 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Linguistic Similarity and Zero-Shot Learning for Multilingual Translation of Dravidian Languages
Aug 10, 2023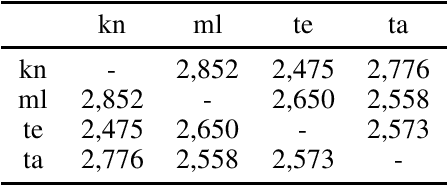
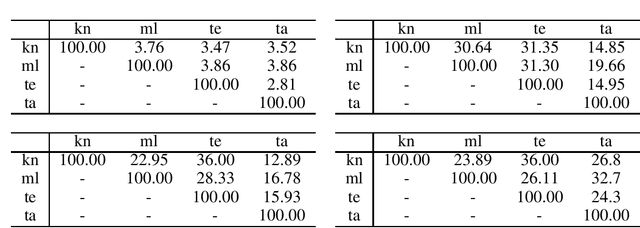
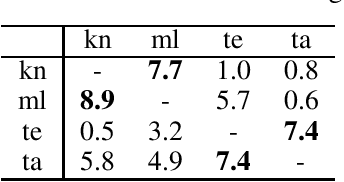
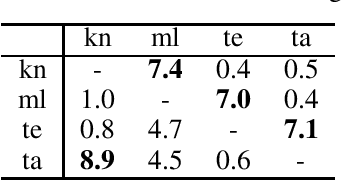
Current research in zero-shot translation is plagued by several issues such as high compute requirements, increased training time and off target translations. Proposed remedies often come at the cost of additional data or compute requirements. Pivot based neural machine translation is preferred over a single-encoder model for most settings despite the increased training and evaluation time. In this work, we overcome the shortcomings of zero-shot translation by taking advantage of transliteration and linguistic similarity. We build a single encoder-decoder neural machine translation system for Dravidian-Dravidian multilingual translation and perform zero-shot translation. We compare the data vs zero-shot accuracy tradeoff and evaluate the performance of our vanilla method against the current state of the art pivot based method. We also test the theory that morphologically rich languages require large vocabularies by restricting the vocabulary using an optimal transport based technique. Our model manages to achieves scores within 3 BLEU of large-scale pivot-based models when it is trained on 50\% of the language directions.
Neural-network acceleration of projection-based model-order-reduction for finite plasticity: Application to RVEs
Sep 16, 2021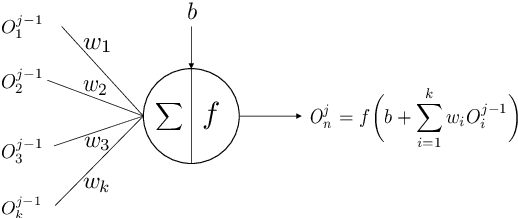

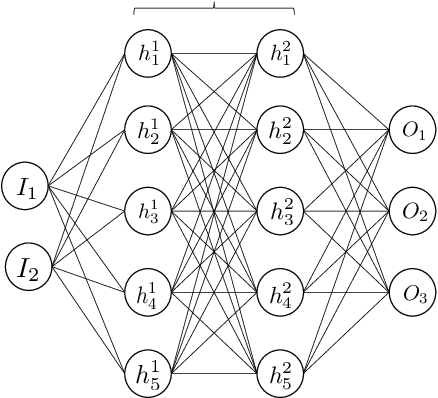
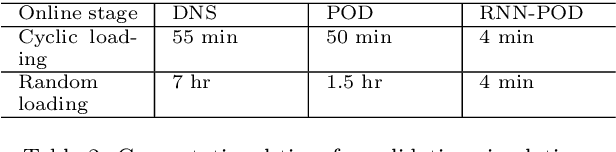
Compared to conventional projection-based model-order-reduction, its neural-network acceleration has the advantage that the online simulations are equation-free, meaning that no system of equations needs to be solved iteratively. Consequently, no stiffness matrix needs to be constructed and the stress update needs to be computed only once per increment. In this contribution, a recurrent neural network is developed to accelerate a projection-based model-order-reduction of the elastoplastic mechanical behaviour of an RVE. In contrast to a neural network that merely emulates the relation between the macroscopic deformation (path) and the macroscopic stress, the neural network acceleration of projection-based model-order-reduction preserves all microstructural information, at the price of computing this information once per increment.
