 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Efficient Swimming Strategies in a Three Dimensional Chaotic Flow by Reinforcement Learning
Dec 31, 2017
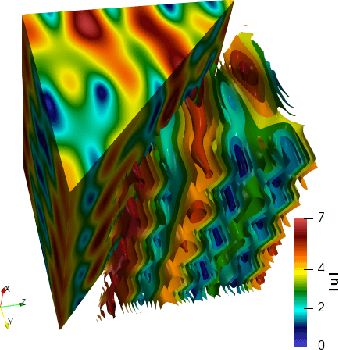

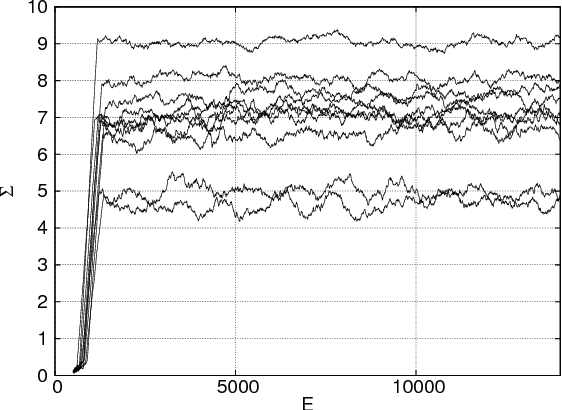
We apply a reinforcement learning algorithm to show how smart particles can learn approximately optimal strategies to navigate in complex flows. In this paper we consider microswimmers in a paradigmatic three-dimensional case given by a stationary superposition of two Arnold-Beltrami-Childress flows with chaotic advection along streamlines. In such a flow, we study the evolution of point-like particles which can decide in which direction to swim, while keeping the velocity amplitude constant. We show that it is sufficient to endow the swimmers with a very restricted set of actions (six fixed swimming directions in our case) to have enough freedom to find efficient strategies to move upward and escape local fluid traps. The key ingredient is the learning-from-experience structure of the algorithm, which assigns positive or negative rewards depending on whether the taken action is, or is not, profitable for the predetermined goal in the long term horizon. This is another example supporting the efficiency of the reinforcement learning approach to learn how to accomplish difficult tasks in complex fluid environments.
* Published on Eur. Phys. J. E (December 14, 2017)