 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3-D Rigid Models from Partial Views - Global Factorization
Oct 19, 2010
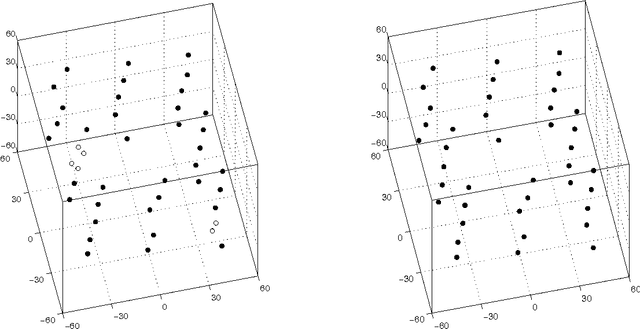
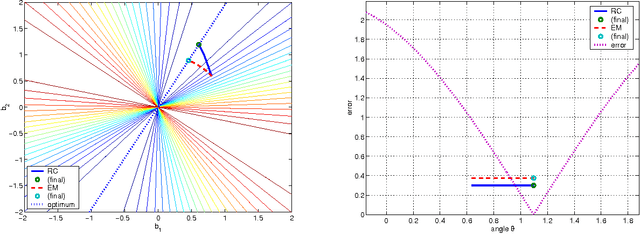
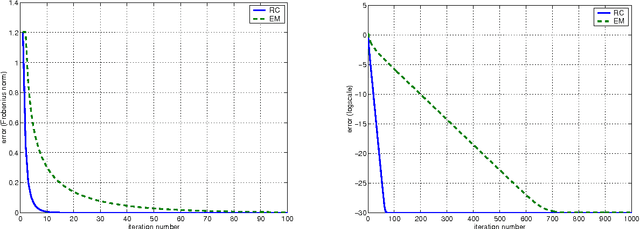
The so-called factorization methods recover 3-D rigid structure from motion by factorizing an observation matrix that collects 2-D projections of features. These methods became popular due to their robustness - they use a large number of views, which constrains adequately the solution - and computational simplicity - the large number of unknowns is computed through an SVD, avoiding non-linear optimization. However, they require that all the entries of the observation matrix are known. This is unlikely to happen in practice, due to self-occlusion and limited field of view. Also, when processing long videos, regions that become occluded often appear again later. Current factorization methods process these as new regions, leading to less accurate estimates of 3-D structure. In this paper, we propose a global factorization method that infers complete 3-D models directly from the 2-D projections in the entire set of available video frames. Our method decides whether a region that has become visible is a region that was seen before, or a previously unseen region, in a global way, i.e., by seeking the simplest rigid object that describes well the entire set of observations. This global approach increases significantly the accuracy of the estimates of the 3-D shape of the scene and the 3-D motion of the camera. Experiments with artificial and real videos illustrate the good performance of our method.