 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomized ICA and LDA Dimensionality Reduction Methods for Hyperspectral Image Classification
Apr 19, 2018



Dimensionality reduction is an important step in processing the hyperspectral images (HSI) to overcome the curse of dimensionality problem. Linear dimensionality reduction methods such as Independent component analysis (ICA) and Linear discriminant analysis (LDA) are commonly employed to reduce the dimensionality of HSI. These methods fail to capture non-linear dependency in the HSI data, as data lies in the nonlinear manifold. To handle this, nonlinear transformation techniques based on kernel methods were introduced for dimensionality reduction of HSI. However, the kernel methods involve cubic computational complexity while computing the kernel matrix, and thus its potential cannot be explored when the number of pixels (samples) are large. In literature a fewer number of pixels are randomly selected to partial to overcome this issue, however this sub-optimal strategy might neglect important information in the HSI. In this paper, we propose randomized solutions to the ICA and LDA dimensionality reduction methods using Random Fourier features, and we label them as RFFICA and RFFLDA. Our proposed method overcomes the scalability issue and to handle the non-linearities present in the data more efficiently. Experiments conducted with two real-world hyperspectral datasets demonstrates that our proposed randomized methods outperform the conventional kernel ICA and kernel LDA in terms overall, per-class accuracies and computational time.
Dependency resolution and semantic mining using Tree Adjoining Grammars for Tamil Language
Apr 19, 2017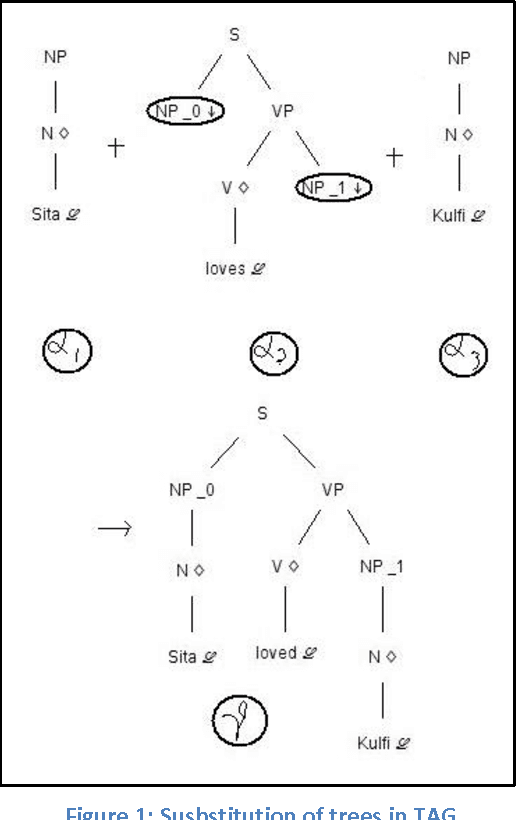
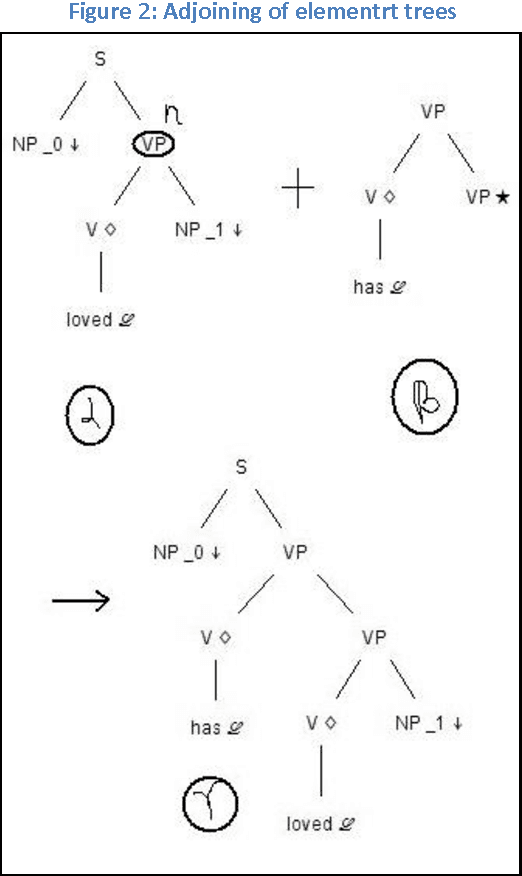
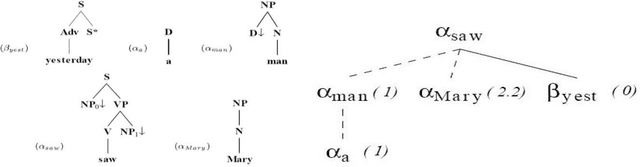
Tree adjoining grammars (TAGs) provide an ample tool to capture syntax of many Indian languages. Tamil represents a special challenge to computational formalisms as it has extensive agglutinative morphology and a comparatively difficult argument structure. Modelling Tamil syntax and morphology using TAG is an interesting problem which has not been in focus even though TAGs are over 4 decades old, since its inception. Our