A New Backpropagation Algorithm without Gradient Descent
Jan 25, 2018



The backpropagation algorithm, which had been originally introduced in the 1970s, is the workhorse of learning in neural networks. This backpropagation algorithm makes use of the famous machine learning algorithm known as Gradient Descent, which is a first-order iterative optimization algorithm for finding the minimum of a function. To find a local minimum of a function using gradient descent, one takes steps proportional to the negative of the gradient (or of the approximate gradient) of the function at the current point. In this paper, we develop an alternative to the backpropagation without the use of the Gradient Descent Algorithm, but instead we are going to devise a new algorithm to find the error in the weights and biases of an artificial neuron using Moore-Penrose Pseudo Inverse. The numerical studies and the experiments performed on various datasets are used to verify the working of this alternative algorithm.
A Data Mining Approach to the Diagnosis of Tuberculosis by Cascading Clustering and Classification
Aug 04, 2011
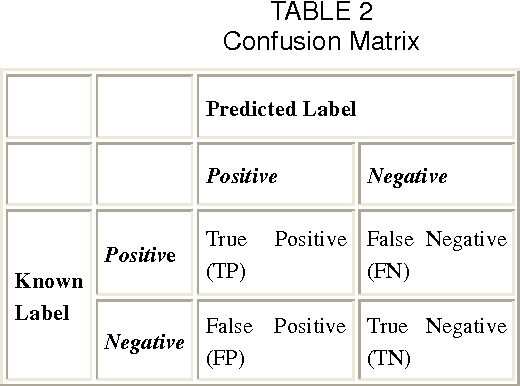
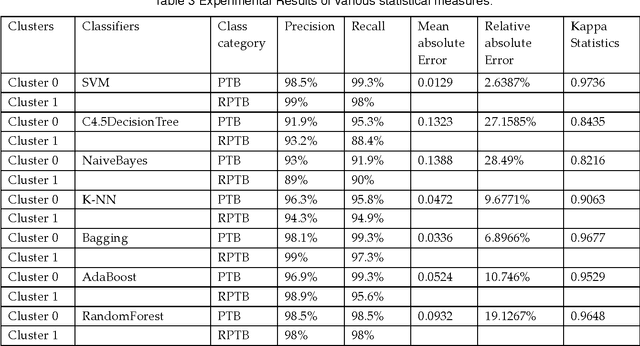
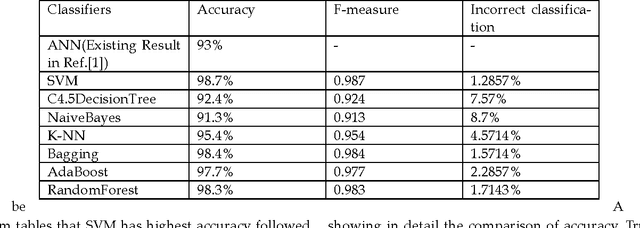
In this paper, a methodology for the automated detection and classification of Tuberculosis(TB) is presented. Tuberculosis is a disease caused by mycobacterium which spreads through the air and attacks low immune bodies easily. Our methodology is based on clustering and classification that classifies TB into two categories, Pulmonary Tuberculosis(PTB) and retroviral PTB(RPTB) that is those with Human Immunodeficiency Virus (HIV) infection. Initially K-means clustering is used to group the TB data into two clusters and assigns classes to clusters. Subsequently multiple different classification algorithms are trained on the result set to build the final classifier model based on K-fold cross validation method. This methodology is evaluated using 700 raw TB data obtained from a city hospital. The best obtained accuracy was 98.7% from support vector machine (SVM) compared to other classifiers. The proposed approach helps doctors in their diagnosis decisions and also in their treatment planning procedures for different categories.
* 8 pages