 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Long-Term Memory using Hierarchical Aggregate Tree for Retrieval Augmented Generation
Jun 10, 2024Large language models have limited context capacity, hindering reasoning over long conversations. We propose the Hierarchical Aggregate Tree memory structure to recursively aggregate relevant dialogue context through conditional tree traversals. HAT encapsulates information from children nodes, enabling broad coverage with depth control. We formulate finding best context as optimal tree traversal. Experiments show HAT improves dialog coherence and summary quality over baseline contexts, demonstrating the techniques effectiveness for multi turn reasoning without exponential parameter growth. This memory augmentation enables more consistent, grounded longform conversations from LLMs
A Survey on the application of Data Science And Analytics in the field of Organised Sports
Sep 15, 2022



The application of Data Science and Analytics to optimize or predict outcomes is Ubiquitous in the Modern World. Data Science and Analytics have optimized almost every domain that exists in the market. In our survey, we focus on how the field of Analytics has been adopted in the field of sports, and how it has contributed to the transformation of the game right from the assessment of on-field players and their selection to the prediction of winning team and to the marketing of tickets and business aspects of big sports tournaments. We will present the analytical tools, algorithms, and methodologies adopted in the field of Sports Analytics for different sports and also present our views on the same and we will also compare and contrast these existing approaches. By doing so, we will also present the best tools, algorithms, and analytical methodologies to be considered by anyone who is looking to experiment with sports data and analyze various aspects of the game.
Data Science Approach to predict the winning Fantasy Cricket Team Dream 11 Fantasy Sports
Sep 15, 2022The evolution of digital technology and the increasing popularity of sports inspired the innovators to take the experience of users with a proclivity towards sports to a whole new different level, by introducing Fantasy Sports Platforms FSPs. The application of Data Science and Analytics is Ubiquitous in the Modern World. Data Science and Analytics open doors to gain a deeper understanding and help in the decision making process. We firmly believed that we could adopt Data Science to predict the winning fantasy cricket team on the FSP, Dream 11. We built a predictive model that predicts the performance of players in a prospective game. We used a combination of Greedy and Knapsack Algorithms to prescribe the combination of 11 players to create a fantasy cricket team that has the most significant statistical odds of finishing as the strongest team thereby giving us a higher chance of winning the pot of bets on the Dream 11 FSP. We used PyCaret Python Library to help us understand and adopt the best Regressor Algorithm for our problem statement to make precise predictions. Further, we used Plotly Python Library to give us visual insights into the team, and players performances by accounting for the statistical, and subjective factors of a prospective game. The interactive plots help us to bolster the recommendations of our predictive model. You either win big, win small, or lose your bet based on the performance of the players selected for your fantasy team in the prospective game, and our model increases the probability of you winning big.
Offensive Language Detection: A Comparative Analysis
Jan 09, 2020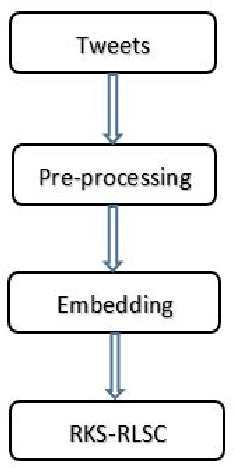
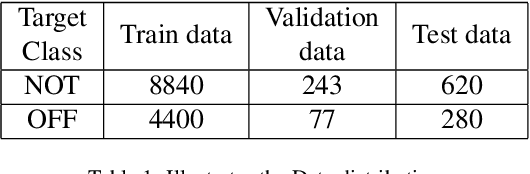

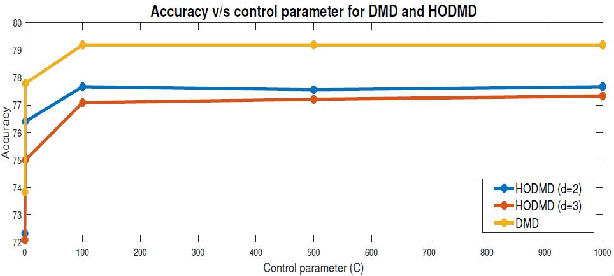
Offensive behaviour has become pervasive in the Internet community. Individuals take the advantage of anonymity in the cyber world and indulge in offensive communications which they may not consider in the real life. Governments, online communities, companies etc are investing into prevention of offensive behaviour content in social media. One of the most effective solution for tacking this enigmatic problem is the use of computational techniques to identify offensive content and take action. The current work focuses on detecting offensive language in English tweets. The dataset used for the experiment is obtained from SemEval-2019 Task 6 on Identifying and Categorizing Offensive Language in Social Media (OffensEval). The dataset contains 14,460 annotated English tweets. The present paper provides a comparative analysis and Random kitchen sink (RKS) based approach for offensive language detection. We explore the effectiveness of Google sentence encoder, Fasttext, Dynamic mode decomposition (DMD) based features and Random kitchen sink (RKS) method for offensive language detection. From the experiments and evaluation we observed that RKS with fastetxt achieved competing results. The evaluation measures used are accuracy, precision, recall, f1-score.
Salient Region Detection and Segmentation in Images using Dynamic Mode Decomposition
Jul 11, 2016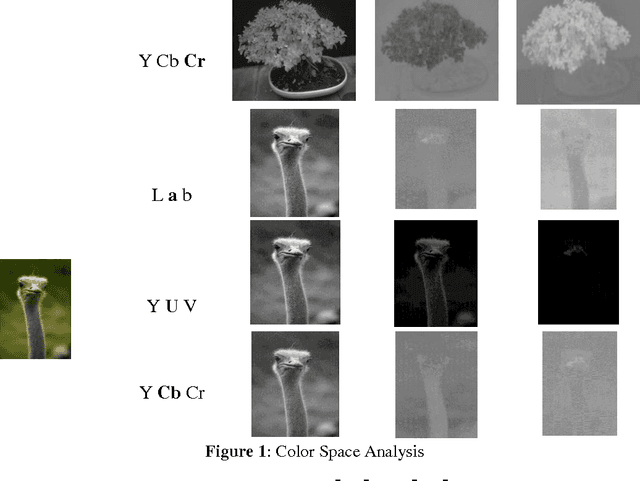


Visual Saliency is the capability of vision system to select distinctive parts of scene and reduce the amount of visual data that need to be processed. The presentpaper introduces (1) a novel approach to detect salient regions by considering color and luminance based saliency scores using Dynamic Mode Decomposition (DMD), (2) a new interpretation to use DMD approach in static image processing. This approach integrates two data analysis methods: (1) Fourier Transform, (2) Principle Component Analysis.The key idea of our work is to create a color based saliency map. This is based on the observation thatsalient part of an image usually have distinct colors compared to the remaining portion of the image. We have exploited the power of different color spaces to model the complex and nonlinear behavior of human visual system to generate a color based saliency map. To further improve the effect of final saliency map, weutilized luminance information exploiting the fact that human eye is more sensitive towards brightness than color.The experimental results shows that our method based on DMD theory is effective in comparison with previous state-of-art saliency estimation approaches. The approach presented in this paperis evaluated using ROC curve, F-measure rate, Precision-Recall rate, AUC score etc.