 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Resolution Flood Probability Mapping Using Generative Machine Learning with Large-Scale Synthetic Precipitation and Inundation Data
Sep 20, 2024



High-resolution flood probability maps are essential for addressing the limitations of existing flood risk assessment approaches but are often limited by the availability of historical event data. Also, producing simulated data needed for creating probabilistic flood maps using physics-based models involves significant computation and time effort inhibiting the feasibility. To address this gap, this study introduces Flood-Precip GAN (Flood-Precipitation Generative Adversarial Network), a novel methodology that leverages generative machine learning to simulate large-scale synthetic inundation data to produce probabilistic flood maps. With a focus on Harris County, Texas, Flood-Precip GAN begins with training a cell-wise depth estimator using a limited number of physics-based model-generated precipitation-flood events. This model, which emphasizes precipitation-based features, outperforms universal models. Subsequently, a Generative Adversarial Network (GAN) with constraints is employed to conditionally generate synthetic precipitation records. Strategic thresholds are established to filter these records, ensuring close alignment with true precipitation patterns. For each cell, synthetic events are smoothed using a K-nearest neighbors algorithm and processed through the depth estimator to derive synthetic depth distributions. By iterating this procedure and after generating 10,000 synthetic precipitation-flood events, we construct flood probability maps in various formats, considering different inundation depths. Validation through similarity and correlation metrics confirms the fidelity of the synthetic depth distributions relative to true data. Flood-Precip GAN provides a scalable solution for generating synthetic flood depth data needed to create high-resolution flood probability maps, significantly enhancing flood preparedness and mitigation efforts.
Predicting Road Flooding Risk with Machine Learning Approaches Using Crowdsourced Reports and Fine-grained Traffic Data
Aug 30, 2021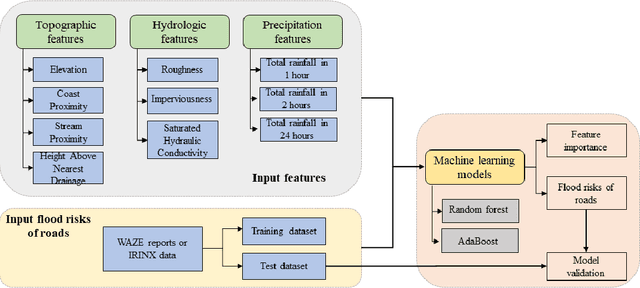

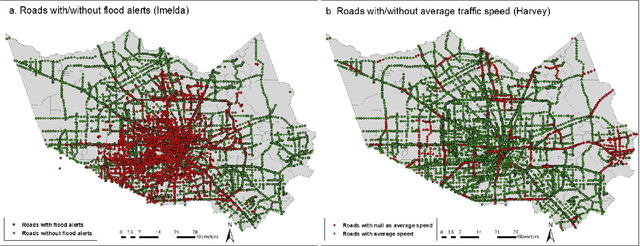
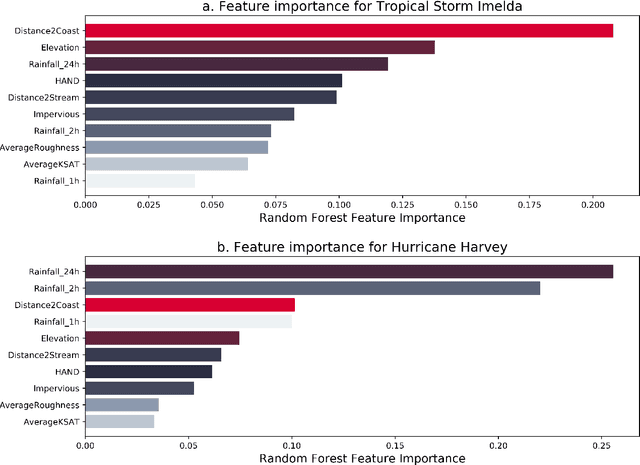
The objective of this study is to predict road flooding risks based on topographic, hydrologic, and temporal precipitation features using machine learning models. Predictive flood monitoring of road network flooding status plays an essential role in community hazard mitigation, preparedness, and response activities. Existing studies related to the estimation of road inundations either lack observed road inundation data for model validations or focus mainly on road inundation exposure assessment based on flood maps. This study addresses this limitation by using crowdsourced and fine-grained traffic data as an indicator of road inundation, and topographic, hydrologic, and temporal precipitation features as predictor variables. Two tree-based machine learning models (random forest and AdaBoost) were then tested and trained for predicting road inundations in the contexts of 2017 Hurricane Harvey and 2019 Tropical Storm Imelda in Harris County, Texas. The findings from Hurricane Harvey indicate that precipitation is the most important feature for predicting road inundation susceptibility, and that topographic features are more essential than hydrologic features for predicting road inundations in both storm cases. The random forest and AdaBoost models had relatively high AUC scores (0.860 and 0.810 for Harvey respectively and 0.790 and 0.720 for Imelda respectively) with the random forest model performing better in both cases. The random forest model showed stable performance for Harvey, while varying significantly for Imelda. This study advances the emerging field of smart flood resilience in terms of predictive flood risk mapping at the road level. For example, such models could help impacted communities and emergency management agencies develop better preparedness and response strategies with improved situational awareness of road inundation likelihood as an extreme weather event unfolds.