 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining contextual and local edges for line segment extraction in cluttered images
Nov 16, 2014



Automatic extraction methods typically assume that line segments are pronounced, thin, few and far between, do not cross each other, and are noise and clutter-free. Since these assumptions often fail in realistic scenarios, many line segments are not detected or are fragmented. In more severe cases, i.e., many who use the Hough Transform, extraction can fail entirely. In this paper, we propose a method that tackles these issues. Its key aspect is the combination of thresholded image derivatives obtained with filters of large and small footprints, which we denote as contextual and local edges, respectively. Contextual edges are robust to noise and we use them to select valid local edges, i.e., local edges that are of the same type as contextual ones: dark-to-bright transition of vice-versa. If the distance between valid local edges does not exceed a maximum distance threshold, we enforce connectivity by marking them and the pixels in between as edge points. This originates connected edge maps that are robust and well localized. We use a powerful two-sample statistical test to compute contextual edges, which we introduce briefly, as they are unfamiliar to the image processing community. Finally, we present experiments that illustrate, with synthetic and real images, how our method is efficient in extracting complete segments of all lengths and widths in several situations where current methods fail.
Connectivity-Enforcing Hough Transform for the Robust Extraction of Line Segments
Sep 16, 2011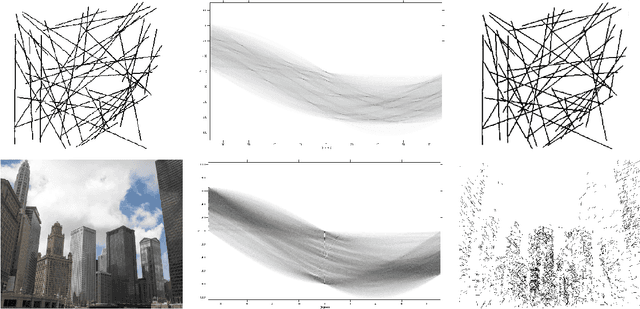
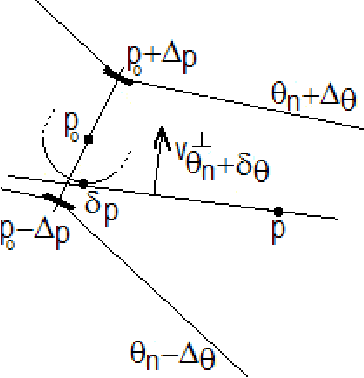
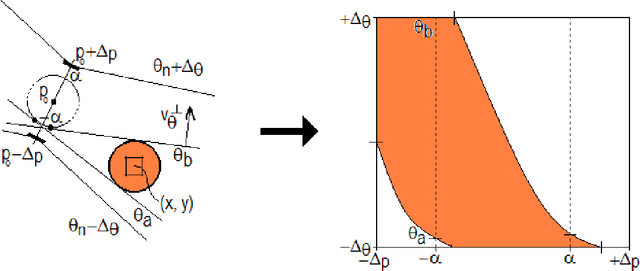
Global voting schemes based on the Hough transform (HT) have been widely used to robustly detect lines in images. However, since the votes do not take line connectivity into account, these methods do not deal well with cluttered images. In opposition, the so-called local methods enforce connectivity but lack robustness to deal with challenging situations that occur in many realistic scenarios, e.g., when line segments cross or when long segments are corrupted. In this paper, we address the critical limitations of the HT as a line segment extractor by incorporating connectivity in the voting process. This is done by only accounting for the contributions of edge points lying in increasingly larger neighborhoods and whose position and directional content agree with potential line segments. As a result, our method, which we call STRAIGHT (Segment exTRAction by connectivity-enforcInG HT), extracts the longest connected segments in each location of the image, thus also integrating into the HT voting process the usually separate step of individual segment extraction. The usage of the Hough space mapping and a corresponding hierarchical implementation make our approach computationally feasible. We present experiments that illustrate, with synthetic and real images, how STRAIGHT succeeds in extracting complete segments in several situations where current methods fail.
3-D Rigid Models from Partial Views - Global Factorization
Oct 19, 2010
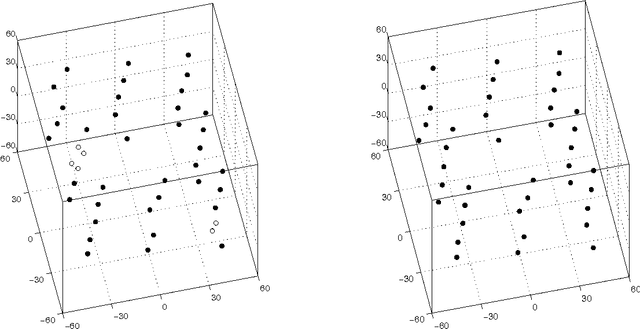
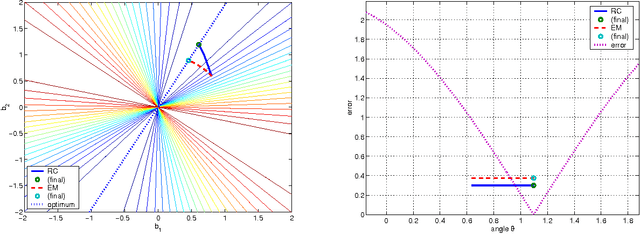
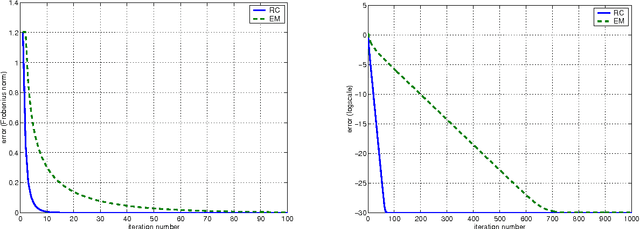
The so-called factorization methods recover 3-D rigid structure from motion by factorizing an observation matrix that collects 2-D projections of features. These methods became popular due to their robustness - they use a large number of views, which constrains adequately the solution - and computational simplicity - the large number of unknowns is computed through an SVD, avoiding non-linear optimization. However, they require that all the entries of the observation matrix are known. This is unlikely to happen in practice, due to self-occlusion and limited field of view. Also, when processing long videos, regions that become occluded often appear again later. Current factorization methods process these as new regions, leading to less accurate estimates of 3-D structure. In this paper, we propose a global factorization method that infers complete 3-D models directly from the 2-D projections in the entire set of available video frames. Our method decides whether a region that has become visible is a region that was seen before, or a previously unseen region, in a global way, i.e., by seeking the simplest rigid object that describes well the entire set of observations. This global approach increases significantly the accuracy of the estimates of the 3-D shape of the scene and the 3-D motion of the camera. Experiments with artificial and real videos illustrate the good performance of our method.