 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Association Measures and their Combination for Arabic MWT Extraction
Sep 10, 2014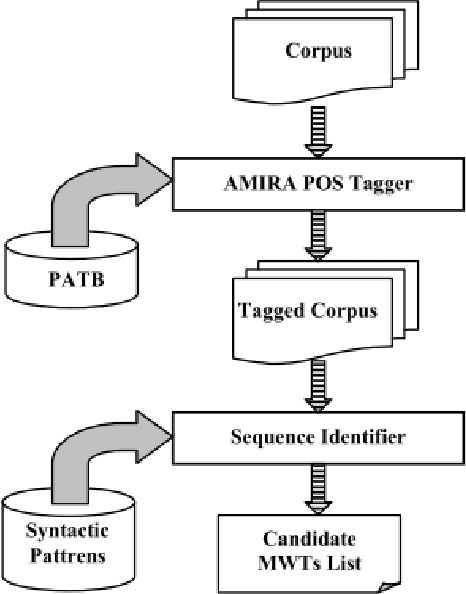


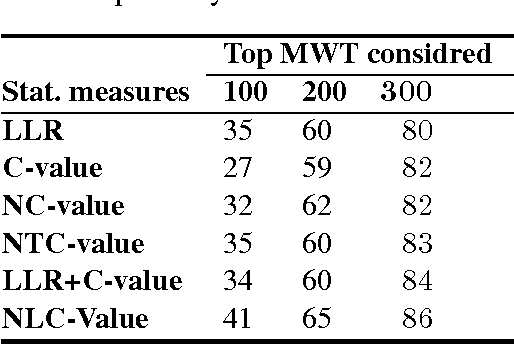
Automatic Multi-Word Term (MWT) extraction is a very important issue to many applications, such as information retrieval, question answering, and text categorization. Although many methods have been used for MWT extraction in English and other European languages, few studies have been applied to Arabic. In this paper, we propose a novel, hybrid method which combines linguistic and statistical approaches for Arabic Multi-Word Term extraction. The main contribution of our method is to consider contextual information and both termhood and unithood for association measures at the statistical filtering step. In addition, our technique takes into account the problem of MWT variation in the linguistic filtering step. The performance of the proposed statistical measure (NLC-value) is evaluated using an Arabic environment corpus by comparing it with some existing competitors. Experimental results show that our NLC-value measure outperforms the other ones in term of precision for both bi-grams and tri-grams.