 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Inference Machines as inverse problem solvers for MR relaxometry
Jun 08, 2021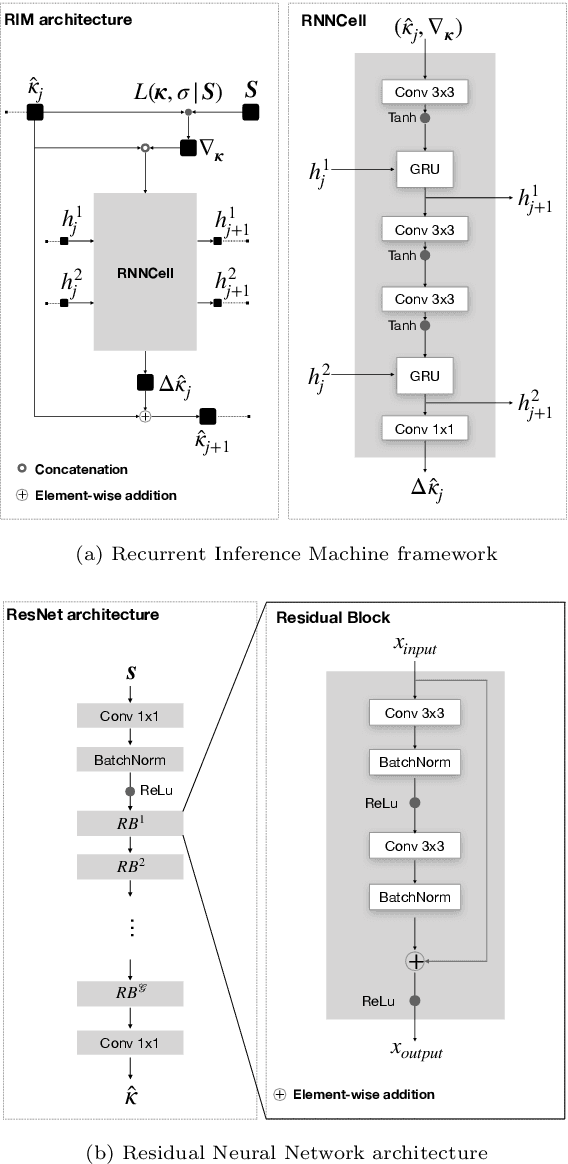
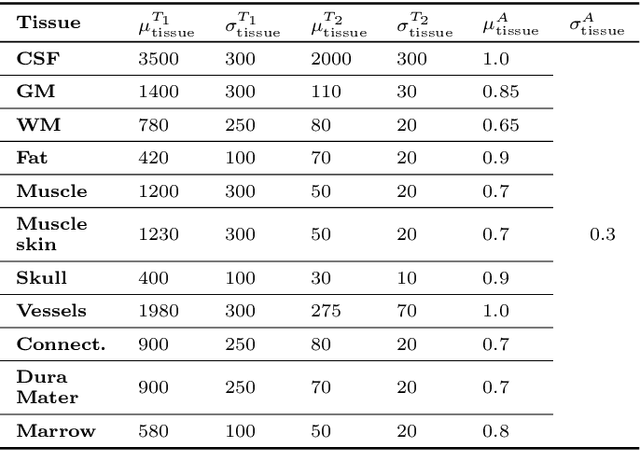
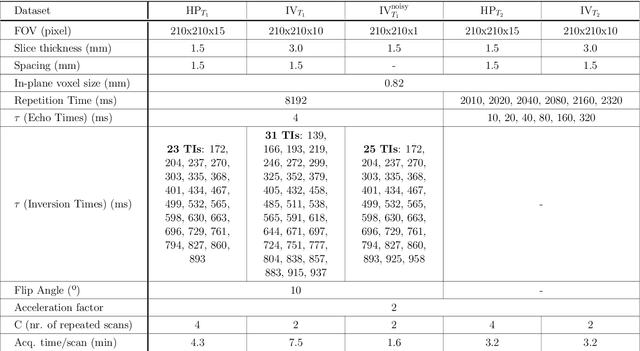
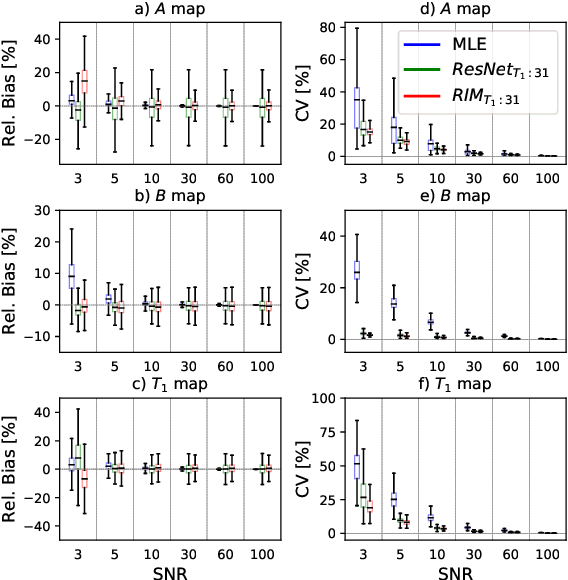
In this paper, we propose the use of Recurrent Inference Machines (RIMs) to perform T1 and T2 mapping. The RIM is a neural network framework that learns an iterative inference process based on the signal model, similar to conventional statistical methods for quantitative MRI (QMRI), such as the Maximum Likelihood Estimator (MLE). This framework combines the advantages of both data-driven and model-based methods, and, we hypothesize, is a promising tool for QMRI. Previously, RIMs were used to solve linear inverse reconstruction problems. Here, we show that they can also be used to optimize non-linear problems and estimate relaxometry maps with high precision and accuracy. The developed RIM framework is evaluated in terms of accuracy and precision and compared to an MLE method and an implementation of the ResNet. The results show that the RIM improves the quality of estimates compared to the other techniques in Monte Carlo experiments with simulated data, test-retest analysis of a system phantom, and in-vivo scans. Additionally, inference with the RIM is 150 times faster than the MLE, and robustness to (slight) variations of scanning parameters is demonstrated. Hence, the RIM is a promising and flexible method for QMRI. Coupled with an open-source training data generation tool, it presents a compelling alternative to previous methods.
Depth from Monocular Images using a Semi-Parallel Deep Neural Network Hybrid Architecture
Apr 18, 2018



Deep neural networks are applied to a wide range of problems in recent years. In this work, Convolutional Neural Network (CNN) is applied to the problem of determining the depth from a single camera image (monocular depth). Eight different networks are designed to perform depth estimation, each of them suitable for a feature level. Networks with different pooling sizes determine different feature levels. After designing a set of networks, these models may be combined into a single network topology using graph optimization techniques. This "Semi Parallel Deep Neural Network (SPDNN)" eliminates duplicated common network layers, and can be further optimized by retraining to achieve an improved model compared to the individual topologies. In this study, four SPDNN models are trained and have been evaluated at 2 stages on the KITTI dataset. The ground truth images in the first part of the experiment are provided by the benchmark, and for the second part, the ground truth images are the depth map results from applying a state-of-the-art stereo matching method. The results of this evaluation demonstrate that using post-processing techniques to refine the target of the network increases the accuracy of depth estimation on individual mono images. The second evaluation shows that using segmentation data alongside the original data as the input can improve the depth estimation results to a point where performance is comparable with stereo depth estimation. The computational time is also discussed in this study.
* 44 pages, 25 figures