 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning Based Efficient Traffic Prediction with Limited Training Data
May 09, 2022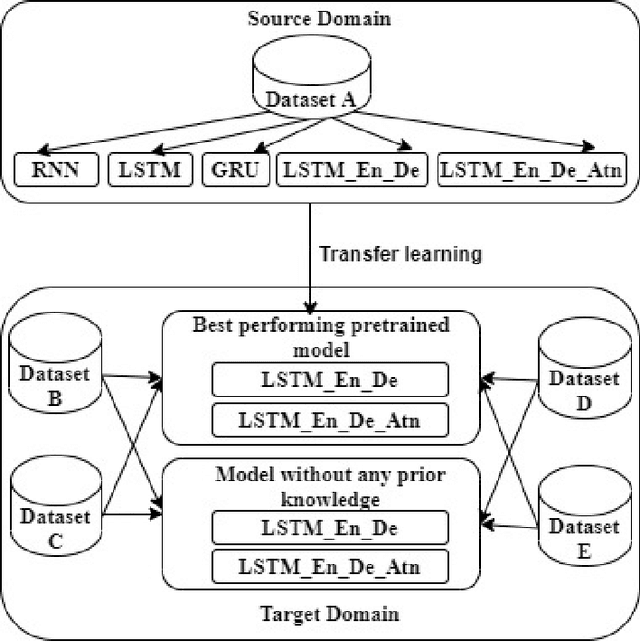
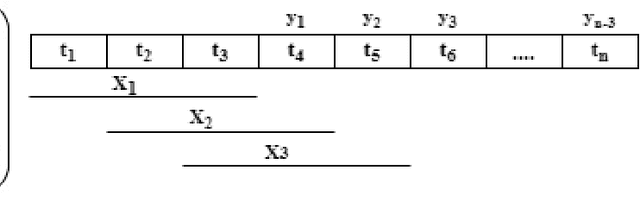
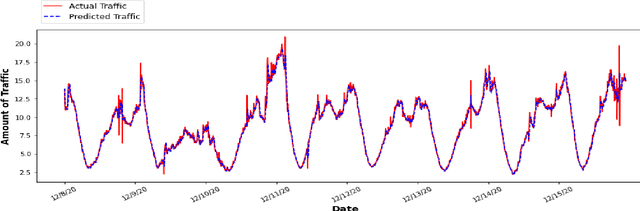
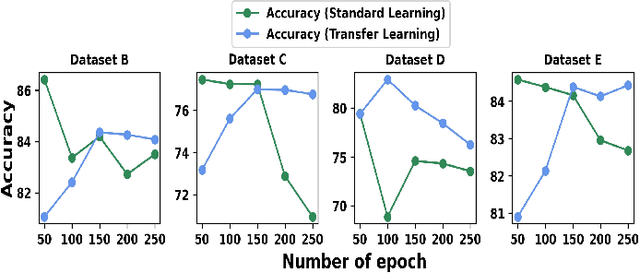
Efficient prediction of internet traffic is an essential part of Self Organizing Network (SON) for ensuring proactive management. There are many existing solutions for internet traffic prediction with higher accuracy using deep learning. But designing individual predictive models for each service provider in the network is challenging due to data heterogeneity, scarcity, and abnormality. Moreover, the performance of the deep sequence model in network traffic prediction with limited training data has not been studied extensively in the current works. In this paper, we investigated and evaluated the performance of the deep transfer learning technique in traffic prediction with inadequate historical data leveraging the knowledge of our pre-trained model. First, we used a comparatively larger real-world traffic dataset for source domain prediction based on five different deep sequence models: Recurrent Neural Network (RNN), Long Short-Term Memory (LSTM), LSTM Encoder-Decoder (LSTM_En_De), LSTM_En_De with Attention layer (LSTM_En_De_Atn), and Gated Recurrent Unit (GRU). Then, two best-performing models, LSTM_En_De and LSTM_En_De_Atn, from the source domain with an accuracy of 96.06% and 96.05% are considered for the target domain prediction. Finally, four smaller traffic datasets collected for four particular sources and destination pairs are used in the target domain to compare the performance of the standard learning and transfer learning in terms of accuracy and execution time. According to our experimental result, transfer learning helps to reduce the execution time for most cases, while the model's accuracy is improved in transfer learning with a larger training session.
