 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Physical Metaphor to Study Semantic Drift
Aug 03, 2016
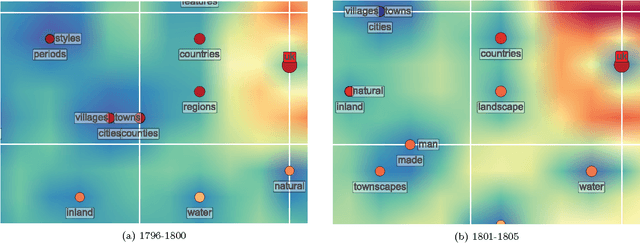
In accessibility tests for digital preservation, over time we experience drifts of localized and labelled content in statistical models of evolving semantics represented as a vector field. This articulates the need to detect, measure, interpret and model outcomes of knowledge dynamics. To this end we employ a high-performance machine learning algorithm for the training of extremely large emergent self-organizing maps for exploratory data analysis. The working hypothesis we present here is that the dynamics of semantic drifts can be modeled on a relaxed version of Newtonian mechanics called social mechanics. By using term distances as a measure of semantic relatedness vs. their PageRank values indicating social importance and applied as variable `term mass', gravitation as a metaphor to express changes in the semantic content of a vector field lends a new perspective for experimentation. From `term gravitation' over time, one can compute its generating potential whose fluctuations manifest modifications in pairwise term similarity vs. social importance, thereby updating Osgood's semantic differential. The dataset examined is the public catalog metadata of Tate Galleries, London.
Monitoring Term Drift Based on Semantic Consistency in an Evolving Vector Field
Feb 05, 2015
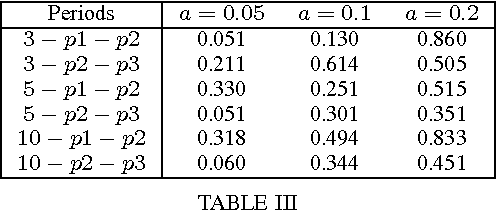
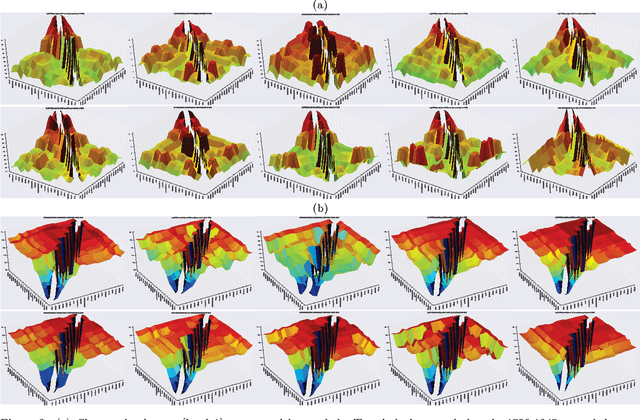
Based on the Aristotelian concept of potentiality vs. actuality allowing for the study of energy and dynamics in language, we propose a field approach to lexical analysis. Falling back on the distributional hypothesis to statistically model word meaning, we used evolving fields as a metaphor to express time-dependent changes in a vector space model by a combination of random indexing and evolving self-organizing maps (ESOM). To monitor semantic drifts within the observation period, an experiment was carried out on the term space of a collection of 12.8 million Amazon book reviews. For evaluation, the semantic consistency of ESOM term clusters was compared with their respective neighbourhoods in WordNet, and contrasted with distances among term vectors by random indexing. We found that at 0.05 level of significance, the terms in the clusters showed a high level of semantic consistency. Tracking the drift of distributional patterns in the term space across time periods, we found that consistency decreased, but not at a statistically significant level. Our method is highly scalable, with interpretations in philosophy.
* 8 pages, 1 figure. Code used to conduct the experiments is available at https://github.com/peterwittek/concept_drifts