model using data from both identical and out-of distribution. Also, we proposed a hybrid machine learning model integrating wavelet decomposition for improving out-of-distribution prediction as standalone models were unable to generalize very well. Our experimental results show the best performance of the standalone ensemble model with an accuracy of 96.4%, while the hybrid ensemble model improved it by 1% for in-distribution data. But its performance dropped significantly when tested with three different datasets having a distribution shift than the training set. However, our proposed hybrid model considerably reduces the performance gap between identical and out-of-distribution evaluation compared with the standalone model, indicating the decomposition technique's effectiveness in the case of out-of-distribution generalization.
Deep Sequence Modeling for Anomalous ISP Traffic Prediction
May 03, 2022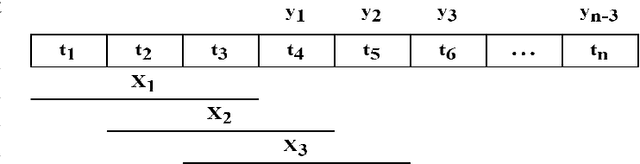
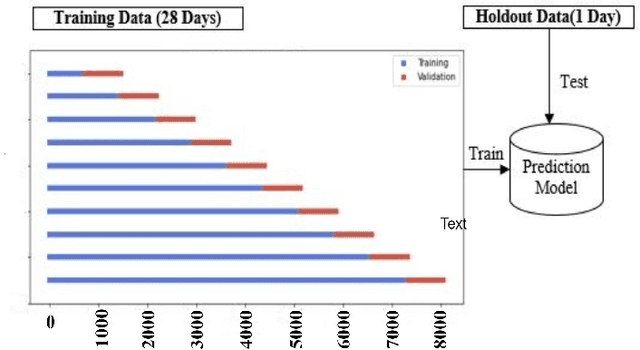
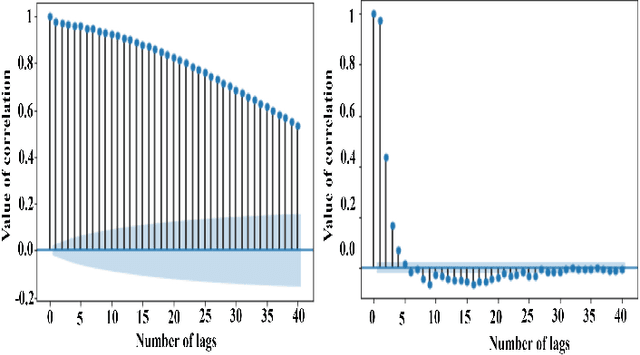
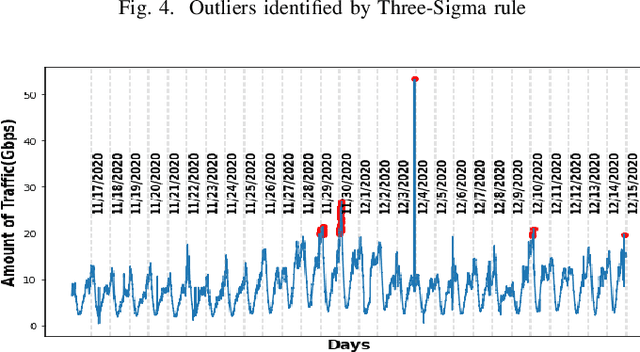
Internet traffic in the real world is susceptible to various external and internal factors which may abruptly change the normal traffic flow. Those unexpected changes are considered outliers in traffic. However, deep sequence models have been used to predict complex IP traffic, but their comparative performance for anomalous traffic has not been studied extensively. In this paper, we investigated and evaluated the performance of different deep sequence models for anomalous traffic prediction. Several deep sequences models were implemented to predict real traffic without and with outliers and show the significance of outlier detection in real-world traffic prediction. First, two different outlier detection techniques, such as the Three-Sigma rule and Isolation Forest, were applied to identify the anomaly. Second, we adjusted those abnormal data points using the Backward Filling technique before training the model. Finally, the performance of different models was compared for abnormal and adjusted traffic. LSTM_Encoder_Decoder (LSTM_En_De) is the best prediction model in our experiment, reducing the deviation between actual and predicted traffic by more than 11\% after adjusting the outliers. All other models, including Recurrent Neural Network (RNN), Long Short-Term Memory (LSTM), LSTM_En_De with Attention layer (LSTM_En_De_Atn), Gated Recurrent Unit (GRU), show better prediction after replacing the outliers and decreasing prediction error by more than 29%, 24%, 19%, and 10% respectively. Our experimental results indicate that the outliers in the data can significantly impact the quality of the prediction. Thus, outlier detection and mitigation assist the deep sequence model in learning the general trend and making better predictions.