Wavelet-Based Hybrid Machine Learning Model for Out-of-distribution Internet Traffic Prediction
May 09, 2022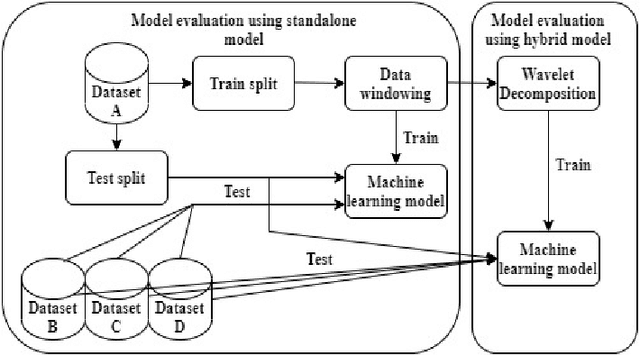
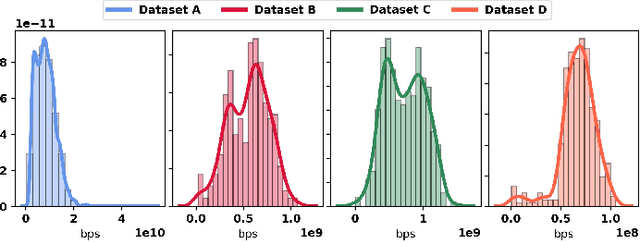
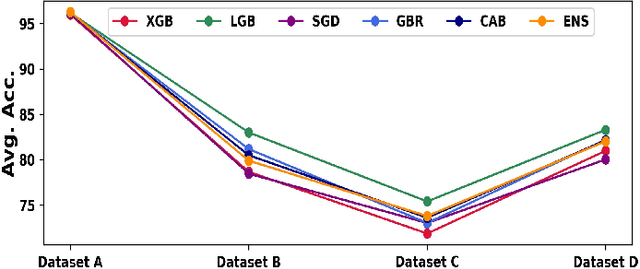

Efficient prediction of internet traffic is essential for ensuring proactive management of computer networks. Nowadays, machine learning approaches show promising performance in modeling real-world complex traffic. However, most existing works assumed that model training and evaluation data came from identical distribution. But in practice, there is a high probability that the model will deal with data from a slightly or entirely unknown distribution in the deployment phase. This paper investigated and evaluated machine learning performances using eXtreme Gradient Boosting, Light Gradient Boosting Machine, Stochastic Gradient Descent, Gradient Boosting Regressor, CatBoost Regressor, and their stacked ensemble model using data from both identical and out-of distribution. Also, we proposed a hybrid machine learning model integrating wavelet decomposition for improving out-of-distribution prediction as standalone models were unable to generalize very well. Our experimental results show the best performance of the standalone ensemble model with an accuracy of 96.4%, while the hybrid ensemble model improved it by 1% for in-distribution data. But its performance dropped significantly when tested with three different datasets having a distribution shift than the training set. However, our proposed hybrid model considerably reduces the performance gap between identical and out-of-distribution evaluation compared with the standalone model, indicating the decomposition technique's effectiveness in the case of out-of-distribution generalization.
