 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Long-Term Memory using Hierarchical Aggregate Tree for Retrieval Augmented Generation
Jun 10, 2024Large language models have limited context capacity, hindering reasoning over long conversations. We propose the Hierarchical Aggregate Tree memory structure to recursively aggregate relevant dialogue context through conditional tree traversals. HAT encapsulates information from children nodes, enabling broad coverage with depth control. We formulate finding best context as optimal tree traversal. Experiments show HAT improves dialog coherence and summary quality over baseline contexts, demonstrating the techniques effectiveness for multi turn reasoning without exponential parameter growth. This memory augmentation enables more consistent, grounded longform conversations from LLMs
Learning (With) Distributed Optimization
Aug 10, 2023
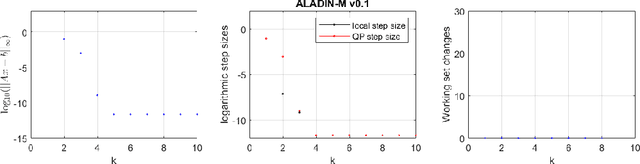
This paper provides an overview of the historical progression of distributed optimization techniques, tracing their development from early duality-based methods pioneered by Dantzig, Wolfe, and Benders in the 1960s to the emergence of the Augmented Lagrangian Alternating Direction Inexact Newton (ALADIN) algorithm. The initial focus on Lagrangian relaxation for convex problems and decomposition strategies led to the refinement of methods like the Alternating Direction Method of Multipliers (ADMM). The resurgence of interest in distributed optimization in the late 2000s, particularly in machine learning and imaging, demonstrated ADMM's practical efficacy and its unifying potential. This overview also highlights the emergence of the proximal center method and its applications in diverse domains. Furthermore, the paper underscores the distinctive features of ALADIN, which offers convergence guarantees for non-convex scenarios without introducing auxiliary variables, differentiating it from traditional augmentation techniques. In essence, this work encapsulates the historical trajectory of distributed optimization and underscores the promising prospects of ALADIN in addressing non-convex optimization challenges.