 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstBERT: Enabling Language Model for Code Understanding with Abstract Syntax Tree
Jan 20, 2022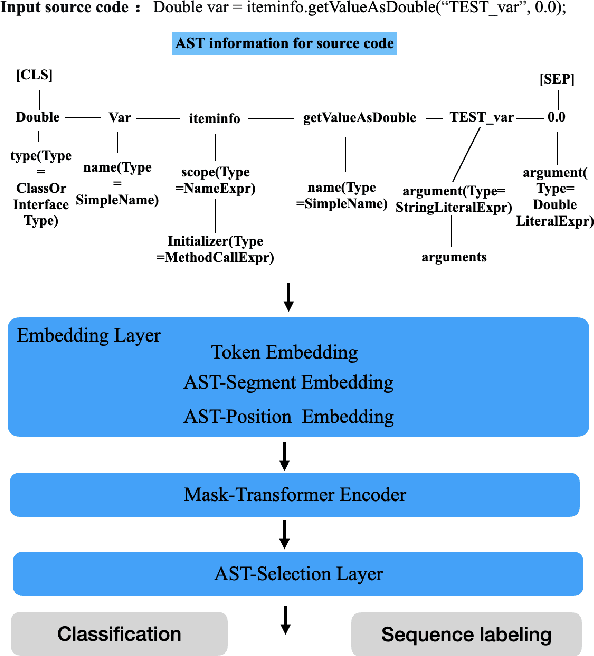


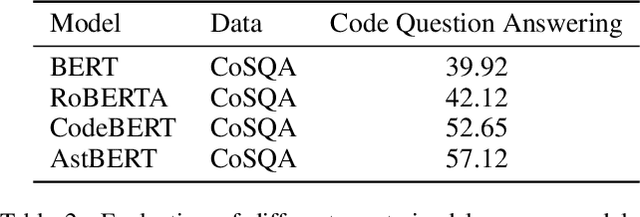
Using a pre-trained language model (i.e. BERT) to apprehend source codes has attracted increasing attention in the natural language processing community. However, there are several challenges when it comes to applying these language models to solve programming language (PL) related problems directly, the significant one of which is the lack of domain knowledge issue that substantially deteriorates the model's performance. To this end, we propose the AstBERT model, a pre-trained language model aiming to better understand the PL using the abstract syntax tree (AST). Specifically, we collect a colossal amount of source codes (both java and python) from GitHub and incorporate the contextual code knowledge into our model through the help of code parsers, in which AST information of the source codes can be interpreted and integrated. We verify the performance of the proposed model on code information extraction and code search tasks, respectively. Experiment results show that our AstBERT model achieves state-of-the-art performance on both downstream tasks (with 96.4% for code information extraction task, and 57.12% for code search task).