Deep Sequence Modeling for Anomalous ISP Traffic Prediction
May 03, 2022
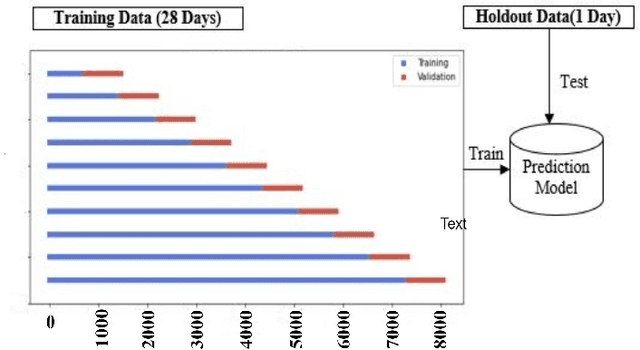
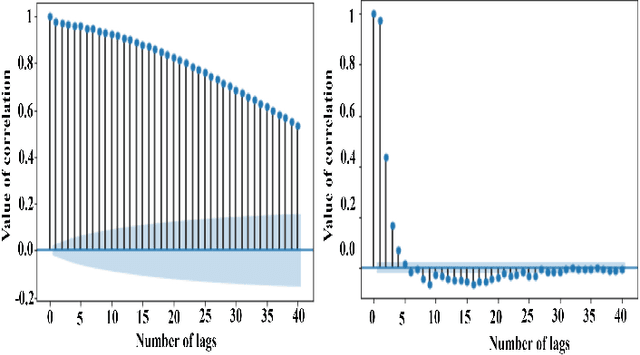
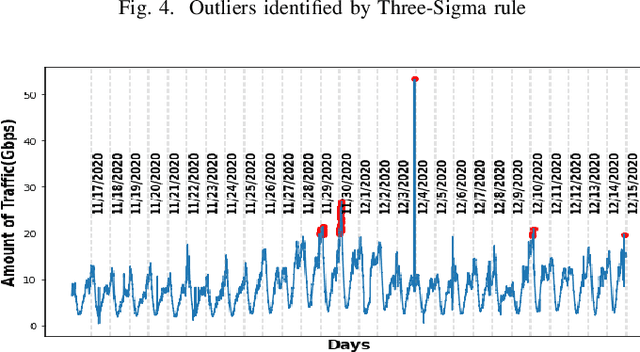
Internet traffic in the real world is susceptible to various external and internal factors which may abruptly change the normal traffic flow. Those unexpected changes are considered outliers in traffic. However, deep sequence models have been used to predict complex IP traffic, but their comparative performance for anomalous traffic has not been studied extensively. In this paper, we investigated and evaluated the performance of different deep sequence models for anomalous traffic prediction. Several deep sequences models were implemented to predict real traffic without and with outliers and show the significance of outlier detection in real-world traffic prediction. First, two different outlier detection techniques, such as the Three-Sigma rule and Isolation Forest, were applied to identify the anomaly. Second, we adjusted those abnormal data points using the Backward Filling technique before training the model. Finally, the performance of different models was compared for abnormal and adjusted traffic. LSTM_Encoder_Decoder (LSTM_En_De) is the best prediction model in our experiment, reducing the deviation between actual and predicted traffic by more than 11\% after adjusting the outliers. All other models, including Recurrent Neural Network (RNN), Long Short-Term Memory (LSTM), LSTM_En_De with Attention layer (LSTM_En_De_Atn), Gated Recurrent Unit (GRU), show better prediction after replacing the outliers and decreasing prediction error by more than 29%, 24%, 19%, and 10% respectively. Our experimental results indicate that the outliers in the data can significantly impact the quality of the prediction. Thus, outlier detection and mitigation assist the deep sequence model in learning the general trend and making better predictions.