research with Tamil TAGs have shown us that we can not only represent syntax of the language, but to an extent mine out semantics through dependency resolution of the sentence. But in order to demonstrate this phenomenal property, we need to parse Tamil language sentences using TAGs we have built and through parsing obtain a derivation we could use to resolve dependencies, thus proving the semantic property. We use an in-house developed pseudo lexical TAG chart parser; algorithm given by Schabes and Joshi (1988), for generating derivations of sentences. We do not use any statistics to rank out ambiguous derivations but rather use all of them to understand the mentioned semantic relation with in TAGs for Tamil. We shall also present a brief parser analysis for the completeness of our discussions.
Salient Region Detection and Segmentation in Images using Dynamic Mode Decomposition
Jul 11, 2016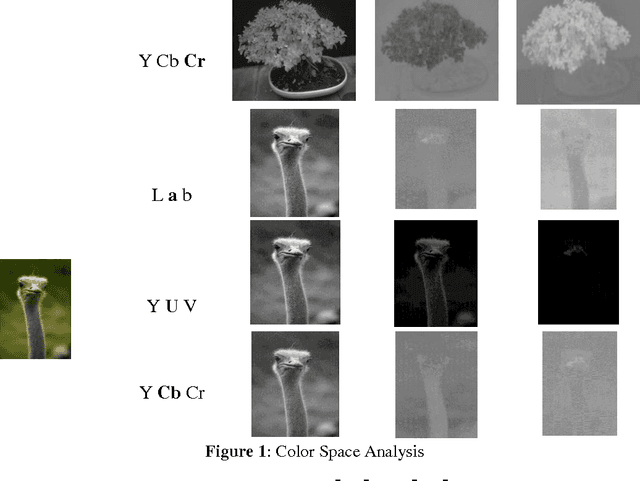


Visual Saliency is the capability of vision system to select distinctive parts of scene and reduce the amount of visual data that need to be processed. The presentpaper introduces (1) a novel approach to detect salient regions by considering color and luminance based saliency scores using Dynamic Mode Decomposition (DMD), (2) a new interpretation to use DMD approach in static image processing. This approach integrates two data analysis methods: (1) Fourier Transform, (2) Principle Component Analysis.The key idea of our work is to create a color based saliency map. This is based on the observation thatsalient part of an image usually have distinct colors compared to the remaining portion of the image. We have exploited the power of different color spaces to model the complex and nonlinear behavior of human visual system to generate a color based saliency map. To further improve the effect of final saliency map, weutilized luminance information exploiting the fact that human eye is more sensitive towards brightness than color.The experimental results shows that our method based on DMD theory is effective in comparison with previous state-of-art saliency estimation approaches. The approach presented in this paperis evaluated using ROC curve, F-measure rate, Precision-Recall rate, AUC score etc.