An Empirical Study on Internet Traffic Prediction Using Statistical Rolling Model
May 03, 2022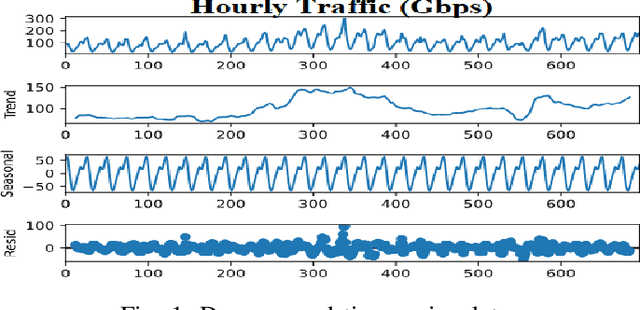
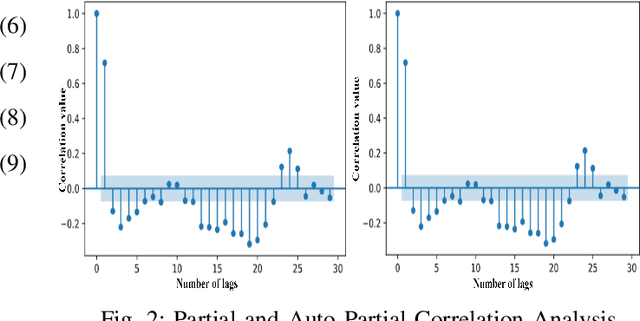
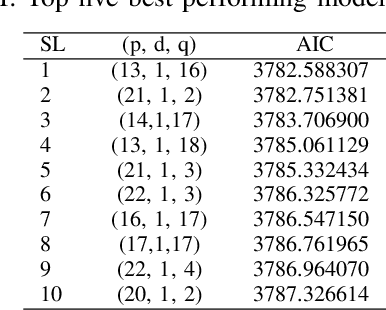
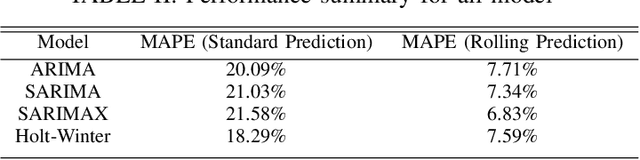
Real-world IP network traffic is susceptible to external and internal factors such as new internet service integration, traffic migration, internet application, etc. Due to these factors, the actual internet traffic is non-linear and challenging to analyze using a statistical model for future prediction. In this paper, we investigated and evaluated the performance of different statistical prediction models for real IP network traffic; and showed a significant improvement in prediction using the rolling prediction technique. Initially, a set of best hyper-parameters for the corresponding prediction model is identified by analyzing the traffic characteristics and implementing a grid search algorithm based on the minimum Akaike Information Criterion (AIC). Then, we performed a comparative performance analysis among AutoRegressive Integrated Moving Average (ARIMA), Seasonal ARIMA (SARIMA), SARIMA with eXogenous factors (SARIMAX), and Holt-Winter for single-step prediction. The seasonality of our traffic has been explicitly modeled using SARIMA, which reduces the rolling prediction Mean Average Percentage Error (MAPE) by more than 4% compared to ARIMA (incapable of handling the seasonality). We further improved traffic prediction using SARIMAX to learn different exogenous factors extracted from the original traffic, which yielded the best rolling prediction results with a MAPE of 6.83%. Finally, we applied the exponential smoothing technique to handle the variability in traffic following the Holt-Winter model, which exhibited a better prediction than ARIMA (around 1.5% less MAPE). The rolling prediction technique reduced prediction error using real Internet Service Provider (ISP) traffic data by more than 50\% compared to the standard prediction method.