An Empirical Study on Internet Traffic Prediction Using Statistical Rolling Model
May 03, 2022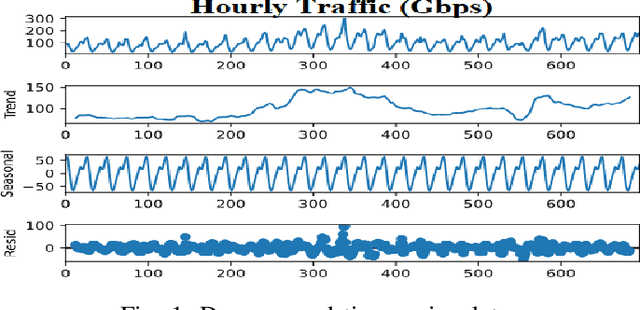
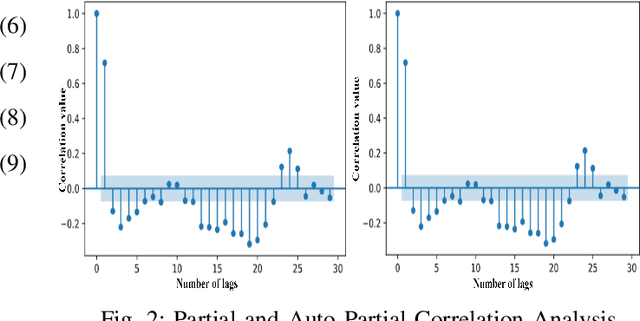
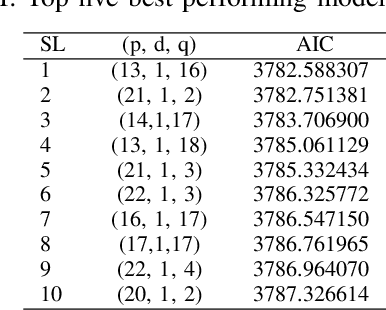
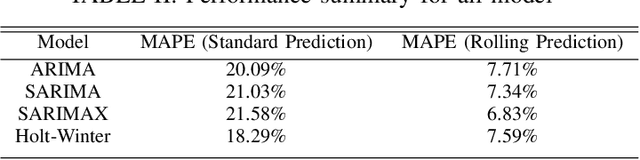
Real-world IP network traffic is susceptible to external and internal factors such as new internet service integration, traffic migration, internet application, etc. Due to these factors, the actual internet traffic is non-linear and challenging to analyze using a statistical model for future prediction. In this paper, we investigated and evaluated the performance of different statistical prediction models for real IP network traffic; and showed a significant improvement in prediction using the rolling prediction technique. Initially, a set of best hyper-parameters for the corresponding prediction model is identified by analyzing the traffic characteristics and implementing a grid search algorithm based on the minimum Akaike Information Criterion (AIC). Then, we performed a comparative performance analysis among AutoRegressive Integrated Moving Average (ARIMA), Seasonal ARIMA (SARIMA), SARIMA with eXogenous factors (SARIMAX), and Holt-Winter for single-step prediction. The seasonality of our traffic has been explicitly modeled using SARIMA, which reduces the rolling prediction Mean Average Percentage Error (MAPE) by more than 4% compared to ARIMA (incapable of handling the seasonality). We further improved traffic prediction using SARIMAX to learn different exogenous factors extracted from the original traffic, which yielded the best rolling prediction results with a MAPE of 6.83%. Finally, we applied the exponential smoothing technique to handle the variability in traffic following the Holt-Winter model, which exhibited a better prediction than ARIMA (around 1.5% less MAPE). The rolling prediction technique reduced prediction error using real Internet Service Provider (ISP) traffic data by more than 50\% compared to the standard prediction method.
