 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraspME -- Grasp Manifold Estimator
Jul 05, 2021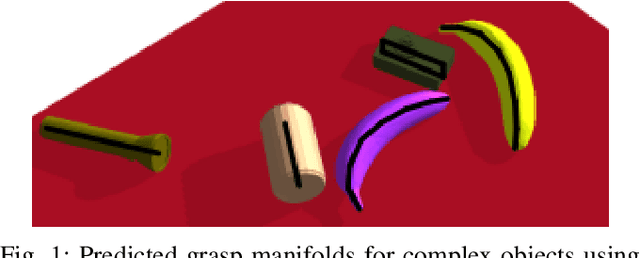


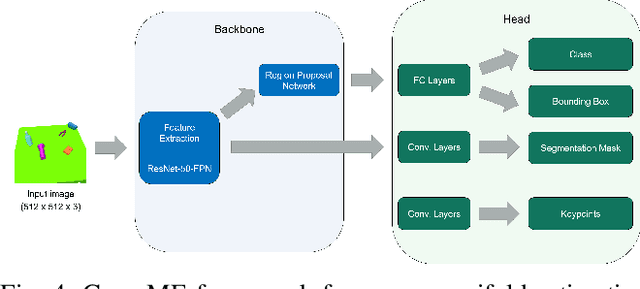
In this paper, we introduce a Grasp Manifold Estimator (GraspME) to detect grasp affordances for objects directly in 2D camera images. To perform manipulation tasks autonomously it is crucial for robots to have such graspability models of the surrounding objects. Grasp manifolds have the advantage of providing continuously infinitely many grasps, which is not the case when using other grasp representations such as predefined grasp points. For instance, this property can be leveraged in motion optimization to define goal sets as implicit surface constraints in the robot configuration space. In this work, we restrict ourselves to the case of estimating possible end-effector positions directly from 2D camera images. To this extend, we define grasp manifolds via a set of key points and locate them in images using a Mask R-CNN backbone. Using learned features allows generalizing to different view angles, with potentially noisy images, and objects that were not part of the training set. We rely on simulation data only and perform experiments on simple and complex objects, including unseen ones. Our framework achieves an inference speed of 11.5 fps on a GPU, an average precision for keypoint estimation of 94.5% and a mean pixel distance of only 1.29. This shows that we can estimate the objects very well via bounding boxes and segmentation masks as well as approximate the correct grasp manifold's keypoint coordinates.