Towards an Ensemble Regressor Model for Anomalous ISP Traffic Prediction
May 03, 2022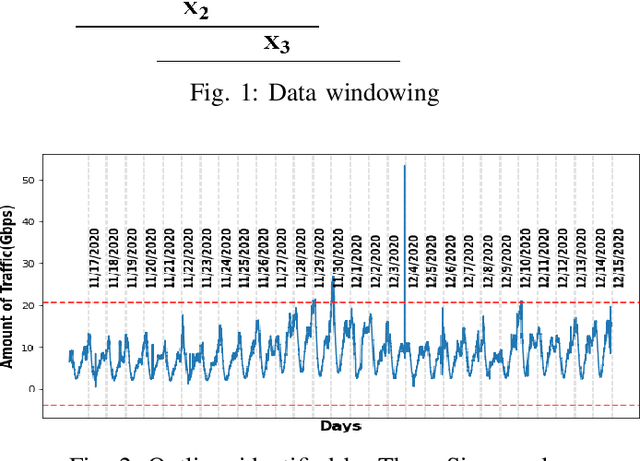
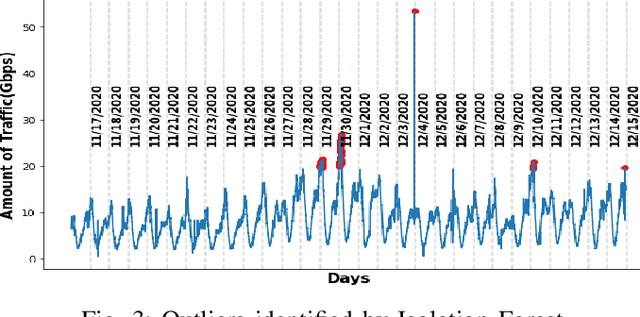
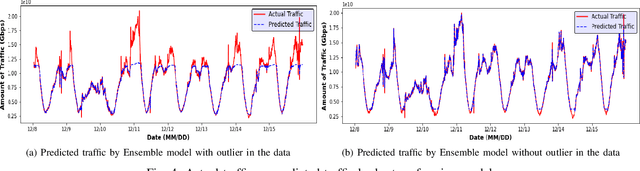
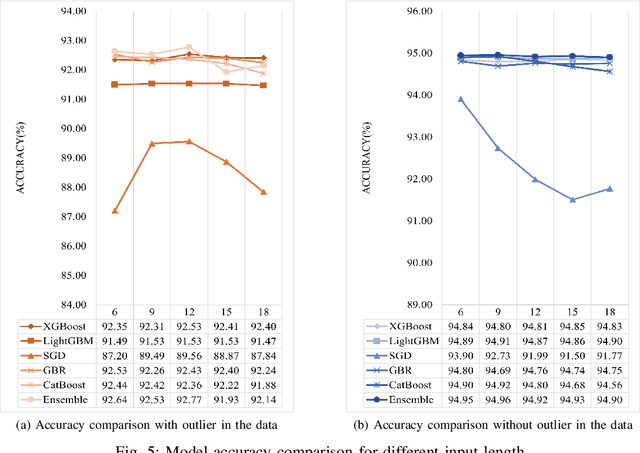
Prediction of network traffic behavior is significant for the effective management of modern telecommunication networks. However, the intuitive approach of predicting network traffic using administrative experience and market analysis data is inadequate for an efficient forecast framework. As a result, many different mathematical models have been studied to capture the general trend of the network traffic and predict accordingly. But the comprehensive performance analysis of varying regression models and their ensemble has not been studied before for analyzing real-world anomalous traffic. In this paper, several regression models such as Extra Gradient Boost (XGBoost), Light Gradient Boosting Machine (LightGBM), Stochastic Gradient Descent (SGD), Gradient Boosting Regressor (GBR), and CatBoost Regressor were analyzed to predict real traffic without and with outliers and show the significance of outlier detection in real-world traffic prediction. Also, we showed the outperformance of the ensemble regression model over the individual prediction model. We compared the performance of different regression models based on five different feature sets of lengths 6, 9, 12, 15, and 18. Our ensemble regression model achieved the minimum average gap of 5.04% between actual and predicted traffic with nine outlier-adjusted inputs. In general, our experimental results indicate that the outliers in the data can significantly impact the quality of the prediction. Thus, outlier detection and mitigation assist the regression model in learning the general trend and making better predictions.