Towards an Ensemble Regressor Model for Anomalous ISP Traffic Prediction
May 03, 2022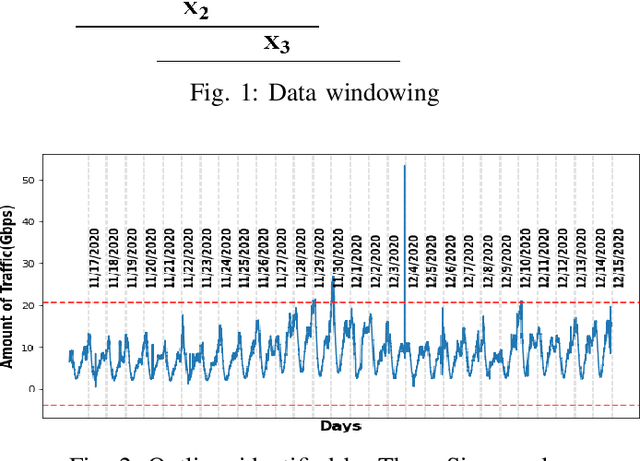
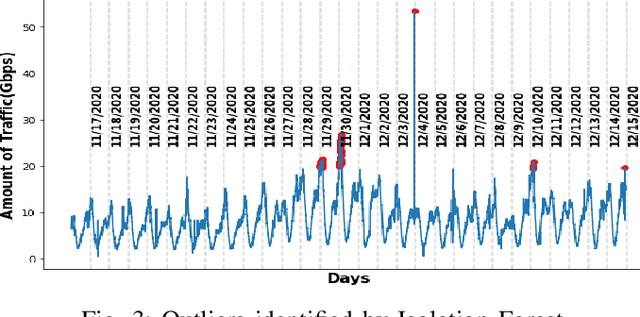
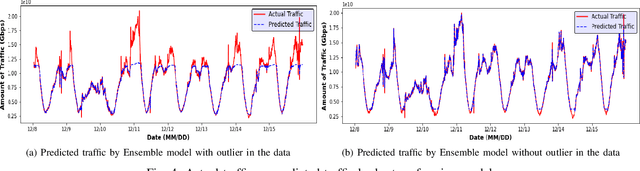
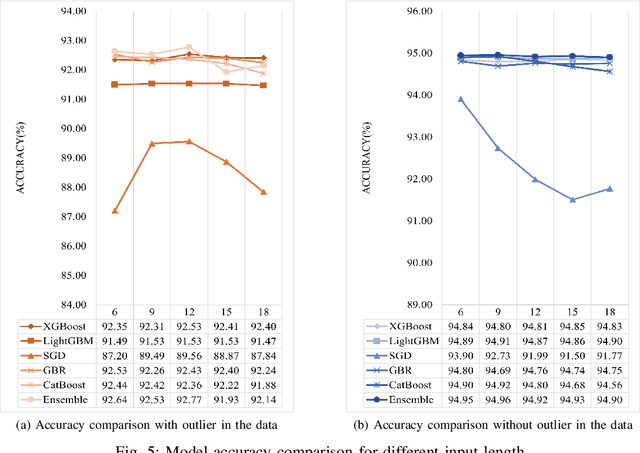
Prediction of network traffic behavior is significant for the effective management of modern telecommunication networks. However, the intuitive approach of predicting network traffic using administrative experience and market analysis data is inadequate for an efficient forecast framework. As a result, many different mathematical models have been studied to capture the general trend of the network traffic and predict accordingly. But the comprehensive performance analysis of varying regression models and their ensemble has not been studied before for analyzing real-world anomalous traffic. In this paper, several regression models such as Extra Gradient Boost (XGBoost), Light Gradient Boosting Machine (LightGBM), Stochastic Gradient Descent (SGD), Gradient Boosting Regressor (GBR), and CatBoost Regressor were analyzed to predict real traffic without and with outliers and show the significance of outlier detection in real-world traffic prediction. Also, we showed the outperformance of the ensemble regression model over the individual prediction model. We compared the performance of different regression models based on five different feature sets of lengths 6, 9, 12, 15, and 18. Our ensemble regression model achieved the minimum average gap of 5.04% between actual and predicted traffic with nine outlier-adjusted inputs. In general, our experimental results indicate that the outliers in the data can significantly impact the quality of the prediction. Thus, outlier detection and mitigation assist the regression model in learning the general trend and making better predictions.