Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA reproduction of Apple's bi-directional LSTM models for language identification in short strings
Feb 11, 2021
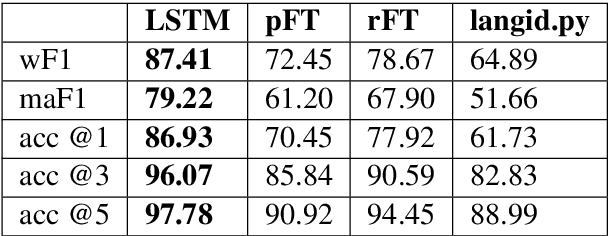
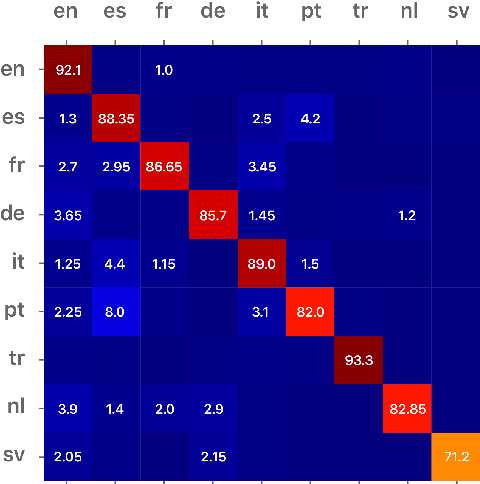
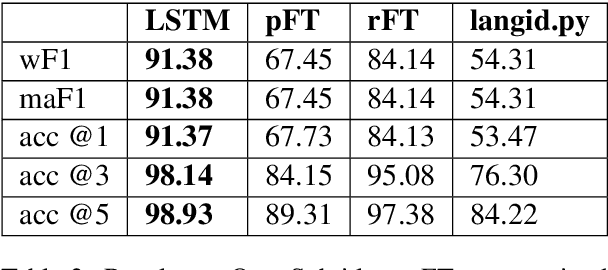
Language Identification is the task of identifying a document's language. For applications like automatic spell checker selection, language identification must use very short strings such as text message fragments. In this work, we reproduce a language identification architecture that Apple briefly sketched in a blog post. We confirm the bi-LSTM model's performance and find that it outperforms current open-source language identifiers. We further find that its language identification mistakes are due to confusion between related languages.
* Will be presented at EACL 2021 SRW
Via