 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Encoding of Satellite Image Time Series
May 03, 2023
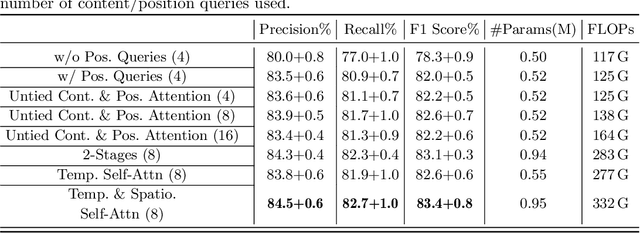

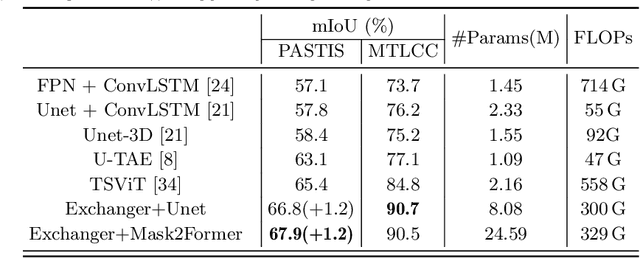
Representation learning of Satellite Image Time Series (SITS) presents its unique challenges, such as prohibitive computation burden caused by high spatiotemporal resolutions, irregular acquisition times, and complex spatiotemporal interactions, leading to highly-specialized neural network architectures for SITS analysis. Despite the promising results achieved by some pioneering work, we argue that satisfactory representation learning paradigms have not yet been established for SITS analysis, causing an isolated island where transferring successful paradigms or the latest advances from Computer Vision (CV) to SITS is arduous. In this paper, we develop a unique perspective of SITS processing as a direct set prediction problem, inspired by the recent trend in adopting query-based transformer decoders to streamline the object detection or image segmentation pipeline, and further propose to decompose the representation learning process of SITS into three explicit steps: collect--update--distribute, which is computationally efficient and suits for irregularly-sampled and asynchronous temporal observations. Facilitated by the unique reformulation and effective feature extraction framework proposed, our models pre-trained on pixel-set format input and then fine-tuned on downstream dense prediction tasks by simply appending a commonly-used segmentation network have attained new state-of-the-art (SoTA) results on PASTIS dataset compared to bespoke neural architectures such as U-TAE. Furthermore, the clear separation, conceptually and practically, between temporal and spatial components in the panoptic segmentation pipeline of SITS allows us to leverage the recent advances in CV, such as Mask2Former, a universal segmentation architecture, resulting in a noticeable 8.8 points increase in PQ compared to the best score reported so far.